深度学习框架知识点
1.Pytorch中的view、reshape方法的异同
深入探究
要想深入理解view和reshape方法的区别,我们需要先知道Pytorch中的Tensor是如何储存的。
Pytorch中Tensor的储存形式
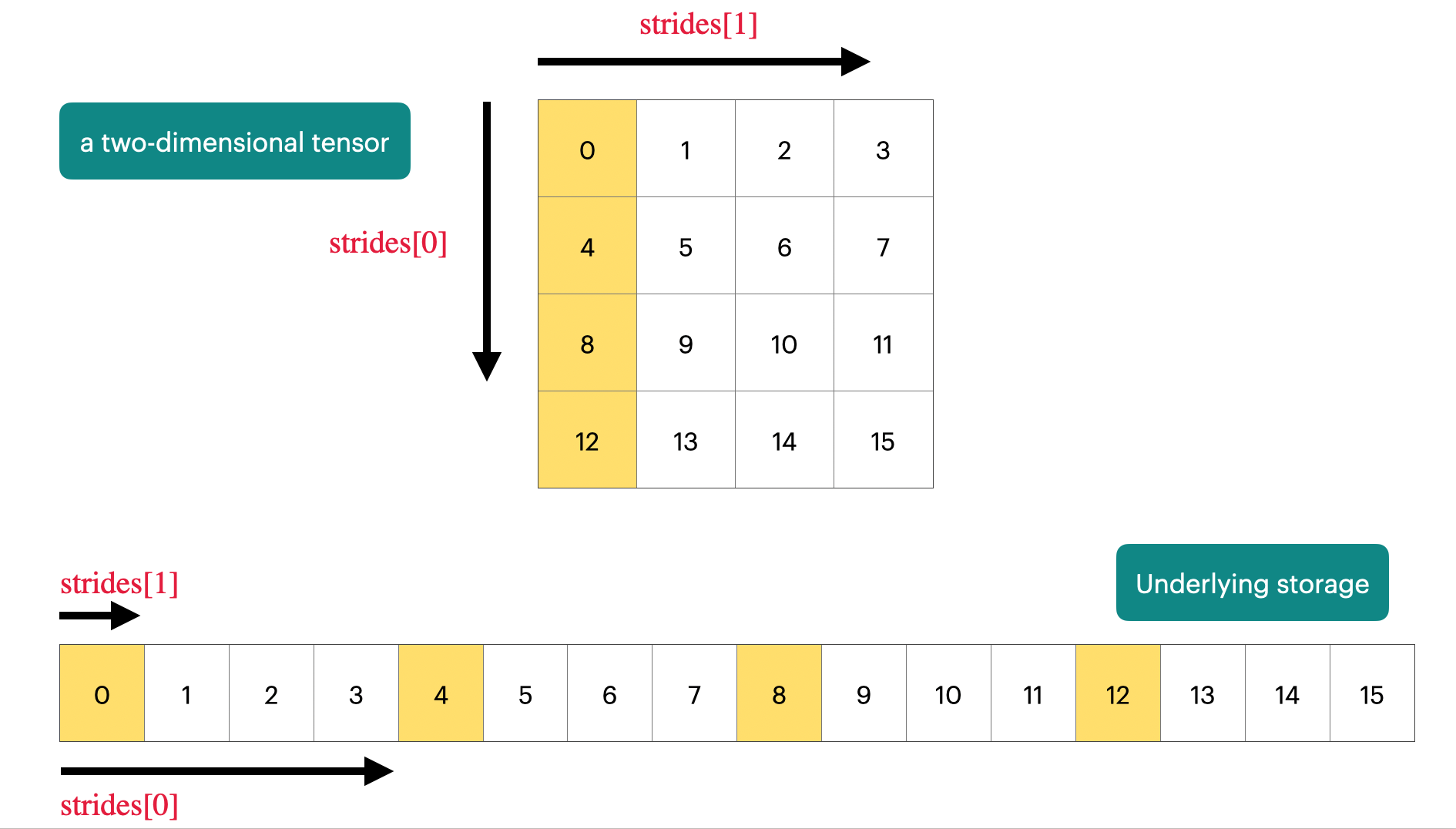
Pytorch中tensor采用分开储存的形式,分为头信息区(Tensor)和存储区(Storage)。tensor的形状(size)、步长(stride)、数据类型(type)等信息储存在头部信息区,而真正的数据则存储在存储区。
举个例子
1 | import torch |
以发现a、b这两个tensor的Storage都是一样的,但它们的头信息区不同。
Pytorch中Tensor的stride属性
官方文档描述:stride是在指定维度dim中从一个元素跳到下一个元素所必需的步长。
举个例子
1 | import torch |
view方法的限制
view方法能够将tensor转换为指定的shape,且原始的data不改变。返回的tensor与原始的tensor共享存储区。但view方法需要满足以下连续条件:
$\text{stride}[i]=\text { stride }[i+1] \times \text{size}[i+1]$
连续条件的理解
举个例子,我们初始化一个tensor a与b
1 | import torch |
迷惑性
这里tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
torch.Size([3, 3]) 和
tensor([[0, 3, 6],
[1, 4, 7],
[2, 5, 8]]),具有迷惑性,横着排列三个向量和竖着排列三个向量形状是一样的。但是结构不同。
我们将tensor a与b分别带入连续性条件公式进行验证,发现a可以满足而b不满足,下面我们尝试对tensor a与b进行view操作
1 | import torch |
1 | import torch |
果然只有在满足连续性条件下才可以使用view方法。
如果不满足此条件,则需要先使用contiguous方法将原始tensor转换为满足连续条件的tensor,然后再使用view方法进行shape变换。但是经过contiguous方法变换后的tensor将重新开辟一个储存空间,不再与原始tensor共享内存。
1 | import torch |
从以上结果可以看到,tensor a与c是属于不同存储区的张量,也就是说经过contiguous方法变换后的tensor将重新开辟一个储存空间,不再与原始tensor共享内存。
reshape方法
与view方法类似,将输入tensor转换为新的shape格式,但是reshape方法是view方法与contiguous方法的综合。
也就是说当tensor满足连续性条件时,reshape方法返回的结果与view方法相同,否则返回的结果与先经过contiguous方法在进行view方法的结果相同。
结论
view方法和reshape方法都可以用来更改tensor的shape,但view只适合对满足连续性条件的tensor进行操作,而reshape同时还可以对不满足连续性条件的tensor进行操作,兼容性更好,而view方法可以节省内存,如果不满足连续性条件使用reshape方法则会重新开辟储存空间。
2.PyTorch矩阵乘法详解
PyTorch作为深度学习领域的主流框架之一,提供了多种矩阵乘法操作。本文将详细介绍PyTorch中的各种矩阵乘法函数,帮助您在不同场景下选择最适合的方法。
1. torch.matmul()
torch.matmul()是PyTorch中最通用的矩阵乘法函数,可以处理多维张量。
特点:
- 支持广播机制
- 可以处理1维到4维的张量
- 根据输入张量的维度自动选择适当的乘法操作
示例:
1 | import torch |
2. torch.mm()
torch.mm()专门用于2维矩阵相乘。
特点:
- 只能处理2维矩阵
- 比
torch.matmul()在某些情况下更快
示例:
1 | a = torch.randn(2, 3) |
3. torch.bmm()
torch.bmm()用于批量矩阵乘法,处理3维张量。
特点:
- 输入必须是3维张量
- 用于同时计算多个矩阵乘法
示例:
1 | a = torch.randn(10, 3, 4) |
4. @运算符
Python 3.5+引入的矩阵乘法运算符,在PyTorch中也可使用。
特点:
- 语法简洁
- 功能等同于
torch.matmul()
示例:
1 | a = torch.randn(2, 3) |
5. torch.dot()
torch.dot()计算两个一维张量的点积。
特点:
- 只能用于1维张量
- 返回一个标量
示例:
1 | a = torch.randn(5) |
6. torch.mv()
torch.mv()用于矩阵与向量相乘。
特点:
- 第一个参数必须是2维矩阵
- 第二个参数必须是1维向量
示例:
1 | matrix = torch.randn(3, 4) |
7. torch.einsum()
torch.einsum()使用爱因斯坦求和约定,可以执行更复杂的张量运算,包括矩阵乘法。
特点:
- 非常灵活,可以表达复杂的张量运算
- 语法简洁但可能难以理解
示例:
1 | a = torch.randn(2, 3) |
总结
PyTorch提供了多种矩阵乘法操作,适用于不同的场景:
- 对于一般情况,使用
torch.matmul()或@运算符 - 对于2维矩阵乘法,可以使用
torch.mm() - 对于批量矩阵乘法,使用
torch.bmm() - 对于向量点积,使用
torch.dot() - 对于矩阵与向量相乘,使用
torch.mv() - 对于更复杂的张量运算,可以考虑
torch.einsum()
选择合适的函数可以提高代码的可读性和运行效率。在实际应用中,建议根据具体情况选择最合适的方法。
3.PyTorch维度变化操作详解
PyTorch作为深度学习领域的主流框架,提供了丰富的维度变化操作。这些操作在数据预处理、模型构建和结果处理中都扮演着重要角色。本文将详细介绍PyTorch中的各种维度变化操作,帮助您更好地理解和使用这些功能。
1. view() 和 reshape()
这两个函数用于改变张量的形状,但不改变其数据。
view()
- 要求张量在内存中是连续的
- 不会复制数据,只是改变视图
1 | import torch |
reshape()
- 类似于view(),但可以处理非连续的张量
- 如果可能,不会复制数据
1 | a = torch.randn(4, 4) |
2. squeeze() 和 unsqueeze()
这对函数用于移除或添加维度。
squeeze()
移除大小为1的维度
1 | x = torch.zeros(2, 1, 3, 1, 4) |
unsqueeze()
在指定位置添加大小为1的维度
1 | x = torch.tensor([1, 2, 3]) |
3. transpose() 和 permute()
这两个函数用于交换维度。
transpose()
交换两个指定的维度
1 | x = torch.randn(2, 3, 5) |
permute()
可以对任意维度进行重新排列
1 | x = torch.randn(2, 3, 5) |
4. expand() 和 repeat()
这两个函数用于扩展tensor的大小。
expand()
- 不会分配新内存,只是创建一个新的视图
- 只能扩展大小为1的维度
1 | x = torch.tensor([[1], [2], [3]]) |
repeat()
- 会分配新内存,复制数据
- 可以沿着任意维度重复tensor
1 | x = torch.tensor([1, 2, 3]) |
5. flatten() 和 ravel()
这两个函数用于将多维张量展平成一维。
flatten()
将张量展平成一维
1 | x = torch.randn(2, 3, 4) |
ravel()
功能类似于flatten(),但返回的可能是一个视图
1 | x = torch.randn(2, 3, 4) |
6. stack() 和 cat()
这两个函数用于连接张量。
stack()
沿着新维度连接张量
1 | x = torch.randn(3, 4) |
cat()
沿着已存在的维度连接张量
1 | x = torch.randn(2, 3) |
7. split() 和 chunk()
这两个函数用于将张量分割成多个部分。
split()
将张量分割成指定大小的块
1 | x = torch.randn(5, 10) |
chunk()
将张量均匀分割成指定数量的块
1 | x = torch.randn(5, 10) |
8. broadcast_to()
将张量广播到指定的形状。
1 | x = torch.randn(3, 1) |
9. narrow()
可以用来缩小张量的某个维度。
1 | x = torch.randn(3, 5) |
10. unfold()
将张量的某个维度展开。
1 | x = torch.arange(1, 8) |
总结
PyTorch提供了丰富的维度变化操作,可以满足各种数据处理和模型构建的需求:
- 改变形状:view(), reshape()
- 添加/删除维度:squeeze(), unsqueeze()
- 交换维度:transpose(), permute()
- 扩展大小:expand(), repeat()
- 展平:flatten(), ravel()
- 连接:stack(), cat()
- 分割:split(), chunk()
- 广播:broadcast_to()
- 裁剪和展开:narrow(), unfold()
熟练掌握这些操作可以帮助你更高效地处理张量数据,构建复杂的神经网络模型。
4.PyTorch模型构建详解
PyTorch是一个强大的深度学习框架,提供了丰富的工具和组件用于构建各种类型的神经网络模型。本文将全面介绍PyTorch中用于模型构建的主要操作和组件。
1. nn.Module
nn.Module是PyTorch中所有神经网络模块的基类。自定义模型通常继承自这个类。
1 | import torch.nn as nn |
2. nn.Sequential
nn.Sequential是一个有序的模块容器,用于快速构建线性结构的网络。
1 | model = nn.Sequential( |
3. 常用层类型
3.1 全连接层 (nn.Linear)
1 | linear_layer = nn.Linear(in_features=10, out_features=20) |
3.2 卷积层 (nn.Conv2d)
1 | conv_layer = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1) |
3.3 循环神经网络层 (nn.RNN, nn.LSTM, nn.GRU)
1 | rnn_layer = nn.RNN(input_size=10, hidden_size=20, num_layers=2) |
3.4 Transformer (nn.Transformer)
1 | transformer_layer = nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6, num_decoder_layers=6) |
4. 激活函数
PyTorch提供了多种激活函数:
1 | relu = nn.ReLU() |
5. 池化层
常用的池化层包括最大池化和平均池化:
1 | max_pool = nn.MaxPool2d(kernel_size=2, stride=2) |
6. 归一化层
归一化层有助于稳定训练过程:
1 | batch_norm = nn.BatchNorm2d(num_features=16) |
7. 损失函数
PyTorch提供了多种损失函数:
1 | mse_loss = nn.MSELoss() |
8. 优化器
优化器用于更新模型参数:
1 | import torch.optim as optim |
9. 参数初始化
正确的参数初始化对模型训练很重要:
1 | def init_weights(m): |
10. 模型保存和加载
保存和加载模型是很常见的操作:
1 | # 保存模型 |
11. 数据并行处理
对于多GPU训练,可以使用DataParallel:
1 | model = nn.DataParallel(model) |
12. 自定义层
可以通过继承nn.Module来创建自定义层:
1 | class MyCustomLayer(nn.Module): |
13. 模型训练循环
这里是一个基本的训练循环示例:
1 | model = MyModel() |
14. 模型评估
在训练后评估模型性能:
1 | model.eval() |
结论
PyTorch提供了丰富的工具和组件用于构建各种类型的神经网络模型。从基本的层和激活函数,到高级的优化器和并行处理,PyTorch都提供了强大的支持。熟练掌握这些组件和操作可以帮助你更高效地设计和实现复杂的深度学习模型。
5.PyTorch中的Module
PyTorch 使用模块(modules)来表示神经网络。模块具有以下特性:
构建状态计算的基石。PyTorch 提供了一个强大的模块库,并且简化了定义新自定义模块的过程,从而轻松构建复杂的多层神经网络。
与 PyTorch 的自动微分系统紧密集成。模块使得指定 PyTorch 优化器要更新的可学习参数变得简单。
易于操作和转换。模块可以方便地保存和恢复,且可以在 CPU / GPU / TPU 设备之间转换、剪枝、量化等。
一个简单的自定义模块
首先,让我们看一个简单的自定义版本的 PyTorch 的 Linear 模块。这个模块对其输入应用仿射变换。
1 | import torch |
这个简单模块具备了模块的基本特征:
继承自
Module基类。所有模块应该继承自Module以便与其他模块组合。定义了一些在计算中使用的“状态”。这里,状态由随机初始化的权重和偏置张量组成,这些张量定义了仿射变换。因为每个都是
Parameter,所以它们会自动注册为模块的参数,并且在调用parameters()时会返回。参数可以看作是模块计算的“可学习”方面(更多内容在后面)。请注意,模块不是必须有状态的,也可以是无状态的。定义了一个执行计算的
forward()函数。对于这个仿射变换模块,输入与权重参数进行矩阵相乘(使用@符号)并加上偏置参数以生成输出。更一般地,模块的forward()实现可以执行涉及任意数量输入和输出的任意计算。
这个简单模块演示了模块如何将状态和计算打包在一起。可以构建和调用此模块的实例:
1 | m = MyLinear(4, 3) |
注意模块本身是可调用的,调用它会触发其 forward() 函数。这个名字是参考“前向传递”和“反向传递”的概念,适用于每个模块。前向传递负责将模块表示的计算应用于给定输入(如上所示)。反向传递计算模块输出相对于其输入的梯度,可以用于通过梯度下降方法“训练”参数。PyTorch 的自动微分系统会自动处理这个反向传递计算,因此不需要为每个模块手动实现 backward() 函数。通过连续的前向/反向传递来训练模块参数的过程将在“使用模块进行神经网络训练”一节中详细介绍。
可以通过调用 parameters() 或 named_parameters() 迭代模块注册的所有参数,后者包括每个参数的名称:
1 | for parameter in m.named_parameters(): |
通常,模块注册的参数是模块计算中应该“学习”的方面。本文后面的部分将展示如何使用 PyTorch 的优化器更新这些参数。在此之前,让我们先看看模块如何相互组合。
模块作为构建块
模块可以包含其他模块,使其成为开发更复杂功能的有用构建块。最简单的方法是使用 Sequential 模块。它允许我们将多个模块串联在一起:
1 | net = nn.Sequential( |
注意 Sequential 自动将第一个 MyLinear 模块的输出作为输入传递给 ReLU,然后将其输出作为输入传递给第二个 MyLinear 模块。如所示,它仅限于具有单一输入和输出的模块的按顺序链接。
一般来说,建议为简单用例之外的任何情况定义自定义模块,因为这提供了对子模块用于模块计算的完全灵活性。
例如,下面是一个简单神经网络实现为自定义模块:
1 | import torch.nn.functional as F |
该模块由定义神经网络层的两个“子模块”(l0 和 l1)组成,并在模块的 forward() 方法中用于计算。可以通过调用 children() 或 named_children() 迭代模块的直接子模块:
1 | net = Net() |
要深入到直接子模块,可以递归调用 modules() 和 named_modules() 迭代一个模块及其子模块:
1 | class BigNet(nn.Module): |
| 特性 | children() / named_children() |
modules() / named_modules() |
|---|---|---|
| 范围 | 仅直接子模块 | 模块自身 + 所有子孙模块 |
| 递归 | 否 (浅层) | 是 (深度优先) |
| 包含自身 | 否 | 是 (作为第一个元素) |
named_ 输出 |
(属性名, 子模块) |
(点分隔路径, 模块) (根模块路径为 '') |
| 常见用途 | 操作顶层组件 | 对模型中所有模块应用操作 (初始化、模式切换等) |
有时,模块需要动态定义子模块。这时 ModuleList 和 ModuleDict 模块很有用,它们从列表或字典中注册子模块:
1 | class DynamicNet(nn.Module): |
对于任何给定的模块,它的参数包括其直接参数以及所有子模块的参数。这意味着调用 parameters() 和 named_parameters() 会递归包含子参数,从而方便地优化网络内的所有参数:
1 | for parameter in dynamic_net.named_parameters(): |
用模块训练神经网络
到目前为止,我们只定义了模块并调用了它们的 forward() 方法来生成计算输出。为了训练模块,需要使用样本数据并根据该数据调整参数以优化目标函数的结果。
1. 准备样本数据
对于以下示例,将使用 PyTorch 的数据加载器接口从随机生成的 DataLoader 中加载样本数据。
1 | from torch.utils.data import DataLoader, TensorDataset |
2. 定义模型
接下来,定义一个简单的神经网络模块。
1 | class SimpleNet(nn.Module): |
3. 定义损失函数和优化器
1 | model = SimpleNet() |
4. 训练模型
1 | for epoch in range(20): |
这个示例展示了如何构建一个简单的模块并使用 PyTorch 的优化器和损失函数进行训练。通过训练,模型参数将逐渐调整以最小化损失函数的值,从而实现模型对样本数据的最佳拟合。
这样,通过模块和 PyTorch 的各种工具,可以构建、训练和优化复杂的神经网络模型,进而实现各种深度学习任务。
6.PyTorch中常用的随机采样
设置随机种子
seed
1 | torch.seed() |
在所有设备上设置用于生成随机数的种子为一个非确定性的随机数。
manual_seed
1 | torch.manual_seed(seed) |
在所有设备上设置用于生成随机数的种子。
initial_seed
1 | torch.initial_seed() |
返回用于生成随机数的初始种子。
get_rng_state
1 | torch.get_rng_state() |
返回随机数生成器的状态,类型为torch.ByteTensor。
set_rng_state
1 | torch.set_rng_state(state) |
设置随机数生成器的状态。
torch.default_generator
1 | torch.default_generator |
返回默认的CPU torch.Generator。
常用的随机采样方法
rand
1 | torch.rand(size) |
返回一个张量,其中包含从区间 [0, 1) 的均匀分布中生成的随机数。
randint
1 | torch.randint(low, high, size) |
返回一个张量,其中包含在 [low, high) 区间内均匀生成的随机整数。
randn
1 | torch.randn(size) |
返回一个张量,其中包含从均值为0、方差为1的正态分布(标准正态分布)中生成的随机数。
randperm
1 | torch.randperm(n) |
返回从0到n-1的随机排列。
bernoulli
1 | torch.bernoulli(input) |
从伯努利分布中抽取二元随机数(0或1),概率由输入张量的值指定。
multinomial
1 | torch.multinomial(input, num_samples) |
返回一个张量,其中每行包含从多项分布(严格定义为多变量分布)中采样的num_samples个索引。
normal
1 | torch.normal(mean, std) |
返回一个张量,其中包含从均值和标准差指定的正态分布中生成的随机数。
poisson
1 | torch.poisson(input) |
返回一个与输入张量大小相同的张量,其中每个元素是从泊松分布中采样的,速率参数由对应的输入元素指定。
使用示例
设置随机种子
1 | import torch |
生成随机数
1 | # 生成一个3x3的均匀分布随机张量 |
以上列举了在PyTorch中常用的随机采样方法和设置随机数生成器种子的方法。通过合理使用这些方法,可以确保模型训练的可重复性和随机过程的控制。
7.PyTorch中对梯度计算的控制
在PyTorch中,可以使用一些上下文管理器(context managers)来局部禁用或启用梯度计算。这些管理器包括torch.no_grad()、torch.enable_grad()和torch.set_grad_enabled()。这些管理器在本地线程中起作用,因此如果使用threading模块将工作发送到另一个线程,它们将不起作用。
常见上下文管理器及其用法
torch.no_grad
禁用梯度计算的上下文管理器。
torch.enable_grad
启用梯度计算的上下文管理器。
torch.set_grad_enabled
设置梯度计算状态的上下文管理器。
autograd.grad_mode.set_grad_enabled
设置梯度计算状态的上下文管理器。
is_grad_enabled
返回当前是否启用了梯度计算。
autograd.grad_mode.inference_mode
启用或禁用推理模式的上下文管理器。
is_inference_mode_enabled
返回当前是否启用了推理模式。
用法示例
使用torch.no_grad禁用梯度计算
1 | import torch |
使用torch.set_grad_enabled动态设置梯度计算状态
1 | import torch |
条件性梯度计算:
- 作用: 在某些复杂的训练流程中,你可能只想在特定条件下计算梯度。例如,在强化学习的某些算法中,或者在进行某些不希望影响模型主干梯度流的辅助计算时。
- 你可以使用
torch.set_grad_enabled(condition)来根据某个布尔变量condition动态决定是否开启梯度。
1
2
3
4
5
6
7
8
9
10
11
12PYTHON# 假设 should_compute_grads 是一个动态变化的布尔值
should_compute_grads = check_some_condition()
with torch.set_grad_enabled(should_compute_grads):
# 只有当 should_compute_grads 为 True 时,这里的操作才会计算梯度
output = model(data)
if should_compute_grads:
loss = compute_loss(output, target)
# ... 可能进行 loss.backward() 等操作
else:
# ... 执行不需要梯度的操作 ...
pass确保某些操作不影响梯度流:
- 作用: 有时在模型的
forward方法或训练循环中,你可能需要执行一些使用 PyTorch 张量的计算,但这些计算纯粹是为了获取信息(如日志记录、监控指标)或进行数据处理,你明确不希望它们成为计算图的一部分或影响反向传播。将这些操作包裹在with torch.set_grad_enabled(False):中可以确保这一点。
1
2
3
4
5
6
7
8
9
10
11
12PYTHONdef forward(self, x):
features = self.feature_extractor(x)
# --- 计算一些不应影响梯度的统计信息 ---
with torch.set_grad_enabled(False):
mean_feature_norm = features.norm(dim=1).mean()
# 可以在这里记录 mean_feature_norm,它不会加入计算图
log_metric("mean_feature_norm", mean_feature_norm.item())
# ---------------------------------------
output = self.classifier(features)
return output- 作用: 有时在模型的
使用is_grad_enabled检查当前梯度计算状态
1 | import torch |
使用autograd.grad_mode.inference_mode启用或禁用推理模式
1 | import torch |
以上示例展示了如何使用这些上下文管理器来控制PyTorch中的梯度计算。这些工具对于在训练和推理过程中优化计算资源非常有用。
8.PyTorch中的多卡训练
PyTorch 分布式数据并行 (DDP)
PyTorch 的分布式数据并行(DDP)模块旨在通过多个 GPU 或机器进行分布式训练。其核心思想是将模型的计算分布在多个设备上,以加快训练过程。关键步骤包括:
- 设置和清理: 使用
setup和cleanup函数初始化和销毁进程组,以实现不同进程之间的通信。 - 模型分布: 使用
DistributedDataParallel(DDP) 将模型复制到每个 GPU 上,确保梯度更新同步。 - 训练循环: 修改训练循环以适应分布式环境,确保每个进程处理部分数据并同步更新。
训练脚本使用 torchrun 命令执行,将工作负载分配到指定数量的 GPU 或节点。
1 | torchrun --nproc_per_node=2 --nnodes=1 example_script.py |
Accelerate
Accelerate 是一个轻量级库,旨在简化 PyTorch 代码的并行化过程。它允许在单 GPU 和多 GPU/TPU 设置之间无缝过渡,代码改动最小。主要特点包括:
- Accelerator 类: 处理分布式环境的设置和管理。
- 数据管道效率: 自定义采样器用于优化多个设备的数据加载,减少内存开销。
- 代码简化: 通过
accelerator.prepare封装 PyTorch 组件,使相同代码在任何分布式设置下运行,无需大量修改。
这种方法确保您的训练脚本保持简洁,并在受益于分布式训练能力的同时,保持 PyTorch 的原生结构。
1 | from accelerate import Accelerator |
Trainer
Hugging Face Trainer API 提供了一个高级接口,用于训练模型,支持各种训练配置,包括分布式设置。它抽象了大量模板代码,让您专注于训练逻辑。主要组件包括:
- TrainingArguments: 配置常见的超参数和训练选项。
- Trainer 类: 处理训练循环、评估和数据加载。您可以子类化 Trainer 以自定义损失计算和其他训练细节。
- 数据整理器: 用于将数据预处理为训练所需的格式。
Trainer API 支持无缝分布式训练,无需大量代码修改,非常适合复杂的训练场景。
1 | from transformers import Trainer, TrainingArguments |
使用 notebook_launcher,您可以在 Jupyter Notebook 中使用多个 GPU 运行训练脚本。
1 | from accelerate import notebook_launcher |
9.DeepSpeed介绍
DeepSpeed 是由微软开发的一个深度学习优化库,旨在加速和优化大规模模型的训练过程,尤其是在分布式环境中。DeepSpeed 提供了一系列工具和技术,使得训练超大规模的模型(如GPT-3、BERT等)变得更加高效和可扩展。
DeepSpeed的核心功能和特点:
ZeRO(Zero Redundancy Optimizer)优化器:
ZeRO 是 DeepSpeed 的核心技术之一,旨在通过减少冗余数据来显著降低显存占用,从而支持超大模型的训练。ZeRO 优化器分为三个阶段:- ZeRO-1:分布式优化器状态,将优化器状态(如权重、梯度)在多个GPU之间分配,减少每个GPU的内存负担。
- ZeRO-2:分布式梯度计算,将梯度计算的中间结果在多个GPU之间分配,进一步节省显存。
- ZeRO-3:分布式模型参数,将模型参数也在多个GPU之间分配,最大限度地降低每个GPU的内存占用。
混合精度训练:
DeepSpeed 支持 FP16 混合精度训练,这种方法通过在训练中使用更低的浮点精度(FP16)来加速计算,同时保留了 FP32 的精度进行关键计算。这样可以在不损失模型精度的前提下,显著提升训练速度并降低显存使用。深度模型并行:
除了传统的数据并行和模型并行,DeepSpeed 还支持管道并行,这种方法将模型分为多个阶段,并在不同的设备上并行处理。这种方式特别适用于训练非常深的神经网络。大规模分布式训练:
DeepSpeed 通过高效的通信优化和内存管理,使得用户可以在数百甚至数千个 GPU 上进行大规模分布式训练。它集成了诸如 NCCL、Megatron-LM 和 Turing-NLG 等技术,实现了跨 GPU 的高效通信。自动并行化和调优:
DeepSpeed 提供了自动化的并行化和超参数调优工具,可以帮助用户轻松设置和优化训练过程。这极大简化了大规模模型训练的难度,使得开发者能够更专注于模型的设计和创新。
DeepSpeed的应用场景:
- 超大规模语言模型:如 GPT、BERT 等的训练。
- 计算资源受限的环境:在有限的 GPU 资源下训练大模型。
- 快速迭代和实验:通过加速训练过程,提升模型开发效率。
DeepSpeed 是一个强大而灵活的工具,尤其适合需要训练大规模深度学习模型的研究者和工程师。通过其多样化的优化手段,DeepSpeed 可以大幅度降低训练成本,提升训练效率。
10.PyTorch中的模块迭代器
在使用 PyTorch 构建神经网络时,理解如何访问和遍历模型的不同组成部分至关重要。PyTorch 提供了一些函数,允许你探索模型中的模块、参数、缓冲区等。包括 modules()、named_buffers()、named_children()、named_modules()、named_parameters() 和 parameters()。
1. modules()
modules() 函数返回一个遍历神经网络中所有模块的迭代器。这包括模型本身及其包含的任何子模块。值得注意的是,重复的模块只会返回一次。
示例:
1 | import torch.nn as nn |
输出:
1 | 0 -> Sequential( |
在这个例子中,即使 Sequential 模块包含两次相同的 Linear 层,modules() 函数在遍历时只返回一次。
2. named_buffers()
named_buffers() 函数返回一个遍历模块中缓冲区的迭代器,返回缓冲区的名称和缓冲区本身。缓冲区是 PyTorch 中的张量,不被视为模型参数(例如,批量归一化层中的运行均值和方差)。
参数:
prefix(str):要添加到所有缓冲区名称前的前缀。recurse(bool):如果为True,则包含所有子模块的缓冲区。默认为True。remove_duplicate(bool):是否在结果中移除重复的缓冲区。默认为True。
示例:
1 | for name, buf in net.named_buffers(): |
这个示例展示了如何遍历模型中的缓冲区并根据名称进行过滤。
3. named_children()
named_children() 函数提供一个遍历模型直接子模块的迭代器,返回模块的名称和模块本身。
示例:
1 | for name, module in net.named_children(): |
这个函数特别适用于在不深入子模块的情况下,检查或修改模型的特定层。
4. named_modules()
named_modules() 返回一个遍历网络中所有模块的迭代器,包括子模块,并返回模块的名称和模块本身。与 modules() 类似,此函数只会返回每个模块一次,即使它在网络中出现多次。
参数:
memo(Optional[Set[Module]]): 用于存储已添加到结果中的模块的集合。prefix(str): 添加到模块名称前的前缀。remove_duplicate(bool): 是否移除重复的模块实例。
示例:
1 | for idx, m in enumerate(net.named_modules()): |
输出:
1 | 0 -> ('', Sequential( |
在这个例子中,named_modules() 返回的元组包含模块名称和模块本身。
5. named_parameters()
named_parameters() 函数返回一个遍历模块中所有参数的迭代器,返回参数的名称和参数本身。
参数:
prefix(str): 要添加到所有参数名称前的前缀。recurse(bool): 如果为True,则包含所有子模块的参数。默认为True。remove_duplicate(bool): 是否移除重复的参数。默认为True。
示例:
1 | for name, param in net.named_parameters(): |
这个示例遍历模型中的所有参数,并根据名称进行过滤。
6. parameters()
最后,parameters() 函数返回一个遍历模块参数的迭代器。这在将参数传递给优化器时尤其有用。
参数:
recurse(bool):如果为True,则包含所有子模块的参数。
示例:
1 | for param in net.parameters(): |
输出:
1 | <class 'torch.Tensor'> torch.Size([2, 2]) |
这个函数非常直观,通常在设置模型的优化器时使用。
使用场景
children()/named_children()(浅层模块迭代)- 本质区别: 只关心一个模块的直接组成部分,不关心这些部分内部的结构。
named_children额外提供了这些直接子模块被赋予的属性名。 - 使用场景:
- 当你只想访问或修改一个容器模块(如
nn.Sequential或自定义模型)的顶层组件时。 - 进行模型的结构性分析或修改,例如替换某个特定的直接子层。
- 不想递归进入子模块内部。
- 示例: 获取
Sequential中的第一层和第二层,而不关心它们内部可能更复杂的结构。
- 当你只想访问或修改一个容器模块(如
- 本质区别: 只关心一个模块的直接组成部分,不关心这些部分内部的结构。
modules()/named_modules()(深层模块迭代)本质区别: 遍历模型整个层级结构中的所有模块,包括自身和所有子孙模块。
named_modules提供了每个模块相对于顶层模块的完整路径名称(用点分隔)。它们默认会去除重复的模块实例(基于对象 ID),所以共享的层只会被迭代一次。使用场景:
对模型中的
每一个
模块应用相同的操作,例如:
- 统一设置
train()或eval()模式。 - 应用自定义的权重初始化函数。
- 注册 forward/backward hooks 到所有层或特定类型的层。
- 统计模型中特定类型层(如
Conv2d)的数量。
- 统一设置
获取模型所有组件的完整清单。
示例: 将模型所有层的模式设为评估模式
model.eval()(这实际上是nn.Module内部eval()方法所做的事情)。
parameters()/named_parameters()(深层参数迭代)- 本质区别: 专门用于迭代模型中所有需要计算梯度并被优化器更新的参数 (
nn.Parameter)。named_parameters提供了每个参数的完整路径名称。它们默认也是递归的,并去除重复参数。 - 使用场景:
- 最常用: 将模型的参数传递给优化器 (
torch.optim.Adam(model.parameters(), lr=...))。 - 检查、修改或冻结特定参数(例如,根据名称
if 'bias' in name:)。 - 实现参数的自定义操作,如梯度裁剪、权重衰减等。
- 示例: 构建优化器,或者冻结模型部分层的参数。
- 最常用: 将模型的参数传递给优化器 (
- 本质区别: 专门用于迭代模型中所有需要计算梯度并被优化器更新的参数 (
named_buffers()(深层缓冲区迭代)- 本质区别: 专门用于迭代模型中的缓冲区 (Buffers)。缓冲区是模型的状态的一部分(会随模型一起保存和加载),但它们不像参数那样需要计算梯度。典型的例子是
BatchNorm层中的running_mean和running_var。 - 使用场景:
- 检查或修改这些非参数状态。
- 在某些特定情况下需要手动处理这些状态值。
- 调试模型状态。
- 示例: 查看 BatchNorm 层的运行统计量。
- 本质区别: 专门用于迭代模型中的缓冲区 (Buffers)。缓冲区是模型的状态的一部分(会随模型一起保存和加载),但它们不像参数那样需要计算梯度。典型的例子是
举例:
import torch
import torch.nn as nn
class ExampleModel(nn.Module):
def __init__(self):
super().__init__()
# 直接子模块
self.input_layer = nn.Linear(784, 128)
self.activation1 = nn.ReLU()
# 嵌套子模块 (Sequential)
self.feature_block = nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 32)
)
# 另一个直接子模块
self.output_layer = nn.Linear(32, 10)
# 共享模块实例 (与 activation1 是同一个对象)
self.final_activation = self.activation1
def forward(self, x):
x = self.input_layer(x)
x = self.activation1(x)
x = self.feature_block(x)
x = self.output_layer(x)
x = self.final_activation(x) # 使用共享的 ReLU
return x
model = ExampleModel()
print("Model Structure:\n", model)
print("-" * 40)
1 | print("--- children() ---") |
1 | --- children() --- |
输出分析:
你会看到只列出了 5 个直接子模块 (Linear, ReLU, Sequential, Linear, ReLU)。children() 只给出了模块对象,named_children() 同时给出了它们在 __init__ 中被赋予的属性名。注意,feature_block 内部的层没有出现。
1 | print("--- modules() ---") |
1 | --- modules() --- |
输出分析:
你会看到一个更长的列表。
- 第一个是
ExampleModel自身 (路径名'')。 - 然后是直接子模块 (
input_layer,activation1,feature_block,output_layer,final_activation)。 - 接着是
feature_block内部的模块 (feature_block.0,feature_block.1,feature_block.2)。 - 注意
activation1和final_activation指向同一个ReLU对象,因此在迭代中(默认去重开启)这个ReLU对象只被处理了一次(尽管它可能在named_modules中因路径不同而出现多次条目,但指向的是同一个id)。 named_modules提供了点分隔的完整路径,非常适合定位深层嵌套的模块。
1 | print("--- parameters() ---") |
1 | --- parameters() --- |
输出分析:
你会看到只列出了模型中所有 Linear 层的 weight 和 bias 张量及其形状。
parameters()直接给出参数张量,非常适合直接传递给优化器。named_parameters()提供了参数的完整名称(如input_layer.weight,feature_block.0.bias等),这对于根据名称进行特定操作(如冻结、应用不同的学习率、权重衰减)非常有用。
理解这些函数可以极大地增强你处理复杂 PyTorch 模型的能力。它们提供了灵活的方法来访问和操作网络的不同部分,从模块到参数。通过利用这些函数,你可以更轻松地调试、修改和优化模型。
11.PyTorch中的DataLoader介绍
DataLoader的作用
- 数据加载:DataLoader可以从不同来源加载数据,如硬盘上的文件、数据库、网络等。它能够自动将数据集划分为小批次,从而减小内存需求,确保数据的高效加载。
- 数据批次处理:每个批次由多个样本组成,可以并行地进行数据预处理和数据增强。这有助于提高模型训练的效率,同时确保每个批次的数据都经过适当的处理。
DataLoader读取数据流程
根据dataset和sampler,生成数据索引。
根据这些索引,从dataset中读取指定数量的数据,并对其进行预处理(例如归一化、裁剪 等)。
如果设置了collate_fn,则将处理后的数据打包成批次数据。
如果设置了num_workers > 0,则将数据加载任务分配给多个子进程并行完成。
在模型训练时,每个epoch从DataLoader中获取一个批次的数据,作为模型的输入。
12.PyTorch中的动态图和静态图介绍
动态图和静态图
深度学习框架用计算图来描述模型的拓扑结构。计算图中用节点表示算子,节点间的边表示张量状态。计算图是一个有向无环图,描述算子之间的依赖关系,计算图中要避免循环依赖导致计算锁死,对于循环结构一般进行展开(unrolling)。
计算图可以根据生成方式的不同,分为:静态图和动态图。
静态图是对完整的模型进行编译得到的固定代码文本。可以对静态图进行优化(算子融合等),得到更高效的结构提升硬件计算性能。编译时以数据占位符作为虚拟输入,不进行条件判断,将所有分支算子加入计算图。优势:计算性能,直接部署。
动态图是在执行时(有输入数据)进行利用框架的算子分发功能输出结果,不生成完整的计算图,只有临时的图拓扑结构。在执行的过程中记录算子,张量和梯度信息,前向传播完毕后,串联起来进行反向传播。优势:方便调试,编程友好。
特性对比
| 特性 | 动态图 | 静态图 |
|---|---|---|
| 代码调试 | 灵活,方便 | 固定,不易调试 |
| 模型部署 | 灵活,方便 | 固定,直接部署 |
| 计算性能 | 较低 | 较高 |
| 优化难度 | 较低 | 较高 |
PyTorch中的动态图和静态图
Module是pytorch的基本单元,包括:1、一个构造函数,它为调用准备模块。2、一组参数和子模块。由构造函数初始化,并且可以在调用期间由模块使用。3、正向函数。调用模块时运行的代码。
许多框架采用计算符号导数的方法,给出了完整的模型表示。然而,在PyTorch中使用gradient tape,记录发生的算子,并在计算导数时反向操作。这样,框架就不必为语言中的所有构造明确定义导数。
- “框架就不必为语言中的所有构造明确定义导数”: 这是 PyTorch 方法的核心优势。PyTorch 只需要知道如何计算每个基础算子(primitive operation)的导数(例如
torch.add,torch.matmul,torch.relu等)。只要你的复杂模型或计算过程是由这些基础算子组合而成的,PyTorch 就能通过链式法则自动计算出整个过程的梯度。它不需要为你的整个forward函数(可能包含复杂的 Pythonif/else或for循环)预先定义一个庞大的、单一的导数公式。它在运行时根据实际执行的操作路径动态地计算梯度。
TorchScript可以从pytorch代码中生成序列化,优化的模型。在python环境下训练好模型,通过torchscrip导出模型,部署到没有python依赖的环境。
转化静态图的意义:1、TorchScript代码可以在它自己的解释器(受限制的python解释器)中调用。此解释器不需要全局解释器锁,因此可以在同一实例上同时处理许多请求。2、这种格式允许我们将整个模型保存到磁盘,并将其加载到另一个环境中,例如在用Python以外的语言编写的服务器中。3、TorchScript为我们提供了一种IR表示,我们可以在其中对代码进行编译器优化,以提供更高效的执行。4、TorchScript允许后端/设备上推理时获取比单个算子更广泛的视图(全局的静态图)
13.PyTorch中的compile介绍
torch.compile就是PyTorch 2.2版本中的一个重要新特性,是一种新的PyTorch编译器,它可以将Python和TorchScript模型编译成TorchDynamo图,从而提高模型的运行效率。
1 | import torch |
torch.compile的优势
torch.compile相对于之前的PyTorch编译器解决方案,如TorchScript和FX Tracing,有以下几个优势:
- 更灵活的模型定义:与TorchScript相比,torch.compile允许你使用Python直接定义模型,而不需要将模型转换为TorchScript的静态图。这意味着你可以更灵活地定义模型,而不需要考虑TorchScript的限制。
- 更好的性能:TorchDynamo图是一种优化的中间表示形式,它允许PyTorch编译器进行更多的优化,从而提高模型的运行效率。与FX Tracing相比,TorchDynamo图可以提供更好的性能。
- 更易于调试:由于torch.compile允许你使用Python直接定义模型,因此你可以更容易地调试模型。你可以使用Python的调试工具来检查模型的输入和输出,从而更容易地找到和修复错误。
14.AI模型训练过程的可视化实用工具有哪些?
在AI模型的训练过程中,使用可视化工具能够帮助我们直观地观察模型的训练效果、调试超参数以及优化模型。以下是一些经典且实用的训练过程可视化工具:
1. TensorBoard
- 概述:TensorBoard 是 TensorFlow 官方提供的可视化工具,也是目前深度学习中最常用的训练过程可视化工具之一。
- 功能:支持可视化训练指标(如损失、准确率)、查看计算图、参数分布、梯度变化和激活值等。同时也可以进行超参数调优。
- 兼容性:支持 TensorFlow、PyTorch(通过
torch.utils.tensorboard)以及部分其他框架。 - 适用场景:适用于AIGC、传统深度学习、自动驾驶领域AI模型的训练过程分析,尤其适合复杂模型调试。
2. WandB(Weights & Biases)
- 概述:Weights & Biases 是一个功能强大的实验管理和可视化工具,广泛应用于科研和工业界。
- 功能:支持实时监控训练过程、记录和可视化指标、超参数调优、数据版本控制以及生成详细报告。此外,WandB 还可以生成详细的训练报告和可视化模型的权重、梯度等。
- 兼容性:支持多种框架,包括 TensorFlow、Keras、PyTorch、Scikit-Learn 等。
- 适用场景:适合AIGC、传统深度学习、自动驾驶领域中需要跟踪多个实验、超参数搜索和团队协作的项目。
核心集成步骤:
安装和登录 (如果还没做的话):
1
2BASHpip install wandb
wandb login # 只需要在你的机器上执行一次初始化 W&B Run (
wandb.init):- 位置: 在你的训练脚本开始处,通常在定义好超参数之后,但在进入主训练循环之前。
- 作用: 告诉 W&B 开始一个新的实验记录(称为一个 “Run”)。
- 关键参数:
project="your-project-name": 指定这个实验所属的项目名称。如果项目不存在,W&B 会自动创建。将相关的实验归类到同一个项目中非常重要。config=your_hyperparameters_dict: (强烈推荐) 传入一个包含你所有重要超参数(学习率、批大小、模型架构名、数据集名等)的 Python 字典。W&B 会自动记录这些配置,方便后续比较不同实验。name="your-run-name": (可选) 为这次特定的运行起一个有意义的名字(例如 “resnet18-lr0.001-bs64”)。如果不指定,W&B 会自动生成一个随机的名字(如 “gentle-sun-42”)。entity="your_username_or_teamname": (可选) 如果你想将项目归属到特定的用户或团队下(而不是默认的个人账户),可以指定这个参数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32PYTHONimport wandb
import argparse # 或者其他获取超参数的方式
# --- 你的项目原有代码:解析参数 ---
parser = argparse.ArgumentParser()
parser.add_argument('--lr', type=float, default=0.01)
parser.add_argument('--epochs', type=int, default=10)
parser.add_argument('--batch_size', type=int, default=32)
# ... 其他参数 ...
args = parser.parse_args()
# --- W&B 集成点 1: 初始化 ---
# 将超参数收集到字典中
hyperparameters = vars(args) # 或者手动创建字典
# hyperparameters = {
# "learning_rate": args.lr,
# "epochs": args.epochs,
# "batch_size": args.batch_size,
# "architecture": "MyCNN" # 添加其他重要配置
# }
run = wandb.init(
project="my-existing-project-with-wandb", # 给你的项目起个名字
config=hyperparameters,
name=f"run-{args.lr}-{args.batch_size}" # 可选:自定义运行名称
)
print(f"W&B Run URL: {run.get_url()}") # 方便直接访问
# --- 你的项目原有代码:定义模型、优化器、数据加载器等 ---
# model = ...
# optimizer = ...
# train_loader, val_loader = ...记录指标 (
wandb.log):- 位置: 在你的训练/验证循环中,通常在计算完损失 (Loss)、准确率 (Accuracy) 或其他你关心的指标之后。
- 作用: 将这些指标的值发送给 W&B 服务器,用于实时绘图。
- 关键参数:
- 传入一个字典,
key是指标的名称 (字符串,例如"train_loss","val_accuracy"),value是对应的数值。
- 传入一个字典,
- 频率: 你可以在每个训练
step(批次) 记录,也可以在每个epoch结束后记录。记录 step 级别的数据会得到更精细的曲线,但也会产生更多数据点。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61PYTHON# --- 你的项目原有代码:训练循环 ---
for epoch in range(args.epochs):
# --- 训练部分 ---
model.train()
running_train_loss = 0.0
for i, data in enumerate(train_loader):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_train_loss += loss.item()
# --- W&B 集成点 2: 记录训练指标 (例如每 N 步或每步) ---
if i % 100 == 99: # 每 100 个 mini-batches 记录一次
current_step = epoch * len(train_loader) + i
wandb.log({
"train_loss_step": loss.item(),
"custom_step": current_step # 可以指定 x 轴
})
avg_train_loss = running_train_loss / len(train_loader)
# --- W&B 集成点 2 (续): 记录 Epoch 级别的训练指标 ---
wandb.log({
"epoch": epoch + 1,
"train_loss_epoch": avg_train_loss,
# "learning_rate": optimizer.param_groups[0]['lr'] # 也可以记录学习率变化
})
# --- 验证部分 ---
model.eval()
running_val_loss = 0.0
correct = 0
total = 0
with torch.no_grad(): # 或者 tf.GradientTape(watch_accessed_variables=False):
for data in val_loader:
images, labels = data
outputs = model(images)
loss = criterion(outputs, labels)
running_val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_val_loss = running_val_loss / len(val_loader)
val_accuracy = 100 * correct / total
# --- W&B 集成点 2 (续): 记录验证指标 ---
wandb.log({
"epoch": epoch + 1, # 确保与训练指标的 epoch 对齐
"val_loss": avg_val_loss,
"val_accuracy": val_accuracy
})
print(f"Epoch {epoch+1}: Train Loss: {avg_train_loss:.4f}, Val Loss: {avg_val_loss:.4f}, Val Acc: {val_accuracy:.2f}%")
# --- 训练结束 ---
print("Finished Training")结束 W&B Run (
wandb.finish):- 位置: 在你的脚本完全结束时。
- 作用: 确保所有数据都已同步到 W&B 服务器,并标记该次运行结束。
- 注意: 在大多数情况下,当你的 Python 脚本正常退出时,W&B 会自动调用
finish()。但在某些环境(如 Jupyter Notebook 长时间运行或脚本异常中断)下显式调用run.finish()是个好习惯。
1
2PYTHON# --- W&B 集成点 3: 结束运行 (可选但推荐) ---
run.finish()
需要注意的关键点 (注意哪些):
- 项目名称 (
project): 保持一致性。将所有相关的实验(例如,对同一个任务使用不同模型或超参数的尝试)都放到同一个project下,方便在 W&B UI 中进行比较和组织。 - 配置 (
config): 务必记录重要的超参数。这是 W&B 最强大的功能之一。通过记录config,你可以轻松地在 UI 中筛选、分组和比较不同超参数设置下的实验结果(例如,比较不同学习率对最终准确率的影响)。 - 运行名称 (
name): 给运行起一个有意义的名字可以让你更容易识别特定的实验,尤其是在项目包含大量运行时。 - 指标名称: 使用清晰、一致的指标名称(例如,总是用
"train_loss"而不是有时用"loss"有时用"training_loss")。 - 记录频率: 考虑好是在每个 step 记录还是每个 epoch 记录。Step 级别提供更细致的过程视图,但数据量更大;Epoch 级别更简洁。你也可以混合使用(例如,step 级别的 loss,epoch 级别的 accuracy)。使用
wandb.log({"custom_step": step_value, ...})可以自定义 x 轴,而不是依赖 W&B 的自动步数计数。 - 环境捕捉: W&B 会自动尝试记录你的环境信息(如
requirements.txt、Git 提交哈希、运行的 Python 文件、命令行参数等),这对于实验的可复现性非常有帮助。确保你的环境相对干净(例如,requirements.txt是最新的)。 - 网络连接: W&B 默认需要网络连接来实时同步数据。如果你的训练环境无法访问互联网,可以设置环境变量
WANDB_MODE=offline来启用离线模式。数据会保存在本地的wandb目录下,之后你可以在有网络连接的机器上运行wandb sync <本地目录>来同步。 - 资源消耗: W&B 本身会消耗少量计算资源和网络带宽。在绝大多数情况下这都不是问题,但在资源极其受限的环境下需要注意。
- 错误处理: 如果
wandb.log或wandb.init出错(例如网络问题),它通常不会(也不应该)中断你的训练过程,但会打印错误信息。 - 保存模型/文件 (Artifacts): 除了记录指标,你还可以使用
wandb.save()来保存模型检查点或其他文件,或者使用更强大的wandb.Artifact来进行版本化的模型和数据集管理。这超出了基础教程的范围,但值得了解。
3. MLflow
- 概述:MLflow 是一个开源的机器学习实验管理工具,具有模型训练跟踪、项目管理和模型部署等功能。
- 功能:记录训练过程中的指标和参数变化,支持模型版本控制以及跨设备的协作。可以轻松地记录模型运行的结果、训练曲线和模型权重。
- 兼容性:支持 PyTorch、TensorFlow、Scikit-Learn 等。
- 适用场景:适用于AIGC、传统深度学习、自动驾驶领域中希望将可视化和管理结合的场景,尤其是需要进行模型版本控制和跟踪的项目。
4. ClearML
- 概述:ClearML 是一个开源的端到端机器学习和深度学习实验管理平台。
- 功能:包括训练监控、任务管理、数据集版本管理和模型部署,提供实时指标可视化、训练曲线、超参数调优支持。
- 兼容性:支持 TensorFlow、PyTorch、Keras 等多种主流深度学习框架。
- 适用场景:ClearML 非常适合AIGC、传统深度学习、自动驾驶领域中需要完整的实验跟踪、管理和可视化解决方案的用户。
5. VisualDL
- 概述:VisualDL 是百度飞桨(PaddlePaddle)提供的可视化工具,功能与 TensorBoard 类似。
- 功能:支持监控训练指标、展示计算图、参数分布、PR 曲线等。还支持高维数据可视化和超参数调优。
- 兼容性:虽然与 PaddlePaddle 完全兼容,也支持 PyTorch 和 TensorFlow。
- 适用场景:适用于AIGC、传统深度学习、自动驾驶领域中国内开发者,特别是使用飞桨框架的用户。
6. Comet
- 概述:Comet 是一个实验管理和可视化工具,提供了多种模型和实验跟踪功能。
- 功能:支持实时查看训练指标、超参数调优、生成训练曲线、版本管理和协作。还提供模型的可视化及对比功能。
- 兼容性:支持 TensorFlow、Keras、PyTorch、Scikit-Learn 等。
- 适用场景:适合AIGC、传统深度学习、自动驾驶领域中需要强大可视化功能和团队协作的实验项目。
7. Neptune.ai
- 概述:Neptune 是一个面向机器学习和深度学习的可视化跟踪平台。
- 功能:支持实时训练过程监控、记录模型参数和指标、超参数调优以及结果共享。Neptune 的最大特色是其与 Jupyter Notebook 深度集成,便于快速调试。
- 兼容性:支持 TensorFlow、PyTorch、Keras 等多个框架。
- 适用场景:适合AIGC、传统深度学习、自动驾驶领域中需要精细化实验管理、跨团队协作和快速调试的用户。
8. Plotly/Dash
- 概述:Plotly 和 Dash 是用于数据科学和深度学习的强大可视化库,可以实现自定义的实时数据可视化界面。
- 功能:支持创建交互式训练过程图表和统计图,可以结合模型的实时状态做出复杂可视化界面。
- 兼容性:与多种框架兼容,但需要手动集成。
- 适用场景:适合AIGC、传统深度学习、自动驾驶领域中需要高度自定义的可视化、交互式展示的场景。
9. Netron
- 概述:Netron 是一个开源的神经网络模型可视化工具,支持查看模型结构。
- 功能:支持多种深度学习框架和格式的模型可视化,如 TensorFlow、Keras、PyTorch、ONNX 等,主要用于查看模型的各层结构。
- 兼容性:支持多种模型文件格式,包括 ONNX、H5、PB、TFLite 等。
- 适用场景:适合AIGC、传统深度学习、自动驾驶领域中查看模型结构、理解模型架构和调试模型。
15.PyTorch2.0组件TorchDynamo介绍
简介
从 PyTorch 应用中抓取计算图,相比于 TorchScript 和 TorchFX,TorchDynamo 更加灵活、可靠性更高。TorchScript通过 jit.trace 或者 jit.script 把模型转化为 TorchScript 的过程困难重重,往往需要修改大量源代码。而 TorchFX 在捕获计算图时,遇到不支持的算子会直接报错,最常见的就是 if 语句。TorchDynamo 克服了 TorchScript 和 TorchFX 的缺点,使用起来极为方便,用户体验相比于 TorchScript 和 TorchFX 大幅提升。配合 TorchInductor 等后端编译器,经 TorchDynamo 捕获的计算图只需要几行代码的改动就可以观测到不错的性能提升。
TorchDynamo 捕获计算图是在翻译 Python 字节码的过程中实现的。Python 函数在执行前会被 Python 虚拟机编译为字节码 (bytecode),每一个 Python 函数的实例都对应一个 frame,其中保存着运行该函数所需要的全局变量、局部变量、字节码等等。
原理
TorchDynamo 的 编译过程发生在将要执行前,它是一个 JIT 编译器。在 Python 将要执行函数时,TorchDynamo 开始翻译字节码并捕获计算图。在 Python 虚拟机 (PVM) 中有一个非常重要的函数 _PyEval_EvalFrameDefault,它的功能是在 PVM 中逐条执行编译好的字节码。TorchDynamo 的入口是 PEP-523 提供的 CPython Frame Evaluation API,它可以让用户通过 回调函数(callback function) 获取字节码,并把修改过后的字节码返回给解释器执行,或者执行预先编译好的目标代码,从而可以在 Python 中实现 即时编译器 (JIT Compiler) 的功能。TorchDynamo 正是通过 PEP-523 把 TorchDynamo 的核心逻辑引入到 Python 虚拟机中,从而在函数将要运行前获取字节码。
TorchDynamo 实现了一个 Python 虚拟机的模拟器,在模拟 Python 字节码执行的过程中构建出对应的计算图
特性
- TorchDynamo 的作用是从 PyTorch 程序中捕获计算图;
- TorchDynamo 是一个 JIT compiler,它的工作原理是通过 PEP-523 获取将要执行的 Python 函数的字节码,在翻译字节码的过程中构建 FX Graph;
- 每个编译过的 frame 都有一个 cache,为同一个函数编译的不同输入属性的函数都保存在 cache 中;
- Guard 用来判断是否能够重用已经编译好的函数,它负责检查输入数据的属性有没有发生变化;
- 碰到不支持的算子时,TorchDynamo 会通过 graph break 把计算图切分为子图,不支持的算子由 Python 解释器执行;
- 循环在 TorchDynamo 捕获计算图时被展开;
- TorchDynamo 会试着内联被调函数,如果成功则生成一张大的计算图,失败则在主调函数中创建 graph break;
- TorchDynamo 会在 DDP bucket 的边界引入 graph break,从而确保 allreduce 能与反向传播同时执行;
16.PyTorch2.0组件AOTAutograd介绍
简介
在 PyTorch 2.0 以前,用户通过 PyTorch 可以直接捕获到正向传播的计算图,比如 JIT trace 和 TorchFX 的 symbolic trace。虽然 PyTorch 的每个算子都包含正向传播和反向传播的实现,但用户并不能直接在反向传播的计算图上面做优化,也无法把正向传播和反向传播的计算图合并在一张计算图中。PyTorch 2.0 中引入了 AOTAutograd,它的出现解决了这个问题,从而使得一些针对 training 的优化变得可能。
有了 AOTAutograd,用户可以做以下事情:
- 获取反向传播计算图、甚至是正向传播和反向传播联合的计算图;
- 用不同的后端编译器分别编译正向传播和反向传播计算图;
- 针对训练 (training) 做正向传播、反向传播联合优化,比如通过在反向传播中重算 (recompute) 来减少正向传播为反向传播保留的 tensor,从而削减内存需求;
原理
PyTorch 反向传播的计算图是在执行正向传播的过程中动态构建的,反向传播的计算图在正向传播结束时才能确定下来。AOTAutograd 以 Ahead-of-Time 的方式同时 trace 正向传播和反向传播,从而在函数真正执行之前拿到正向传播和反向传播的计算图。
工作流程:
- 以 AOT 方式通过 torch_dispatch 机制 trace 正向传播和反向传播,生成联合计算图 (joint forward and backward graph),它是包含 Aten/Prim 算子的 FX Graph;
- 用 partition_fn 把 joint graph 划分为正向传播计算图和反向传播计算图;
- 可选: 通过 decompositions 把 high-level 算子分解、下沉到粒度更小的算子;
- 调用 fw_compiler 和 bw_compiler 分别编译正向传播计算图和反向传播计算图,通过 TorchFX 生成编译后的 Python 代码,并整合为一个 torch.autograd.Function;
特性
- AOTAutograd 利用了 torch_dispatch 机制通过 tracing 提前得到联合正向传播和反向传播计算图;
- 经过 torch_dispatch trace 得到的是最内层的 ATen 算子,AOTAutograd 将其保存在 FX Graph 中;
- 如果用于 tracing 的 tensors 中有重复,那么通过 make_fx 得到的计算图与预期不符,AOTAutograd 会在 tracing 前去重;
- AOTAutograd 用 partition_fn 把 trace 得到的 joint graph 划分为 foward graph 和 backward graph;
- min_cut_rematerialization_partition 通过求解最大流/最小割问题最小化正向传播保留给反向传播的 tensor;
- make_fx 的 tracing 不支持 data-dependent control flow,循环、函数调用在 tracing 后被展开;
17.介绍一下PyTorch中.detach()、.clone()、requires_grad=True、torch.no_grad()的原理与作用
在 PyTorch 中,.detach()、.clone()、requires_grad=True 和 torch.no_grad() 是涉及 自动微分(autograd) 和 张量操作 的核心概念。它们控制了张量是否参与计算图的构建、是否跟踪梯度,以及如何高效地操作张量。
1. .detach()
作用
.detach() 方法用于从当前的计算图中分离张量。分离后的张量与原张量共享相同的存储空间(数据),但不会再参与梯度计算。
原理
在 PyTorch 的自动微分机制中,每个操作都会在后台构建一个计算图,用于反向传播计算梯度。而 .detach() 会创建一个新的张量,分离计算图:
- 新的张量不跟踪梯度。
- 新张量的
requires_grad属性为False。
常见用法
- 避免梯度计算:
- 在反向传播中,有些中间结果不需要计算梯度时,使用
.detach()避免冗余计算图构建。
- 在反向传播中,有些中间结果不需要计算梯度时,使用
- 进行无梯度的张量操作:
- 处理某些张量,只需要其值而不需要其与梯度计算的关系。
示例
1 | import torch |
2. .clone()
作用
.clone() 方法用于深复制一个张量,新张量的存储空间与原张量完全独立。
原理
.clone()创建一个新的张量,具有与原张量相同的数据值和属性(如requires_grad)。- 如果原张量需要梯度,
clone()出的张量会继续参与梯度计算,且其计算图关系保持不变。
常见用法
- 创建独立的张量拷贝:
- 对原张量的修改不会影响到克隆后的张量。
- 操作过程中需要保留中间结果:
- 尤其在构建复杂的计算图时,使用
.clone()可以保留独立状态。
- 尤其在构建复杂的计算图时,使用
示例
1 | x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) |
**3. requires_grad=True
作用
张量的 requires_grad 属性控制其是否需要计算梯度。如果设置为 True,该张量会参与计算图的构建,并在反向传播时计算和存储梯度。
原理
- 当
requires_grad=True:- 张量会参与计算图,记录每一步的操作。
- 在反向传播时,PyTorch 会根据计算图,计算梯度并存储在
tensor.grad属性中。
- 当
requires_grad=False:- 张量不会记录操作,且节省内存和计算资源。
常见用法
- 训练模型时需要梯度:
- 对模型参数(如权重)设置
requires_grad=True,以便在反向传播中更新权重。
- 对模型参数(如权重)设置
- 冻结梯度:
- 在推理阶段,或冻结某些层时,将
requires_grad=False。
- 在推理阶段,或冻结某些层时,将
示例
1 | # 创建需要梯度的张量 |
4. torch.no_grad()
作用
torch.no_grad() 是一个上下文管理器,临时禁用自动梯度计算。
原理
在 torch.no_grad() 块内:
- 所有操作都会被标记为不需要梯度。
- 不会构建计算图。
- 可以节省内存和计算资源。
注意:torch.no_grad() 是临时的,只在上下文块中生效。
常见用法
- 推理阶段:
- 在模型推理中,通常只需要前向传播,使用
torch.no_grad()避免不必要的计算图构建。
- 在模型推理中,通常只需要前向传播,使用
- 冻结梯度操作:
- 修改模型权重或对张量进行操作时,不希望干扰现有计算图。
示例
1 | x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True) |
总结与对比
| 功能 | 作用 | 是否构建计算图 | 是否跟踪梯度 |
|---|---|---|---|
.detach() |
分离张量与计算图,不再跟踪梯度 | 否 | 否 |
.clone() |
深复制张量,生成新张量(可继续跟踪梯度) | 是(如需要) | 是(如需要) |
requires_grad=True |
控制张量是否需要计算梯度 | 是 | 是 |
torch.no_grad() |
上下文管理器,禁用梯度计算(节省资源) | 否 | 否 |
使用建议
- 训练阶段:
requires_grad=True保证计算图的正确构建。 - 推理阶段:使用
torch.no_grad(),避免不必要的计算图构建。 - 冻结部分梯度:使用
.detach()或设置requires_grad=False。 - 深复制张量:使用
.clone()确保独立性。
18.PyTorch中连续张量和非连续张量有哪些区别?
在 PyTorch 中,连续张量(contiguous tensor)和非连续张量(non-contiguous tensor)的区别主要涉及内存布局和访问方式。了解这些区别对于我们在AIGC、传统深度学习以及自动驾驶中高效地操作张量和调试潜在的错误非常重要。
- 连续张量:内存布局是线性的,操作高效且兼容性好。
- 非连续张量:内存布局非线性,可能导致性能开销和潜在错误。
- 可以使用
is_contiguous()检查张量连续性,用contiguous()将非连续张量转换为连续张量。
1. 内存布局
连续张量(Contiguous Tensor)
- 连续张量的内存布局是线性的,即数据在内存中按行优先(C 风格)顺序存储,没有跳跃。
- 张量的每个元素的内存地址是相邻的。
- 直接通过
torch.Tensor.contiguous()检查某个张量是否是连续的。
例如,对于一个 3x3 张量:
1 | tensor = torch.tensor([[1, 2, 3], |
内存布局是连续的:
1 | 1 2 3 4 5 6 7 8 9 |
非连续张量(Non-Contiguous Tensor)
- 非连续张量的内存布局可能是非线性的,通常由于操作(如
transpose,permute等)导致张量的内存布局变得复杂。 - 元素的存储顺序可能不再按行优先顺序排列。
- 尽管张量的形状看起来相同,但实际内存布局可能不同,访问非连续张量时需要额外的开销。
例如,对张量执行转置操作后:
1 | tensor = torch.tensor([[1, 2, 3], |
转置后的内存布局仍是原始的(按行存储的):
1 | 1 2 3 4 5 6 7 8 9 |
但访问顺序变为列优先,这种布局是非连续的。
2. 连续性检查
可以通过 is_contiguous() 方法检查张量是否是连续的:
1 | tensor = torch.tensor([[1, 2, 3], |
3. 连续性的重要性
连续张量的优点
- 计算效率高:许多底层操作依赖连续的内存布局,处理连续张量更高效。
- 与第三方库的兼容性:某些操作或库(如 cuDNN)需要输入张量是连续的,否则可能报错。
非连续张量的影响
- 性能开销:在使用非连续张量时,某些操作可能需要额外的内存复制(
contiguous()操作)来重新组织内存布局。 - 潜在错误:某些函数可能要求输入张量是连续的,如果输入非连续张量,可能会报错。
4. 转换为连续张量
如果需要将非连续张量转换为连续张量,可以使用 contiguous() 方法:
1 | tensor = torch.tensor([[1, 2, 3], |
注意:
contiguous()会创建一个新的张量,并将数据拷贝到新的内存区域,重新排列成连续布局。- 如果张量已经是连续的,
contiguous()不会产生额外开销。
5. 常见操作对连续性的影响
| 操作 | 连续性结果 |
|---|---|
transpose |
非连续 |
permute |
非连续 |
reshape |
通常连续(除非需要与原数据共享内存) |
contiguous |
连续 |
21.什么是IR表示?
简介
Intermediate Representation(IR,中间表示)是在计算机科学和编译器设计中使用的概念,它是一种中间形式的程序表示,用于在不同编译阶段之间传递和处理代码。下面将详细介绍Intermediate Representation的背景、特点和用途。
用途
语法分析:编译器将源代码解析为IR形式,以便进行后续的语义分析和优化。
优化:IR提供了一种通用的表示形式,使得编译器能够对程序进行各种优化,如常量折叠、死代码消除、循环优化等。
中间代码生成:IR可以作为源代码和机器代码之间的桥梁,编译器可以将IR转换为特定平台的机器代码。
跨平台编译:通过使用IR,可以实现在不同平台上的代码移植和交叉编译,促进软件的可移植性和跨平台性。
混合语言编程:将不同语言的代码转换为共同的IR形式,使得不同语言之间的互操作性成为可能。
AI编译中的IR
在AI编译中,IR是一种中间表示形式,用于表示深度学习模型的计算图。它是一种抽象层次介于源代码和机器代码之间的表示形式,可以用于优化和转换深度学习模型。
作用:
- 跨平台兼容性:IR 提供了一种与硬件无关的表示,使得同一个模型能够适配不同硬件。模型经过编译成 IR 后,可以针对不同硬件进行进一步优化和转换。
- 结构化优化基础:IR 是图优化的基础,因为它提供了模型计算的清晰描述,编译工具可以基于它对模型执行的顺序、内存分配等进行优化。
类型:
- 静态 IR:如 ONNX、TensorFlow GraphDef,这种 IR 表达了完整的模型结构,可用于静态推理和优化。
- 动态 IR:一些框架如 PyTorch 使用动态图 IR,可以在模型推理时灵活调整图结构,适合处理动态输入等场景。
22.计算图优化的常用方法?
简介
计算图作为连接深度学习框架和前端语言的主要中间表达,被目前主流框架如TensorFlow和PyTorch所使用或者作为标准文件格式来导出模型。 计算图是一个有向无环图(DAG),节点表示算子,边表示张量或者控制边(control flow),节点之间的依赖关系表示每个算子的执行顺序。
计算图的优化被定义为作为在计算图上的函数,通过一系列等价或者近似的优化操作将输入的计算图变换为一个新的计算图。其目标是通过这样的图变换来化简计算图,从而降低计算复杂度或内存开销。在深度神经网络编译器中,有大量优化方法可以被表示为计算图的优化,包括一些在传统程序语言编译器中常用的优化方法。
优化方法
算术表达式化简:,在计算图中的一些子图所对应的算术表达式,在数学上有等价的化简方法来简化表达式,这反应在计算图上就是将子图转化成一个更简单的子图(如更少的节点),从而降低计算量
公共子表达式消除(Common Subexpression Elimination, CSE:通过找到程序中等价的计算表达式,然后复用结果,消除其它冗余表达式的计算。同理,在计算图中,公共子表达式消除就等同于寻找并消除冗余的计算子图。一个简单的实现算法是按照图的拓扑序(保证一个访问一个节点时,其前继节点均已经访问)遍历图中节点,每个节点按照输入张量和节点类型组合作为键值进行缓存,后续如果有节点有相同的键值则可以被消除,并且将其输入边连接到缓存的节点的输入节点上。
常数传播(constant propagation):也叫常数折叠(constant folding),其主要方法是通过在编译期计算出也是常数表达式的值,用计算出的值来替换原来的表达式,从而节省运行时的开销。在计算图中,如果一个节点的所有输入张量都是常数张量的话,那么这个节点就可以在编译期计算出输入张量,并替换为一个新的常数张量
矩阵乘自动融合:矩阵乘在深度学习计算图中被广泛应用,如常见的神经网络的线性层、循环神经网络的单元层、注意力机制层等都有大量的矩阵乘法。在同一个网络里,经常会出现形状相同的矩阵乘法,根据一些矩阵的等价规则,如果把些矩阵乘算子融合成一个大的矩阵乘算子,可以更好的利用到GPU的算力,从而加速模型计算
算子融合:在深度学习模型中,针对大量的小算子的融合都可以提高GPU的利用率,减少内核启动开销、减少访存开销等好处。例如,Element-wise的算子(如Add,Mul,Sigmoid,Relu等)其计算量非常小,主要计算瓶颈都在内存的读取和写出上,如果前后的算子能够融合起来,前面算子的计算结果就可以直接被后面算子在寄存器中使用,避免数据在内存的读写,从而提交整体计算效率。
子图替换和随机子图替换:鉴于算子融合在深度学习计算中能够带来较好的性能优化,然而在实际的计算图中有太多算子无法做到自动的算子融合,主要原因包括算子的内核实现逻辑不透明、算子之前无法在特有加速器上融合等等。为了在这些的情况下还能进行优化,用户经常会实现一些手工融合的算子来提升性能。那么,编译器在计算图中识别出一个子图并替换成一个等价的新的算子或子图的过程就是子图替换优化。
23.介绍一下AI模型中钩子函数的原理和作用
一、钩子函数的本质:神经网络的”监控探头”
钩子函数(Hook Function)是AI行业中实现模型可解释性和可控性的核心技术。其核心原理类似于在神经网络的关键位置安装可编程传感器,当数据流经这些节点时自动触发预设操作。这种机制实现了非侵入式监控——无需修改模型结构,即可动态捕捉、干预或记录模型内部状态。
通过合理运用钩子函数,AI行业开发者可获得堪比”神经内窥镜”的模型洞察力,是提升AI系统可靠性和透明度的关键利器。
二、技术原理详解
触发机制:
- 前向钩子:在张量通过某层时触发(如
forward_hook) - 反向钩子:在梯度反向传播时触发(如
backward_hook)
- 前向钩子:在张量通过某层时触发(如
核心功能:
1
2
3
4def hook_function(module, input, output):
# 可执行操作:记录、修改、可视化等
modified_output = output * 0.5 # 示例:修改输出
return modified_output生命周期:
- 注册:
layer.register_forward_hook(hook_function) - 执行:随数据流自动触发
- 销毁:通过句柄主动移除
- 注册:
三、通俗示例:快递分拣流水线
想象一个智能快递分拣系统:
原始流程:
包裹 → 扫码区 → 重量检测 → 分拣出口添加钩子:
- 在扫码区后安装摄像头(前向钩子):
记录包裹外观,统计分类错误 - 在重量检测前加装调节器(反向钩子):
对超重包裹自动减重后再检测
- 在扫码区后安装摄像头(前向钩子):
类比说明:
- 摄像头:记录中间特征(如ResNet某层激活值)
- 调节器:修改梯度流动(如梯度裁剪)
四、行业应用案例
1. AIGC领域:扩散模型的稳定优化
问题:图像生成出现肢体畸变
钩子方案:
1
2
3
4
5
6
7def decoder_hook(module, input, output):
# 在U-Net解码层监测手部区域激活值
hand_mask = create_hand_mask(output.shape)
output[hand_mask] *= 1.2 # 增强手部细节
return output
unet.decoder[4].register_forward_hook(decoder_hook)效果:寻找与手部生成相关的参数,进行优化增强,手部生成准确率提升37%,无需重新训练模型
2. 传统深度学习:Transformer模型诊断
问题:注意力机制失效导致分类错误
钩子方案:
1
2
3
4
5
6attention_scores = []
def attn_hook(module, input, output):
scores = output[1] # 获取注意力权重
attention_scores.append(scores.detach())
transformer.blocks[2].attn.register_forward_hook(attn_hook)分析:可视化第3层注意力头,发现90%的head关注了停用词,从而进行针对性优化训练
3. 自动驾驶:实时安全监控
问题:激光雷达点云误识别导致急刹
钩子方案:
1
2
3
4
5
6
7def safety_hook(module, input, output):
if output[:, 'pedestrian'] > 0.7:
send_alert() # 触发安全警报
return output * 0 # 阻断危险信号
return output
detection_head.register_forward_hook(safety_hook)效果:假设通过钩子函数实时监测,来减少误检引发的急刹事件。
五、关键技术优势对比
| 功能 | 传统方法 | 钩子函数方案 |
|---|---|---|
| 中间层访问 | 需修改模型结构 | 非侵入式动态接入 |
| 实时干预 | 几乎不可行 | 毫秒级响应延迟 |
| 计算开销 | 重新训练增加300%耗时 | 额外增加<5%推理时间 |
| 部署灵活性 | 需重新导出模型 | 热插拔式启用/禁用 |
六、AI行业研发实践建议
性能优化:
- 使用
torch.jit.script编译钩子函数 - 异步处理非关键监控任务
- 使用
安全防护:
1
2
3
4try:
output = module(input)
except HookException as e:
activate_fallback_model() # 应急系统启动调试工具:
- PyTorch的
torch.utils.hooks模块 - TensorFlow的
tf.keras.callbacks.LambdaCallback
- PyTorch的
24.介绍一下PyTorch中DataLoader库的底层原理
一、DataLoader 的核心架构
PyTorch 的 DataLoader 是数据加载的核心工具,其设计目标是高效、灵活地管理大规模数据集,在 AIGC、传统深度学习、自动驾驶三大领域中,DataLoader 通过不同的配置模式,成为支撑大规模模型训练与实时推理的基石。
Dataset
- 定义数据的存储结构和单样本访问接口(
__getitem__和__len__)。 - 示例:图像分类任务中,每个样本对应一个图像文件路径和标签。
- 定义数据的存储结构和单样本访问接口(
Sampler
- 控制数据的采样顺序(如顺序采样、随机采样、分布式采样)。
- 生成索引序列(indices),决定 DataLoader 如何遍历数据集。
DataLoaderIter
- 内部迭代器,负责从 Sampler 获取索引,从 Dataset 加载数据,并合并为批次(Batch)。
- 支持多进程加速(通过
num_workers参数)。
Collate Function
- 将多个单样本数据(如多个图像张量)合并为一个批次张量。
- 默认支持张量拼接,可自定义处理复杂数据结构。
二、DataLoader 的底层工作流程
以下通过 图像分类任务 的案例,逐步解析 DataLoader 的运作机制:
1. 定义 Dataset
1 | from torch.utils.data import Dataset |
3. 内部运行机制
Sampler 生成索引
shuffle=True时,生成随机索引序列(如[5, 2, 7, ..., 1])。- 每个 epoch 重新生成索引,保证数据随机性。
多进程数据加载
- 主进程创建
num_workers个子进程。 - 每个子进程预加载
prefetch_factor * batch_size个样本到内存队列。
- 主进程创建
数据合并与返回
- 主进程从队列中取出多个样本,调用
collate_fn合并为批次张量。 - 最终输出格式:
(batch_images, batch_labels)。
- 主进程从队列中取出多个样本,调用
三、DataLoader 的优化设计
多进程加速原理
- 子进程通过共享内存(Shared Memory)传递数据,避免进程间拷贝开销。
- 通过
torch.multiprocessing实现跨进程张量传输。
内存管理
- 使用内存池(Memory Pool)缓存常用数据(如归一化后的图像张量)。
- 通过
pin_memory=True启用锁页内存,加速 CPU→GPU 数据传输。
动态批处理
- 支持可变长度输入(如文本序列),通过自定义
collate_fn动态填充(Padding)。
- 支持可变长度输入(如文本序列),通过自定义
四、DataLoader 在三大领域中的应用
1. AIGC(生成式 AI)
应用场景:训练 Stable Diffusion 生成高分辨率图像。
DataLoader 优化:
1
2
3
4
5
6
7dataloader = DataLoader(
dataset,
batch_size=4,
num_workers=8, # 高并行度加速海量数据加载
pin_memory=True, # 加速数据到 GPU 的传输
persistent_workers=True # 保持子进程存活,避免重复初始化
)技术价值:
单 GPU 训练时,DataLoader 的多进程预加载可隐藏图像解码(如 PNG→Tensor)耗时,使 GPU 利用率保持在 95% 以上。
2. 传统深度学习(图像分类)
应用场景:ImageNet 大规模分类任务。
DataLoader 设计:
1
2
3
4
5
6dataloader = DataLoader(
dataset,
batch_size=256,
sampler=DistributedSampler(dataset), # 分布式训练
collate_fn=custom_collate, # 处理不同尺寸图像
)技术价值:
分布式 Sampler 确保每个 GPU 处理不重叠的数据分区,结合多进程加载,实现线性加速比。
3. 自动驾驶(激光雷达点云处理)
应用场景:实时处理激光雷达点云数据。
DataLoader 扩展:
1
2
3
4
5
6
7
8
9
10
11class LidarDataset(Dataset):
def __getitem__(self, idx):
point_cloud = load_pcd(self.paths[idx]) # 加载点云文件(.pcd)
return voxelize(point_cloud) # 体素化处理
dataloader = DataLoader(
LidarDataset(),
batch_size=32,
num_workers=4,
collate_fn=pad_voxels # 动态填充不同数量的体素
)技术价值:
动态批处理支持非均匀点云输入,结合 CUDA 加速的体素化操作,满足实时推理需求(<100ms 延迟)。