模型推理与应用
1.RAG应用
1.RAG文档召回率是什么?
RAG(Retrieval-Augmented Generation)中的文档召回率(Document Recall)是指在检索阶段,模型能够成功找到与用户查询相关的所有文档的比例。具体来说,它衡量的是在所有相关文档中,有多少被成功检索到了。
文档召回率是评估检索系统性能的重要指标。它可以用以下公式计算:文档召回率=成功检索到的相关文档数量/所有相关文档数量
在RAG中,文档召回率的高低直接影响生成模型的表现。如果召回率低,生成模型可能会缺乏足够的背景信息,从而影响答案的准确性和相关性。
要提高文档召回率,可以采取以下措施:
改进检索模型:使用更先进的检索模型,如Dense Passage Retrieval (DPR) 或改进BM25算法,来提高相关文档的检索效果。
扩展检索范围:增加知识库的规模和多样性,以确保包含更多潜在相关文档。
优化检索策略:调整检索策略,使用多轮检索或结合多个检索模型的结果,来提高召回率。
高召回率可以确保生成模型有更丰富的信息源,从而提高最终生成答案的准确性和可靠性。
现代和最新的提高召回率方法 (基于深度学习和向量检索):
近年来,随着深度学习和大规模语言模型 (LLM) 的发展,文档召回技术取得了显著进步。核心思想是从基于关键词的稀疏匹配转向基于语义的稠密向量匹配。
稠密向量检索 (Dense Vector Retrieval / Semantic Search):
核心思想: 将查询和文档都映射到同一个高维向量空间 (Embedding Space),使得语义相似的文本在向量空间中距离更近。然后通过计算向量间的相似度(如余弦相似度、点积)来检索文档。
如何提高召回率:
- 语义匹配: 能够召回与查询词语不同但语义相关的文档,克服了关键词匹配的字面限制。例如,搜“如何保持健康”,能召回包含“均衡饮食和规律运动”的文档。
- 对噪声和多样表达的鲁棒性: 用户查询的措辞可能不标准或多样,语义检索能更好地理解其意图。
关键技术:
文本嵌入模型 (Text Embedding Models):
如 Word2Vec (2013), GloVe (2014) 是早期代表,但现在主流是基于 Transformer 的模型:
- Sentence-BERT (SBERT) / Sentence Transformers (2019): 专门为生成高质量句子/段落向量而设计,通过孪生网络或三元组网络在有监督或无监督数据上微调预训练的 Transformer (如 BERT, RoBERTa)。这是目前非常流行且效果显著的方法。
- SimCSE (Simple Contrastive Learning of Sentence Embeddings) (2021): 一种简单有效的对比学习方法,用于训练句子嵌入模型,取得了很好的效果。
- 通用大规模预训练模型 (如 OpenAI Ada, Cohere Embed, Google Gecko): 这些商业或开源的 LLM API 提供了强大的文本嵌入能力,可以直接使用或作为基础进行微调。
提出时间: 概念很早,但基于深度学习的稠密检索在 BERT (2018) 出现后开始大规模流行,特别是 Sentence-BERT (2019) 之后。
流行度: 极高,是当前信息检索和推荐系统领域的主流方向。
混合检索 (Hybrid Search):
- 核心思想: 结合稀疏检索 (如 BM25,基于关键词) 和 稠密向量检索 的优点。稀疏检索擅长精确匹配关键词,而稠密检索擅长捕捉语义相关性。
- 如何提高召回率: 两者互补。稀疏检索能确保包含精确关键词的文档被召回,稠密检索能召回那些语义相关但可能不包含精确关键词的文档。通过融合两者的结果(例如,使用加权组合排序分数),可以获得比单一方法更高的召回率和更好的整体性能。
- 关键技术:
- BM25 (Okapi BM25): 一种经典的基于词频和逆文档频率的排序算法,是稀疏检索的代表。 (1994 年左右提出,持续优化)
- 结果融合策略: 如 Reciprocal Rank Fusion (RRF)。
- 提出时间: 混合检索的概念不新,但基于深度学习的稠密检索与传统稀疏检索的结合是近几年的热点。
- 流行度: 非常高,被认为是当前生产环境中最实用的方案之一。
多向量检索 / 多表征检索 (Multi-Vector / Multi-Representation Retrieval):
- 核心思想: 不再为每个文档或查询只生成一个单一的稠密向量,而是生成多个向量来捕捉文档的不同方面或粒度。
- 例子:
- ColBERT (Contextualized Late Interaction over BERT) (2020): 为查询中的每个 token 和文档中的每个 token 都生成上下文相关的向量。在检索时,计算查询 token 向量与文档 token 向量之间的最大相似度之和,实现更细粒度的“词袋式”语义匹配。它在召回和排序上都表现优异。
- 为文档的不同部分(如标题、摘要、正文段落)分别生成向量。
- 使用不同的嵌入模型生成多个向量,捕捉不同语义侧面。
- 如何提高召回率: 能够从更多角度、更细粒度地匹配文档,减少因单一向量表示不足而导致的遗漏。
- 提出时间: ColBERT 是 2020 年提出的,这个方向仍在发展。
- 流行度: 越来越高,尤其是在需要高质量召回的场景。 ColBERT 是一个非常受关注的模型。
学习重排 (Learning to Rank, LTR) - 间接提高召回感知:
- 核心思想: 虽然 LTR 主要用于优化排序(提高精度),但一个好的重排模型可以更好地识别那些“勉强”被召回但实际上非常相关的文档,将它们排到更前面,从而间接提升用户感知到的“有效召回”。
- 如何工作: 在召回阶段(例如使用混合检索得到一个候选集)之后,使用一个更复杂的模型(通常是基于 Transformer 的交叉编码器,如 Cross-Encoder BERT)对候选集中的每个“查询-文档”对进行打分,然后重新排序。
- 提出时间: LTR 概念较早,但基于 Transformer 的交叉编码器用于重排是 BERT 之后发展起来的。
- 流行度: 在需要高精度排序的系统中非常流行,作为召回后的关键步骤。
总结与趋势:
- 最流行的方法:
- 稠密向量检索 (基于 Sentence-BERT 或类似模型): 因其强大的语义理解能力而成为基石。
- 混合检索 (BM25 + 稠密向量): 因其鲁棒性和互补性,在实际应用中非常受欢迎。
- 最新的趋势和方法 (仍在发展和普及中):
- 多向量/多表征检索 (如 ColBERT): 提供更细粒度的匹配,有望进一步提升召回质量。 (ColBERT 2020 年)
- 利用大型语言模型 (LLM) 进行查询理解和重写: 例如,使用 LLM 将用户的自然语言查询转化为更适合检索的结构化查询或关键词组合,或者生成多个子查询来覆盖不同方面。 (近 1-2 年的热点)
- 端到端的检索模型训练: 直接优化召回指标,而不是依赖预训练的嵌入模型。
- 图神经网络 (GNN) 用于文档检索: 利用文档间的引用关系、作者关系等构建图结构,辅助召回。
2.RAG技术的难点有哪些?
(1)数据处理
目前的数据文档种类多,包括doc、ppt、excel、pdf扫描版和文字版。ppt和pdf中包含大量架构图、流程图、展示图片等都比较难提取。而且抽取出来的文字信息,不完整,碎片化程度比较严重。
而且在很多时候流程图,架构图多以形状元素在PPT中呈现,光提取文字,大量潜藏的信息就完全丢失了。
(2)数据切片方式
不同文档结构影响,需要不同的切片方式,切片太大,查询精准度会降低,切片太小一段话可能被切成好几块,每一段文本包含的语义信息是不完整的。
(3)内部知识专有名词不好查询
目前较多的方式是向量查询,对于专有名词非常不友好;影响了生成向量的精准度,以及大模型输出的效果。
(4)新旧版本文档同时存在
一些技术报告可能是周期更新的,召回的文档如下就会出现前后版本。
(5)复杂逻辑推理
对于无法在某一段落中直接找到答案的,需要深层次推理的问题难度较大。
(6)金融行业公式计算
如果需要计算行业内一些专业的数据,套用公式,对RAG有很大的难度。
(7)向量检索的局限性
向量检索是基于词向量的相似度计算,如果查询语句太短词向量可能无法反映出它们的真实含义,也无法和其他相关的文档进行有效的匹配。这样就会导致向量检索的结果不准确,甚至出现一些完全不相关的内容。
(8)长文本
(9)多轮问答
3.RAG存在的一些问题和避免方式有哪些?
(1)分块(Chunking)策略以及Top-k算法
一个成熟的RAG应该支持灵活的分块,并且可以添加一点重叠以防止信息丢失。用固定的、不适合的分块策略会造成相关度下降。最好是根据文本情况去适应。
在大多数设计中,top_k是一个固定的数字。因此,如果块大小太小或块中的信息不够密集,我们可能无法从向量数据库中提取所有必要的信息。
(2)世界知识缺失
比如我们正在构建一个《西游记》的问答系统。我们已经把所有的《西游记》的故事导入到一个向量数据库中。现在,我们问它:人有几个头?
最有可能的是,系统会回答3个,因为里面提到了哪吒有“三头六臂”,也有可能会说很多个,因为孙悟空在车迟国的时候砍了很多次头。而问题的关键是小说里面不会正儿八经地去描述人有多少个头,所以RAG的数据有可能会和真实世界知识脱离。
(3)多跳问题(推理能力)
让我们考虑另一个场景:我们建立了一个基于社交媒体的RAG系统。那么我们的问题是:谁知道埃隆·马斯克?然后,系统将遍历向量数据库,提取埃隆·马斯克的联系人列表。由于chunk大小和top_k的限制,我们可以预期列表是不完整的;然而,从功能上讲,它是有效的。
现在,如果我们重新思考这个问题:除了艾梅柏·希尔德,谁能把约翰尼·德普介绍给伊隆·马斯克?单次信息检索无法回答这类问题。这种类型的问题被称为多跳问答。解决这个问题的一个方法是:
找回埃隆·马斯克的所有联系人
找回约翰尼·德普的所有联系人
看看这两个结果之间是否有交集,除了艾梅柏·希尔德
如果有交集,返回结果,或者将埃隆·马斯克和约翰尼·德普的联系方式扩展到他们朋友的联系方式并再次检查。
有几种架构来适应这种复杂的算法,其中一个使用像ReACT这样复杂的prompt工程,另一个使用外部图形数据库来辅助推理。我们只需要知道这是RAG系统的限制之一。
(4)信息丢失
RAG系统中的流程链:
将文本分块(chunking)并生成块(chunk)的Embedding
通过语义相似度搜索检索数据块
根据top-k块的文本生成响应
1. 检索质量问题 (Retrieval Quality Issues):
- 问题描述:
- 低召回率 (Low Recall): 相关的文档块 (Chunks) 没有被检索到,导致 LLM 无法获取生成答案所需的信息。
- 低精确率 (Low Precision): 检索到了不相关或噪声文档块,这些无关信息可能会误导 LLM,产生错误或不相关的答案。
- 信息分散: 相关信息可能分散在多个文档块中,单个块可能不足以回答问题,需要综合多个块的信息。
- 信息冲突: 检索到的不同文档块之间可能存在信息冲突。
- 避免方式:
- 优化嵌入模型 (Embedding Model Optimization):
- 选择或微调更适合特定领域和任务的嵌入模型 (如 Sentence-BERT, SimCSE, 或特定领域的嵌入模型)。
- 考虑使用多向量检索 (如 ColBERT),它能进行更细粒度的匹配。
- 改进分块策略 (Chunking Strategy Improvement):
- 根据文档结构(如段落、标题)进行智能分块,而不是固定大小分块。
- 确保分块大小适中,既能包含足够上下文,又不会引入过多噪声。
- 考虑重叠分块 (Overlapping Chunks) 以避免关键信息在边界处被切断。
- 探索句子级分块或更细粒度的分块,并结合上下文扩展。
- 查询转换/扩展 (Query Transformation/Expansion):
- 使用 LLM 对用户原始查询进行重写、扩展或分解为多个子查询,以覆盖更多相关方面。例如,HyDE (Hypothetical Document Embeddings) 先让 LLM 生成一个假设性答案,然后用这个答案的嵌入去检索。
- 添加元数据过滤(如日期、来源)来缩小检索范围。
- 混合检索 (Hybrid Search): 结合稀疏检索 (如 BM25) 和稠密向量检索的优势,提高召回率和精确率。
- 重排阶段 (Re-ranking Stage): 在初步召回后,使用更复杂的模型 (如 Cross-Encoder) 对检索到的文档块进行重新排序,将最相关的块排在前面。
- 迭代检索 (Iterative Retrieval): 如果初步检索结果不佳,可以根据已生成的部分答案或反馈进行第二轮甚至多轮检索。
- 优化嵌入模型 (Embedding Model Optimization):
2. 生成质量问题 (Generation Quality Issues):
- 问题描述:
- 幻觉 (Hallucination): 即使提供了相关上下文,LLM 仍可能编造不实信息。
- 不忠实于上下文 (Not Faithful to Context): LLM 可能忽略或曲解检索到的上下文信息。
- 上下文整合不佳 (Poor Context Integration): LLM 可能难以流畅地将多个检索到的信息片段整合到连贯的答案中。
- 答案过于冗长或简略: LLM 未能根据上下文生成恰当长度和详略的答案。
- 避免方式:
- 优化 Prompt 工程 (Prompt Engineering Optimization):
- 设计清晰、明确的 Prompt,指导 LLM 如何使用检索到的上下文(例如,“请基于以下提供的上下文回答问题,不要使用外部知识…”)。
- 在 Prompt 中明确指示答案的格式、长度、风格等。
- 使用思维链 (Chain-of-Thought, CoT) 或类似提示技巧,引导模型进行更细致的推理。
- 选择或微调更适合的 LLM: 某些 LLM 可能更擅长遵循指令和利用上下文。可以考虑对 LLM 进行特定于 RAG 任务的微调。
- 上下文管理:
- 控制传递给 LLM 的上下文数量,避免信息过载。
- 对检索到的上下文进行预处理,如提取关键信息、摘要等。
- 事实性检查/后处理: 对 LLM 生成的答案进行事实性检查,可以利用检索到的上下文或其他外部工具。
- 迭代生成与修正: 允许用户反馈或系统自动评估,对生成的答案进行迭代修正。
- 优化 Prompt 工程 (Prompt Engineering Optimization):
3. 评估与可解释性问题 (Evaluation and Interpretability Issues):
- 问题描述:
- 难以评估端到端性能: RAG 系统涉及检索和生成两个阶段,评估整体效果比单独评估 LLM 更复杂。
- 缺乏标准化的评估指标: 除了传统的问答指标,还需要评估检索质量、答案的事实一致性等。
- 可解释性差: 难以准确判断是检索模块出了问题还是生成模块出了问题。
- 避免方式:
- 分阶段评估: 分别评估检索模块(使用召回率、精确率、MRR、NDCG 等)和生成模块(使用 BLEU、ROUGE、METEOR,以及基于模型的评估如 BERTScore,或人工评估答案的流畅性、相关性、事实性)。
- 开发针对 RAG 的评估框架: 例如 RAGAS (RAG Assessment) 框架,它包含 faithfulness, answer relevancy, context relevancy 等指标。
- 记录和分析中间结果: 保存检索到的文档块、LLM 的内部思考过程(如果可能),以便进行错误分析。
- 可追溯性 (Attribution): 要求 LLM 在生成答案时引用其使用的上下文来源,方便用户验证。
4. 效率和成本问题 (Efficiency and Cost Issues):
- 问题描述:
- 检索延迟: 向量数据库检索可能引入额外延迟。
- LLM 推理成本: 调用 LLM API 或运行本地 LLM 成本较高。
- 数据索引和更新成本: 维护和更新向量索引需要计算资源。
- 避免方式:
- 优化向量数据库: 选择高效的向量数据库和索引算法 (如 HNSW, IVFADC)。
- 缓存机制: 缓存常见的查询和检索结果。
- 模型量化与蒸馏: 使用更小、更快的嵌入模型和 LLM。
- 选择性调用 LLM: 仅在检索结果质量较高或问题复杂时才调用 LLM。
- 异步处理和流式输出: 改善用户体验。
5. 上下文窗口限制 (Context Window Limitations):
- 问题描述: 即使是 RAG,LLM 的上下文窗口仍然是有限的。如果检索到的相关信息总量超过了 LLM 的上下文窗口,仍然需要进行选择和压缩。
- 避免方式:
- 有效的上下文压缩/选择策略: 在将检索到的文档块送入 LLM 前,进行筛选、排序、摘要或选择最相关的部分。
- 使用具有更大上下文窗口的 LLM: 例如 GPT-4 Turbo (128k), Claude 3 (200k)。
- 分步处理/迭代方法: 如果需要的信息非常多,可以分步骤提问和生成。
6. 数据更新与维护 (Data Update and Maintenance):
- 问题描述: 外部知识库是动态变化的,需要定期更新 RAG 系统中的索引数据,以保证信息的时效性。
- 避免方式:
- 建立自动化的数据同步和索引更新流程。
- 版本控制: 对文档和索引进行版本管理。
- 监控数据漂移: 监控知识库内容变化对检索和生成性能的影响。
4.在大模型工程应用中RAG与LLM微调优化哪个是最优解?
RAG: 将检索(或搜索)的能力集成到LLM文本生成中,结合了检索系统(从大型语料库中获取相关文档片段)和LLM(使用这些片段中的信息生成答案)。
微调: 对预训练的LLM模型在特定数据集上进一步训练,使其适应特定任务或提高其性能的过程。
一般在工程中考虑使用RAG还是LLM需要从以下几点考虑:
(1)如果需要访问大量的外部数据,并且要实时更新。RAG系统在具有动态数据的环境中具有固有的优势。它们的检索机制不断地查询外部源,确保它们用于生成响应的信息是最新的。随着外部知识库或数据库的更新,RAG系统无缝地集成了这些更改,在不需要频繁的模型再训练的情况下保持其相关性。
(2)如果我们需要改变模型的输出风格,如我们想让模型听起来更像医学专业人士,用诗意的风格写作,或者使用特定行业的行话,那么对特定领域的数据进行微调可以让我们实现这些定制。
RAG虽然在整合外部知识方面很强大,但主要侧重于信息检索。
(3)一般来说RAG与LLM微调可以单独使用也可以组合使用。
(4)通过将模型在特定领域的数据中微调可以一定程度上减少幻觉。然而当面对不熟悉的输入时,模型仍然可能产生幻觉。相反,RAG系统天生就不容易产生幻觉,因为它们的每个反应都是基于检索到的证据。
5.基于langchain的本地文档问答系统实现步骤有哪些?
项目实现过程包括加载文件、读取文本、文本分割、文本向量化、问句向量化、在文本向量中匹配出与问句向量最相似的topk个、匹配出的文本作为上下文和问题一起添加到prompt中、提交给LLM生成回答。
前提条件:
安装 LangChain 及相关库:
1
2
3
4
5
6
7BASHpip install langchain openai chromadb tiktoken pypdf unstructured docx2txt
# openai: 如果使用 OpenAI 的模型和嵌入
# chromadb: 一个内存友好或可持久化的向量数据库
# tiktoken: OpenAI 用来计算 token 数的库
# pypdf: 用于加载 PDF 文件
# unstructured: 一个更通用的文档加载库,支持多种格式
# docx2txt: 用于加载 DOCX 文件设置 API Keys (如果使用外部服务):
1
2
3PYTHONimport os
os.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_API_KEY"
# 如果使用其他 LLM 或嵌入服务,也需要相应设置
步骤 1: 文档加载 (Document Loading)
目的: 从本地文件系统加载文档内容到 LangChain 的
Document对象中。Document对象通常包含page_content(文本内容) 和metadata(元数据,如来源文件名、页码等)。LangChain 组件:
langchain.document_loaders模块提供了多种加载器。示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31PYTHONfrom langchain.document_loaders import PyPDFLoader, TextLoader, UnstructuredFileLoader, DirectoryLoader
# 加载单个 PDF 文件
pdf_path = "path/to/your/document.pdf"
loader = PyPDFLoader(pdf_path)
# documents = loader.load() # load() 返回 Document 列表,每个元素通常代表一页
# 加载单个 TXT 文件
# txt_path = "path/to/your/document.txt"
# loader = TextLoader(txt_path, encoding='utf-8') # 注意编码
# documents = loader.load()
# 使用 UnstructuredFileLoader (支持更多格式,如 .doc, .docx, .html, .md 等)
# unstructured_path = "path/to/your/document.docx"
# loader = UnstructuredFileLoader(unstructured_path)
# documents = loader.load()
# 加载整个目录下的所有支持的文件 (例如,所有 .txt 文件)
# DirectoryLoader 需要指定 glob 模式和每个文件的加载器
directory_path = "path/to/your/docs_folder/"
# loader = DirectoryLoader(directory_path, glob="**/*.txt", loader_cls=TextLoader, show_progress=True, use_multithreading=True)
# documents = loader.load()
# 更通用的做法是针对不同文件类型使用不同的加载器,然后合并 Document 列表
# 例如,加载一个目录下的所有 PDF
pdf_loader = DirectoryLoader(directory_path, glob="**/*.pdf", loader_cls=PyPDFLoader, show_progress=True, use_multithreading=True)
documents = pdf_loader.load() # 假设我们主要处理 PDF
print(f"Loaded {len(documents)} documents (pages).")
# print(documents[0].page_content[:200]) # 查看第一个文档(页)的前200个字符
# print(documents[0].metadata)
步骤 2: 文档分割 (Text Splitting)
目的: 将加载的长文档分割成更小的、语义相关的文本块 (Chunks)。这对于后续的嵌入和检索至关重要,因为:
- 嵌入模型通常有输入长度限制。
- 更小的块能更精确地匹配查询。
- LLM 的上下文窗口有限。
LangChain 组件:
langchain.text_splitter模块。关键参数:
chunk_size: 每个块的最大字符数 (或 token 数,取决于分割器)。chunk_overlap: 相邻块之间的重叠字符数,有助于保持语义连续性,避免关键信息在边界被切断。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18PYTHONfrom langchain.text_splitter import RecursiveCharacterTextSplitter, CharacterTextSplitter
# RecursiveCharacterTextSplitter 是推荐的通用分割器
# 它会尝试按一系列分隔符(如 "\n\n", "\n", " ", "")来分割,以保持段落和句子的完整性
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个块的目标大小 (字符数)
chunk_overlap=200, # 相邻块的重叠大小
length_function=len, # 用于计算长度的函数
add_start_index=True, # 是否在元数据中添加块的起始索引
)
# CharacterTextSplitter 是更简单的按字符分割
# text_splitter = CharacterTextSplitter(separator="\n\n", chunk_size=1000, chunk_overlap=200)
chunks = text_splitter.split_documents(documents) # documents 是上一步加载的 Document 列表
print(f"Split into {len(chunks)} chunks.")
# print(chunks[0].page_content)
# print(chunks[0].metadata) # metadata 会包含来源和可能的 start_index
步骤 3: 文本嵌入 (Text Embedding)
目的: 将分割后的文本块转换为数值向量 (Embeddings)。这些向量能够捕捉文本的语义信息,使得语义相似的文本在向量空间中距离更近。
LangChain 组件:
langchain.embeddings模块。你需要选择一个嵌入模型。常见选择:
OpenAIEmbeddings: 使用 OpenAI 的嵌入模型 (如text-embedding-ada-002或更新的模型)。需要 OpenAI API Key。HuggingFaceEmbeddings: 使用 Hugging Face Hub 上的开源嵌入模型 (如sentence-transformers/all-MiniLM-L6-v2)。可以在本地运行。- 其他云服务商提供的嵌入模型 (Cohere, Google Vertex AI 等)。
示例代码 (使用 OpenAI):
1
2
3
4
5
6
7
8
9
10PYTHONfrom langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings() # 默认使用 text-embedding-ada-002
# 示例:获取单个文本块的嵌入
# sample_embedding = embeddings_model.embed_query(chunks[0].page_content)
# print(f"Embedding dimension: {len(sample_embedding)}")
# 注意:在下一步创建向量存储时,嵌入模型会作为参数传入,
# 向量存储会自动为所有块计算嵌入。示例代码 (使用 Hugging Face Sentence Transformers - 本地运行):
1
2
3
4
5
6
7
8
9
10PYTHON# from langchain.embeddings import HuggingFaceEmbeddings
# model_name = "sentence-transformers/all-MiniLM-L6-v2" # 一个流行的轻量级模型
# model_kwargs = {'device': 'cuda'} # 如果有 GPU,指定使用 GPU
# encode_kwargs = {'normalize_embeddings': False} # 是否归一化嵌入
# embeddings_model = HuggingFaceEmbeddings(
# model_name=model_name,
# model_kwargs=model_kwargs,
# encode_kwargs=encode_kwargs
# )
步骤 4: 向量存储 (Vector Storage)
目的: 将文本块的嵌入向量存储起来,并提供高效的相似性搜索功能。当用户提问时,我们会将问题也转换为向量,然后在向量数据库中查找最相似的文本块向量。
LangChain 组件:
langchain.vectorstores模块。常见选择:
Chroma: 轻量级,可以内存运行或持久化到磁盘。适合快速原型和中小型应用。FAISS: Facebook AI Similarity Search,非常高效,适合大规模向量搜索。Pinecone,Weaviate,Milvus: 托管或自建的专业向量数据库,功能更强大,适合生产环境。
示例代码 (使用 Chroma):
1
2
3
4
5
6
7
8
9
10
11
12
13
14PYTHONfrom langchain.vectorstores import Chroma
# 创建向量存储 (如果持久化,可以指定 persist_directory)
# persist_directory = "db_chroma"
vector_store = Chroma.from_documents(
documents=chunks, # 传入分割后的文本块
embedding=embeddings_model, # 传入嵌入模型
# persist_directory=persist_directory # 如果需要持久化
)
# 如果持久化了,下次可以这样加载:
# vector_store = Chroma(persist_directory=persist_directory, embedding_function=embeddings_model)
print("Vector store created/loaded.")
步骤 5: 检索 (Retrieval)
目的: 当用户提出问题 (Query) 时,从向量存储中检索出与问题最相关的文本块。
LangChain 组件: 向量存储对象本身通常就扮演了检索器的角色,提供了
similarity_search或as_retriever()方法。关键参数:
k: 指定检索多少个最相关的文本块。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22PYTHONquery = "LangChain 的主要功能是什么?"
# 直接进行相似性搜索
# relevant_docs = vector_store.similarity_search(query, k=3)
# for doc in relevant_docs:
# print(f"--- Relevant Chunk (Score: {doc.metadata.get('_score', 'N/A')}) ---") # Chroma 可能不直接返回分数
# print(doc.page_content)
# print(f"Source: {doc.metadata.get('source', 'N/A')}")
# print("-" * 20)
# 将向量存储转换为检索器 (Retriever) 对象,更符合 LangChain 的链式调用风格
retriever = vector_store.as_retriever(
search_type="similarity", # "similarity", "mmr" (Maximal Marginal Relevance), "similarity_score_threshold"
search_kwargs={"k": 5} # 检索 top 5 个最相关的块
)
# relevant_chunks = retriever.get_relevant_documents(query)
# print(f"\n--- Retrieved Chunks for query: '{query}' ---")
# for chunk in relevant_chunks:
# print(chunk.page_content[:300] + "...") # 打印部分内容
# print(f"Source: {chunk.metadata.get('source')}")
# print("-" * 10)
步骤 6: 生成 (Generation) - 构建问答链 (QA Chain)
目的: 将检索到的相关文本块和用户的原始问题一起提供给大型语言模型 (LLM),让 LLM 基于这些上下文信息生成最终的答案。
LangChain 组件:
langchain.llms或langchain.chat_models
: 选择一个 LLM。
OpenAI: 使用 GPT-3.5, GPT-4 等。HuggingFacePipeline: 在本地运行 Hugging Face Hub 上的模型。ChatOpenAI: 专门用于聊天模型的接口。
langchain.chains
: 提供了多种预置的链,用于组合不同的组件。
RetrievalQA: 一个方便的链,封装了检索和基于检索结果的问答。
关键参数 (RetrievalQA):
llm: 指定语言模型。retriever: 指定上一步创建的检索器。- chain_type: 控制如何将检索到的文档传递给 LLM。
"stuff": 最简单,将所有检索到的文本块直接“塞进”一个 Prompt 中。如果文本块总长度超过 LLM 上下文窗口会报错。"map_reduce": 对每个块单独调用 LLM (map 步骤),然后将结果汇总再调用一次 LLM (reduce 步骤)。适合处理大量文档块。"refine": 对第一个块调用 LLM 生成初步答案,然后将此答案和下一个块一起给 LLM,让其优化答案,依次进行。"map_rerank": 对每个块调用 LLM,并让其对答案的相关性打分,选择分数最高的。
return_source_documents: 是否在结果中返回源文档块。
示例代码 (使用 OpenAI LLM):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32PYTHONfrom langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# 选择 LLM
# llm = OpenAI(temperature=0) # temperature 控制生成的多样性
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) # 使用聊天模型
# 创建 RetrievalQA 链
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff", # 或者 "map_reduce", "refine", "map_rerank"
retriever=retriever,
return_source_documents=True, # 方便查看 LLM 参考了哪些上下文
# chain_type_kwargs={"prompt": YOUR_CUSTOM_PROMPT} # 可以自定义 Prompt 模板
)
# 提问并获取答案
question = "LangChain 中的 Text Splitter 有什么作用?"
result = qa_chain({"query": question}) # 对于 RetrievalQA,输入是一个包含 "query" 键的字典
print("\n--- Question ---")
print(question)
print("\n--- Answer ---")
print(result["result"])
if result.get("source_documents"):
print("\n--- Source Documents ---")
for doc in result["source_documents"]:
print(f"Source: {doc.metadata.get('source', 'N/A')}, Page: {doc.metadata.get('page', 'N/A')}") # 假设 PDF loader 添加了页码元数据
print(doc.page_content[:200] + "...")
print("-" * 10)
进一步优化和考虑:
- Prompt Engineering:
RetrievalQA链内部有默认的 Prompt 模板。你可以通过chain_type_kwargs={"prompt": your_custom_prompt_template}来定制 Prompt,以更好地指导 LLM 如何利用上下文。 - 记忆 (Memory): 如果需要进行多轮对话,可以引入
langchain.memory组件。 - 评估 (Evaluation): 使用
langchain.evaluation来评估你的问答系统性能。 - 错误处理和日志记录: 在生产环境中非常重要。
- 用户界面 (UI): 可以使用 Streamlit 或 Gradio 快速搭建一个简单的 Web UI。
- 选择合适的模型和参数: 嵌入模型、LLM、
chunk_size、chunk_overlap、k(检索数量)、chain_type等都需要根据你的具体文档和需求进行调整和实验。 - 成本控制: 如果使用付费 API,注意监控 Token 消耗。
- 流行的嵌入模型 (可以通过 LangChain 使用):
- OpenAI Embeddings:
- 模型:
text-embedding-ada-002: 曾是性价比非常高的选择,维度 1536。text-embedding-3-small: OpenAI 最新一代的小型嵌入模型,性能优于ada-002,维度 1536,且价格更低。text-embedding-3-large: OpenAI 最新一代的大型嵌入模型,性能最佳,维度 3072 (可配置输出维度),价格相对较高。
- 优点:
- 通常具有非常好的通用语义理解能力,在多种任务和语言上表现良好。
- 易于通过 API 使用。
text-embedding-3系列支持通过参数缩短输出维度,可以在一定程度上平衡性能和存储/计算成本。
- 缺点:
- 付费 API,需要网络连接。
- 数据隐私可能是一个考虑因素(尽管 OpenAI 有数据使用政策)。
- LangChain 使用:
from langchain_openai import OpenAIEmbeddings(注意 LangChain 的包结构更新,现在推荐使用langchain_community或特定集成包如langchain_openai)
- 模型:
- Hugging Face Sentence Transformers (开源,可本地运行):
- 模型 (部分流行示例):
sentence-transformers/all-MiniLM-L6-v2: 非常流行,速度快,性能均衡,维度 384。适合快速原型和资源受限场景。sentence-transformers/all-mpnet-base-v2: 性能通常优于MiniLM,维度 768。是all-MiniLM-L6-v2的一个很好的升级选择。sentence-transformers/multi-qa-mpnet-base-dot-v1: 专门为问答任务(特别是基于点积的相似度计算)优化。BAAI/bge-large-en-v1.5(或其中文版BAAI/bge-large-zh-v1.5): 北京智源人工智能研究院 (BAAI) 推出的 BGE (BAAI General Embedding) 系列模型,在 MTEB (Massive Text Embedding Benchmark) 等基准测试上表现优异,成为开源嵌入模型的新标杆。有多种尺寸 (small, base, large)。intfloat/e5-large-v2: 另一个在 MTEB 上表现出色的模型系列。- 多语言模型:
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2或sentence-transformers/paraphrase-multilingual-mpnet-base-v2支持多种语言。
- 优点:
- 开源免费。
- 可以在本地运行,数据完全私有。
- 模型选择非常丰富,可以根据具体需求(性能、速度、语言、任务)选择。
- 社区活跃,不断有新的优秀模型涌现。
- 缺点:
- 需要在本地配置环境并下载模型,可能需要一定的计算资源 (特别是对于大型模型或 GPU 加速)。
- 性能可能因模型而异,需要仔细选择和测试。
- LangChain 使用:
from langchain_community.embeddings import HuggingFaceEmbeddings
- 模型 (部分流行示例):
- Cohere Embeddings:
- 模型: Cohere 提供多种嵌入模型,如
embed-english-v3.0,embed-multilingual-v3.0。 - 优点:
- 商业模型,通常具有良好的性能和针对特定用例的优化(如检索、聚类)。
- API 易于使用。
- 缺点:
- 付费 API。
- LangChain 使用:
from langchain_cohere import CohereEmbeddings
- 模型: Cohere 提供多种嵌入模型,如
- Google Vertex AI Embeddings (PaLM API / Gemini API):
- 模型: Google 通过 Vertex AI 平台提供文本嵌入模型,例如基于 PaLM 或 Gemini 的嵌入。
- 优点:
- 背后是 Google 强大的模型研发能力。
- 与 Google Cloud 生态系统集成良好。
- 缺点:
- 付费 API。
- LangChain 使用:
from langchain_google_vertexai import VertexAIEmbeddings
- 其他开源模型 (通过 Hugging Face 或自定义集成):
- 除了 Sentence Transformers 库封装的模型,还有许多其他优秀的开源嵌入模型可以直接从 Hugging Face Hub 加载,或者通过自定义 LangChain 的
Embeddings类来集成。
- 除了 Sentence Transformers 库封装的模型,还有许多其他优秀的开源嵌入模型可以直接从 Hugging Face Hub 加载,或者通过自定义 LangChain 的
- OpenAI Embeddings:
- 流行的嵌入模型 (可以通过 LangChain 使用):
6.如何保证文档切片不会造成相关内容的丢失?文档切片的大小如何控制?
1.一般的文本切分可以按照字符、长度或者语义(经过NLP语义分析的模型)进行拆分。
2.刚好有一段完整的文本,如果切太小,那么则会造成信息丢失,给 LLM 的内容则不完整。太大则不利于向量检索命中。
文本切片不要使用固定长度,可以采用 LangChain 的 MultiVector Retriever ,它的主要是在做向量存储的过程进一步增强文档的检索能力。LangChain 有 Parent Document Retriever 采用的方案是用小分块保证尽可能找到更多的相关内容,用大分块保证内容完整性, 这里的大块文档是指 Parent Document 。MultiVector Retriever 在 Parent Document Retriever 基础之上做了能力扩充。
参考链接:https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/multi_vector/
7.RAG之假设文档嵌入(HyDE)
什么是HyDE
核心思想:
传统稠密检索直接将用户的简短、有时甚至不明确的查询(Query)嵌入到向量空间,然后与文档库中预先嵌入的文档向量进行比较。HyDE 认为,这种直接比较可能效果不佳,因为:
- 查询通常很短,信息量不足。
- 查询的措辞可能与相关文档的措辞有很大差异。
HyDE 的核心思想是:与其直接用原始查询去检索,不如先让一个强大的生成式语言模型 (LLM) 根据用户的查询“想象”或“假设”出一个相关的、理想的文档片段,然后用这个假设性文档的嵌入 (Embedding) 去检索实际的文档库。
为什么这样做可能有效?
- 更丰富的语义信息: LLM 生成的假设性文档通常比原始查询更长、更详细,包含了更多与查询主题相关的关键词和语义信息。
- 更接近文档的表达方式: LLM 在生成假设性文档时,其输出的语言风格和词汇选择可能更接近于文档库中真实文档的表达方式,从而更容易在向量空间中与真实相关文档对齐。
- “零样本”能力: HyDE 不需要针对特定检索任务进行有监督的微调(即不需要查询-相关文档对的标注数据),它利用的是预训练 LLM 的生成能力。
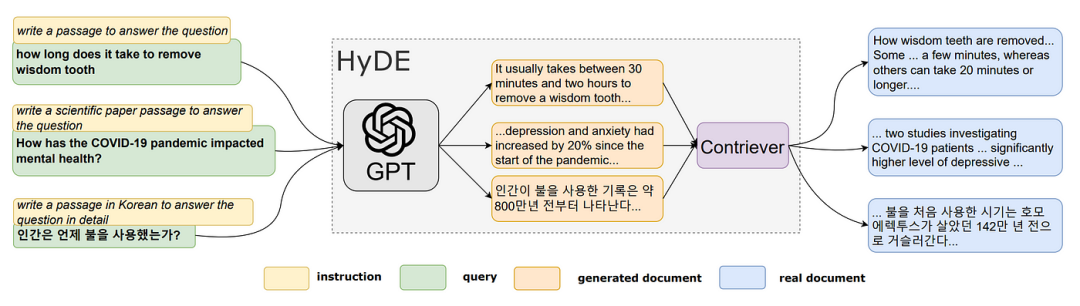
该流程主要分为四个步骤:
使用LLM基于查询生成k个假设文档。这些生成的文件可能不是事实,也可能包含错误,但它们应该于相关文件相似。此步骤的目的是通过LLM解释用户的查询。
将生成的假设文档输入编码器,将其映射到密集向量$f\left(d_{k}\right)$,编码器具有过滤功能,过滤掉假设文档中的噪声。这里,dk表示第k个生成的文档,f表示编码器操作。
使用给定的公式计算以下k个向量的平均值 $\mathbf{v}=\frac{1}{N} \sum_{k=1}^{N} f\left(d_{k}\right)$ ,可以将原始查询q视为一个可能的假设: $\mathbf{v}=\frac{1}{N+1} \sum_{k=1}^{N}\left[f\left(d_{k}\right)+f(q)\right]$
使用向量v从文档库中检索答案。如步骤3中所建立的,该向量保存来自用户的查询和所需答案模式的信息,这可以提高回忆。HyDE的目标是生成假设文档,以便最终查询向量v与向量空间中的实际文档尽可能紧密地对齐。
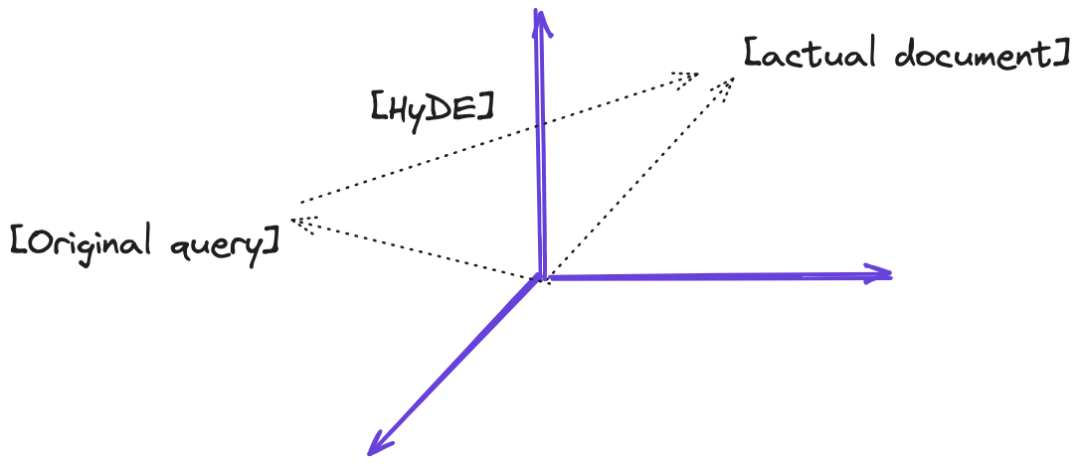
HyDE的作用
在检索增强生成(RAG)中,经常遇到用户原始查询的问题,如措辞不准确或缺乏语义信息,比如“The NBA champion of 2020 is the Los Angeles Lakers! Tell me what is langchain framework?”这样的查询,如果直接进行搜索,那么LLM可能会给出不正确或无法回答的回答。因此,将用户查询的语义空间与文档的语义空间对齐是至关重要的。查询重写技术可以有效地解决这一问题,从RAG流程的角度来看,查询重写是一种预检索方法。HyDE通过假设文档来对齐查询和文档的语义空间。
8.RAG的评估指标有哪些?
Context precision上下文精确度
评估检索质量,衡量上下文中所有相关的真实信息是否被排在较高的位置。理想情况下,所有相关的信息快都应该出现在排名的最前面。这个指标是根据问题和上下文来计算的,数值范围在0~1之间,分数越高表示精确度越好。
Context Recall上下文召回率
衡量检索的完整性,用来衡量检索到的上下文与被视为事实真相的标注答案的一致性程度。根据事实真相和检索到的上下文来计算,数值范围在0~1之间,数值越高表示性能越好。为了从事实真相的答案中估计上下午的召回率,需要分析答案中的每个句子是否可以归因于检索到的上下文。在理想情况下,事实真相答案中的所有句子都应该能够对应到检索到的上下文中。
区别总结:
| 特性 | Context Recall (上下文召回率) | Context Precision (上下文精确度) |
|---|---|---|
| 核心问题 | 是否漏掉了关键信息? | 是否引入了太多无关信息? |
| 目标 | 尽可能多地找回所有必要信息 | 确保找回的信息都是相关有用的 |
| 分母 | 回答问题所需的所有相关信息 | 所有被检索到的上下文信息 |
| 分子 | 检索到的上下文中包含的必要信息 | 检索到的上下文中相关有用的信息 |
| 低值影响 | LLM 可能因信息不足无法回答或产生幻觉 | LLM 可能被噪声干扰、成本增加、超出上下文窗口 |
| 理想情况 | 尽可能高,接近 1 | 尽可能高,接近 1 |
Faithfulness忠实度
衡量生成答案中的幻觉情况,衡量生成答案与给定上下文之间的事实一致性。忠实度得分是基于答案和检索到的上下文计算出来的,答案的评分范围在0~1之间,分数越高越好。
Answer Relevance答案相关性
衡量答案对问题的直接性(紧扣问题的核心),旨在评估生成答案与给定提示的相关程度。如果答案不完整或包含冗余信息,则会被赋予较低的分数。这个指标使用问题和答案来计算,其值介于0~1之间,得分越高表明答案的相关性越好。
9.llama-index的索引类别有哪些?
索引的概念
Index是一种数据结构,允许我们快速检索用户查询的相关上下文。对于 LlamaIndex 来说,它是检索增强生成 (RAG) 用例的核心基础。在高层次上,Indexes是从Documents构建的。它们用于构建查询引擎和聊天引擎 ,从而可以通过数据进行问答和聊天。在底层,Indexes将数据存储在Node对象中(代表原始文档的块),并公开支持额外配置和自动化的Retriever接口。
Node:对应于文档中的一段文本。LlamaIndex 接收 Document 对象并在内部将它们解析/分块为 Node 对象。
Response Synthesis:我们的模块根据检索到的节点合成响应。
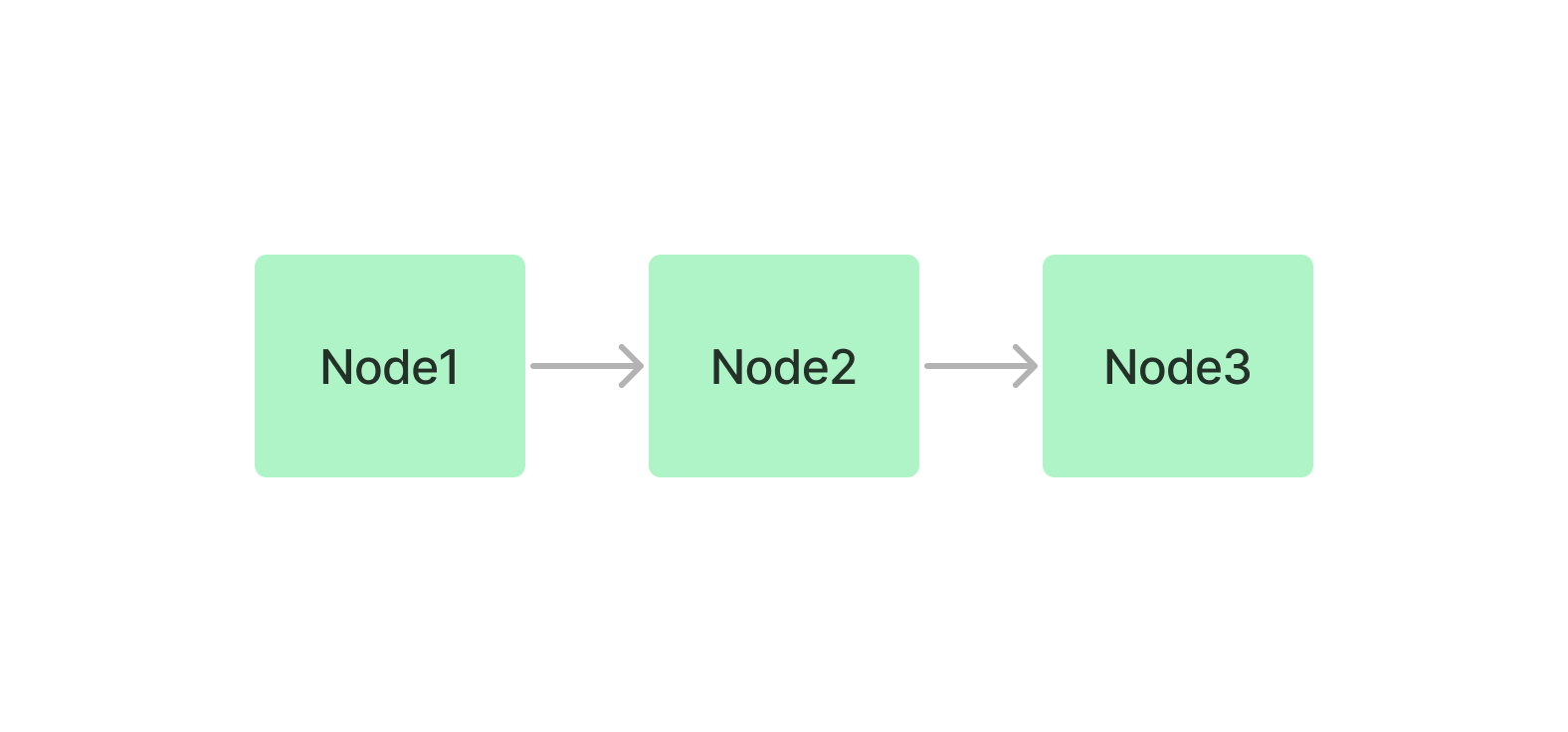
llam-index有以下五种索引
- Summary Index ,将节点存储为顺序链
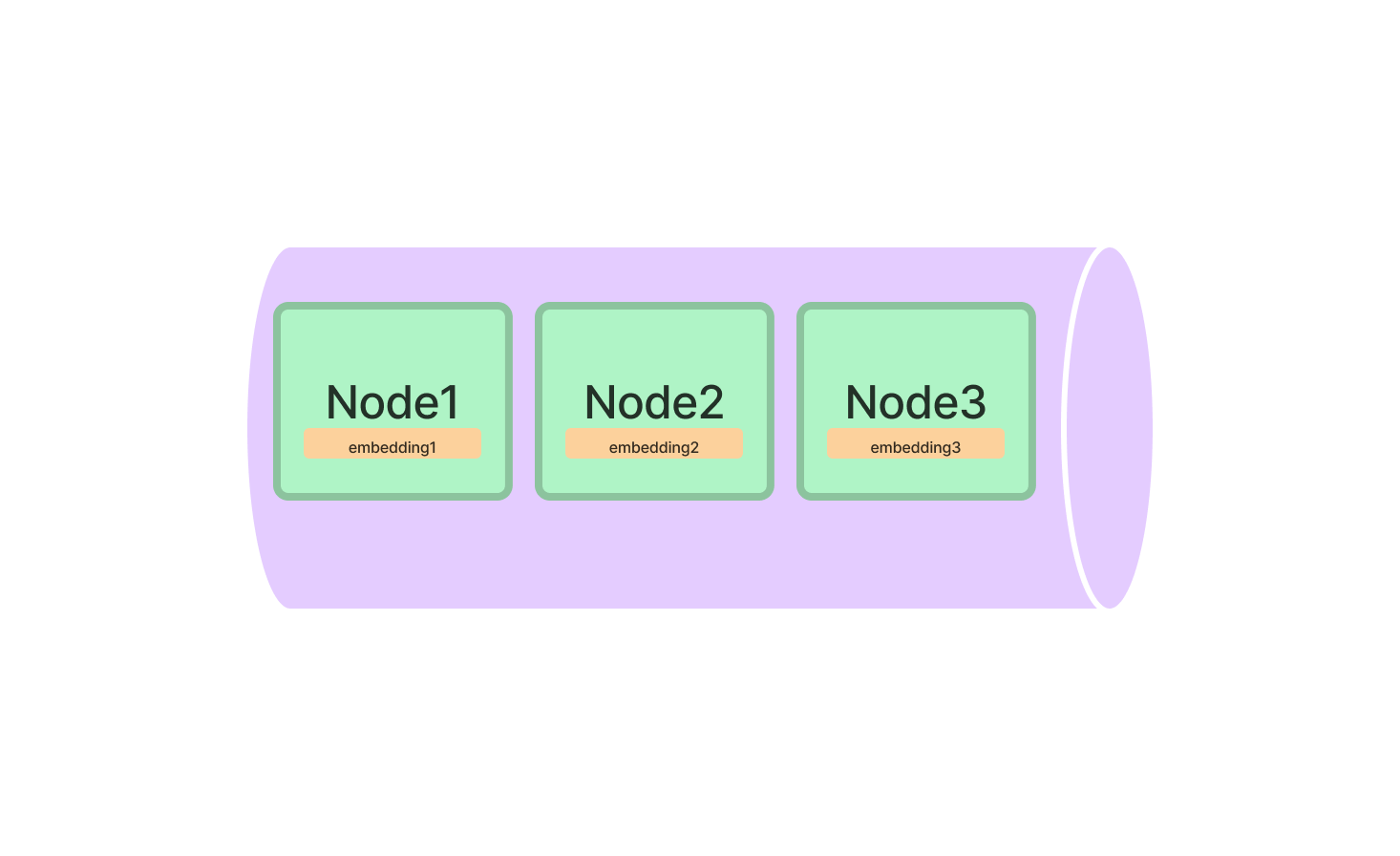
- Vector Store Index,将每个节点及其相应的嵌入存储在向量存储中
- Tree Index,从一组节点(在此树中成为叶节点)构建一个层次结构树
- Keyword Table Index,从每个节点中提取关键字,并建立从每个关键字到相应节点的映射。
- Property Graph Index,构建包含标记节点和关系的知识图谱。这个图的构造是非常可定制的,从让 LLM 提取它想要的任何内容,到使用严格的模式提取,甚至实现你自己的提取模块,也可以嵌入节点以供以后检索。
llama-index文档链接
10.向量数据库介绍
什么是向量数据库
向量数据库是一种将数据存储为高维向量的数据库,高维向量是特征或属性的数学表示。每个向量都有一定数量的维度,范围从几十到几千不等,具体取决于数据的复杂性和粒度。向量数据库同时具有CRUD操作、元数据过滤和水平扩展等功能。通过复杂的查询语言,利用资源管理、安全控制、可扩展性、容错能力和高效信息检索等数据库功能,可以提高应用程序开发效率.
向量数据库的特点
支持向量相似性搜索,它会找到与查询向量最近的 k 个向量,这是通过相似性度量来衡量的。 向量相似性搜索对于图像搜索、自然语言处理、推荐系统和异常检测等应用非常有用。
使用向量压缩技术来减少存储空间并提高查询性能。向量压缩方法包括标量量化、乘积量化和各向异性向量量化。
可以执行精确或近似的最近邻搜索,具体取决于准确性和速度之间的权衡。精确最近邻搜索提供了完美的召回率,但对于大型数据集可能会很慢。近似最近邻搜索使用专门的数据结构和算法来加快搜索速度,但可能会牺牲一些召回率。
支持不同类型的相似性度量,例如 L2 距离、内积和余弦距离。不同的相似性度量可能适合不同的用例和数据类型。
可以处理各种类型的数据源,例如文本、图像、音频、视频等。
- 可以使用机器学习模型将数据源转化为向量嵌入,例如词嵌入、句子嵌入、图像嵌入等。
有哪些向量数据库
1、Elasticsearch
ElasticSearch是一个支持各种类型数据的分布式搜索和分析引擎。 Elasticsearch 支持的数据类型之一是向量字段,它存储密集的数值向量。

在 7.10 版本中,Elasticsearch 添加了对将向量索引到专用数据结构的支持,以支持通过 kNN 搜索 API 进行快速 kNN 检索。 在 8.0 版本中,Elasticsearch 添加了对带有向量场的原生自然语言处理 (NLP) 的支持。
2、Faiss
Meta的Faiss是一个用于高效相似性搜索和密集向量聚类的库。 它包含搜索任意大小的向量集的算法,直到可能不适合 RAM 的向量集。 它还包含用于评估和参数调整的支持代码。

3、Milvus
Milvus是一个开源向量数据库,可以管理万亿向量数据集,支持多种向量搜索索引和内置过滤。

4、Weaviate
Weaviate是一个开源向量数据库,允许你存储数据对象和来自你最喜欢的 ML 模型的向量嵌入,并无缝扩展到数十亿个数据对象。

5、Pinecone
Pinecone专为机器学习应用程序设计的向量数据库。 它速度快、可扩展,并支持多种机器学习算法。

Pinecone 建立在 Faiss 之上,Faiss 是一个用于密集向量高效相似性搜索的库。
6、Qdrant
Qdrant是一个向量相似度搜索引擎和向量数据库。 它提供了一个生产就绪的服务,带有一个方便的 API 来存储、搜索和管理点带有额外有效负载的向量。

Qdrant 专为扩展过滤支持而定制。 它使它可用于各种神经网络或基于语义的匹配、分面搜索和其他应用程序。
7、Vespa
Vespa是一个功能齐全的搜索引擎和向量数据库。 它支持向量搜索 (ANN)、词法搜索和结构化数据搜索,所有这些都在同一个查询中。 集成的机器学习模型推理允许你应用 AI 来实时理解你的数据。

8、Vald
Vald是一个高度可扩展的分布式快速近似最近邻密集向量搜索引擎。 Vald是基于Cloud-Native架构设计和实现的。 它使用最快的 ANN 算法 NGT 来搜索邻居。

Vald 具有自动向量索引和索引备份,以及水平缩放,可从数十亿特征向量数据中进行搜索。
9、ScaNN (Google Research)
ScaNN(Scalable Nearest Neighbours)是一个用于高效向量相似性搜索的库,它找到 k 个与查询向量最近的向量,通过相似性度量来衡量。向量相似性搜索对于图像搜索、自然语言处理、推荐系统和异常检测等应用非常有用。
10、pgvector
pgvector是PostgreSQL 的开源扩展,允许你在数据库中存储和查询向量嵌入。 它建立在 Faiss 库之上,Faiss 库是一个流行的密集向量高效相似性搜索库。 pgvector 易于使用,只需一条命令即可安装。

11.RAG之Re-Ranking机制介绍
为什么要用Re-Ranking?
检索阶段的挑战
在RAG模型中,检索器负责从大规模的语料库中检索与输入问题相关的文档。然而,由于语料库的广泛性和多样性,检索器可能返回的文档的相关性会有所不同。这种不确定性带来了两个主要挑战:
文档相关性差异: 检索器返回的文档可能在相关性上存在差异,有些文档可能与输入问题高度相关,而有些文档可能相关性较低。这种差异性使得直接使用检索器返回的文档进行生成可能会导致结果的不准确或不相关。
信息不完整性: 检索器返回的文档通常只是初步筛选,其中可能包含了一些噪音或不相关的信息。这使得生成器在生成结果时面临着信息不完整的挑战,需要进一步处理以提高结果的质量。
因此,为了克服这些挑战,需要引入Re-Ranking机制对检索器返回的文档进行再排序,以确保最终使用的文档具有更高的相关性和质量。
提高生成质量
Re-Ranking机制不仅可以解决检索阶段的挑战,还可以显著提高生成结果的质量。通过对检索器返回的文档进行再排序,Re-Ranking机制可以使生成器在生成结果时更加准确、相关。
具体来说,Re-Ranking机制可以帮助生成器更好地理解和利用检索到的信息,从而生成更加贴近输入问题的文本。它可以过滤掉不相关或噪音信息,强化相关文档的影响,从而提高生成结果的相关性和准确性。这样,Re-Ranking机制不仅可以提高生成结果的质量,还可以增强模型对输入问题的理解能力,使得模型在实际应用中更加可靠和实用。
什么是Re-Ranking
Re-Ranking是指在RAG模型中对检索器返回的文档进行再排序的过程。其目的是通过重新排列候选文档,使得生成器更好地利用相关信息,并生成与输入问题更加相关和准确的结果。
在RAG中,Re-Ranking的关键目标是提高生成结果的相关性和质量。通过对检索器返回的文档进行再排序,Re-Ranking可以将与输入问题更加相关的文档排在前面,从而使得生成器在生成结果时能够更加准确地捕捉到输入问题的语境和要求,进而生成更加合适的答案或文本。
Re-Ranking的步骤
Re-Ranking的过程可以分为以下几个步骤:
检索文档: 首先,RAG模型通过检索器从大规模语料库中检索相关文档,这些文档被认为可能包含了与输入问题相关的信息。
特征提取: 对检索到的文档进行特征提取,通常会使用各种特征,如语义相关性、词频、TF-IDF值等。这些特征能够帮助模型评估文档与输入问题的相关性。
排序文档: 根据提取的特征,对检索到的文档进行排序,将与输入问题最相关的文档排在前面,以便后续生成器使用。
重新生成: 排序完成后,生成器将重新使用排在前面的文档进行文本生成,以生成最终的输出结果。
Re-Ranking的方法
在RAG中,有多种方法可以实现Re-Ranking,包括但不限于:
基于特征的Re-Ranking: 根据检索到的文档提取特征,并利用这些特征对文档进行排序,以提高与输入问题相关的文档在排序中的优先级。
学习型Re-Ranking: 使用机器学习算法,如支持向量机(SVM)、神经网络等,根据历史数据和标注样本,学习文档与输入问题之间的相关性,并利用学习到的模型对文档进行再排序。
混合方法: 将基于特征的方法和学习型方法结合起来,以充分利用特征提取和机器学习的优势,从而更好地实现Re-Ranking的目标。
Re-Ranking的优化策略
在实际应用中,我们可以采用一些优化策略来进一步提高Re-Ranking的性能和效果:
特征优化: 不断优化提取的特征,使其更能反映文档与输入问题的相关性,从而提高Re-Ranking的准确性。
模型调优: 如果采用学习型的Re-Ranking方法,可以通过调整模型结构、超参数等来提高模型的性能,使其更好地适应具体的应用场景。
多模态融合: 结合文本信息以外的其他模态信息,如图像、视频等,可以提供更多的信息来辅助Re-Ranking,从而提高最终结果的质量。
实时调整: 根据实际应用情况,动态调整Re-Ranking策略,以适应不同类型的输入问题和文档。
当前Re-Ranking面临的挑战
在实际应用中,Re-Ranking面临一些挑战,限制了其性能和效果,主要包括:
计算复杂性: Re-Ranking过程涉及对大规模文档进行排序和评估,计算复杂度较高。尤其是对于大型语料库和实时应用场景,计算资源需求巨大,需要寻找高效的算法和技术来加速处理。
可解释性和透明度: Re-Ranking的结果直接影响生成结果的质量,但其内部工作机制通常较为复杂,缺乏可解释性和透明度。这使得难以理解和调试Re-Ranking过程中的问题,也限制了用户对结果的信任度。
数据偏差和公平性: Re-Ranking的效果往往受到数据的影响,如果训练数据存在偏差,可能会导致Re-Ranking结果的偏差。此外,Re-Ranking策略可能对不同群体或类别的文档产生不同程度的影响,需要考虑公平性和平衡性的问题。
12.RAG之Embedding模型介绍
1.BGE
BGE,即BAAI General Embedding,是由智源研究院(BAAI)团队开发的一款文本Embedding模型。该模型可以将任何文本映射到低维密集向量,这些向量可用于检索、分类、聚类或语义搜索等任务。此外,它还可以用于LLMs的向量数据库。
BGE模型在2023年有多次更新,包括发布论文和数据集、发布新的reranker模型以及更新Embedding模型。BGE模型已经集成到Langchain中,用户可以方便地使用它。此外,BGE模型在MTEB和C-MTEB基准测试中都取得了第一名的成绩。
BGE模型的主要特点如下:
多语言支持:BGE模型支持中英文。
多版本:BGE模型有多个版本,包括bge-large-en、bge-base-en、bge-small-en等,以满足不同的需求。
高效的reranker:BGE提供了reranker模型,该模型比Embedding模型更准确,但比Embedding模型更耗时。因此,它可以用于重新排名Embedding模型返回的前k个文档。
开源和许可:BGE模型是开源的,并在MIT许可下发布。这意味着用户可以免费用于商业目的。
丰富集成:用户可以使用FlagEmbedding、Sentence-Transformers、Langchain或Huggingface Transformers等工具来使用BGE模型。
2.GTE
GTE模型,也称为General Text Embeddings,是阿里巴巴达摩院推出的文本Embedding技术。它基于BERT框架构建,并分为三个版本:GTE-large、GTE-base和GTE-small。
该模型在大规模的多领域文本对语料库上进行训练,确保其广泛适用于各种场景。因此,GTE可以应用于信息检索、语义文本相似性、文本重新排序等任务。
尽管GTE模型的参数规模为110M,但其性能卓越。它不仅超越了OpenAI的Embedding API,在大型文本Embedding基准测试中,其表现甚至超过了参数规模是其10倍的其他模型。更值得一提的是,GTE模型可以直接处理代码,无需为每种编程语言单独微调,从而实现优越的代码检索效果。
3.E5 Embedding
E5-embedding是由intfloat团队研发的一款先进的Embedding模型。E5的设计初衷是为各种需要单一向量表示的任务提供高效且即用的文本Embedding,与其他Embedding模型相比,E5在需要高质量、多功能和高效的文本Embedding的场景中表现尤为出色。
E5-embedding的主要特点:
新的训练方法:E5采用了“EmbEddings from bidirEctional Encoder rEpresentations”这一创新方法进行训练,这意味着它不仅仅依赖传统的有标记数据,也不依赖低质量的合成文本对。
高质量的文本表示:E5能为文本提供高质量的向量表示,这使得它在多种任务上都能表现出色,尤其是在需要句子或段落级别表示的任务中。
多场景:无论是在Zero-shot场景还是微调应用中,E5都能提供强大的现成文本Embedding,这使得它在多种NLP任务中都有很好的应用前景。
4.Jina Embedding
jina-embedding-s-en-v1是Jina AI的Finetuner团队精心打造的文本Embedding模型。它基于Jina AI的Linnaeus-Clean数据集进行训练,这是一个包含了3.8亿对句子的大型数据集,涵盖了查询与文档之间的配对。这些句子对涉及多个领域,并已经经过严格的筛选和清洗。值得注意的是,Linnaeus-Clean数据集是从更大的Linnaeus-Full数据集中提炼而来,后者包含了高达16亿的句子对。
Jina Embedding的主要特点:
广泛应用:jina-embedding-s-en-v1适合多种场景,如信息检索、语义文本相似性判断和文本重新排序等。
卓越性能:虽然该模型参数量仅为35M,但其性能出众,而且能够快速进行推理。
多样化版本:除了标准版本,用户还可以根据需求选择其他大小的模型,包括14M、110M、330M
5.Instructor
Instructor是由香港大学自然语言处理实验室团队推出的一种指导微调的文本Embedding模型。该模型可以生成针对任何任务(例如分类、检索、聚类、文本评估等)和领域(例如科学、金融等)的文本Embedding,只需提供任务指导,无需任何微调。Instructor在70个不同的Embedding任务(MTEB排行榜)上都达到了最先进的性能。该模型可以轻松地与定制的sentence-transformer库一起使用。
Instructor的主要特点:
多任务适应性:只需提供任务指导,即可生成针对任何任务的文本Embedding。
高性能:在MTEB排行榜上的70个不同的Embedding任务上都达到了最先进的性能。
易于使用:与定制的sentence-transformer库结合使用,使得模型的使用变得非常简单。
6.XLM-Roberta
XLM-Roberta(简称XLM-R)是Facebook AI推出的一种多语言版本的Roberta模型。它是在大量的多语言数据上进行预训练的,目的是为了提供一个能够处理多种语言的强大的文本表示模型。XLM-Roberta模型在多种跨语言自然语言处理任务上都表现出色,包括机器翻译、文本分类和命名实体识别等。
XLM-Roberta的主要特点:
多语言支持:XLM-Roberta支持多种语言,可以处理来自不同语言的文本数据。
高性能:在多种跨语言自然语言处理任务上,XLM-Roberta都表现出了最先进的性能。
预训练模型:XLM-Roberta是在大量的多语言数据上进行预训练的,这使得它能够捕获跨语言的文本表示。
7.text-embedding-ada-002
text-embedding-ada-002是一个由Xenova团队开发的文本Embedding模型。该模型提供了一个与Hugging Face库兼容的版本的text-embedding-ada-002分词器,该分词器是从openai/tiktoken适应而来的。这意味着它可以与Hugging Face的各种库一起使用,包括Transformers、Tokenizers和Transformers.js。
text-embedding-ada-002的主要特点:
兼容性:该模型与Hugging Face的各种库兼容,包括Transformers、Tokenizers和Transformers.js。
基于openai/tiktoken:该模型的分词器是从openai/tiktoken适应而来的。
13.RAG之PDF文档加载器介绍
PDF的解析方法:
基于规则的方法:根据文档的组织特征确定每个部分的风格和内容。然而,这种方法不是很通用,因为PDF有很多类型和布局,不可能用预定义的规则覆盖所有类型和布局。
基于深度学习模型的方法:例如将目标检测和OCR模型相结合的流行解决方案。
基于多模态大模型对复杂结构进行Pasing或提取PDF中的关键信息。
常见的PDF文档加载器
- PyPDF
PyPDF 是一个用于处理PDF文件的Python库。它提供了一系列的功能,允许用户读取、写入、分析和修改PDF文档。在LangChain中,PyPDFLoader 使用 pypdf 库加载PDF文档为文档数组,PDF将会按照page逐页读取,每个文档包含页面内容和带有页码的元数据。
1 | from langchain_community.document_loaders import PyPDFLoader |
图片信息提取:pip install rapidocr-onnxruntime
1 | from langchain_community.document_loaders import PyPDFLoader |
- pyplumber
1 | from langchain_community.document_loaders import PDFPlumberLoader |
- PDFMiner
将整个文档解析成一个完整的文本,文本结构可以自行定义
1 | from langchain_community.document_loaders import PDFMinerLoader |
以上三种是基于规则解析
- Unstructured(基于深度学习模型)
非结构化加载器针对不同的文本块创建了不同的元素。默认情况下将其组合在一起,可以通过指定model=”elements”保持这种分离,然后根据自己的逻辑进行分离
1 | from langchain_community.document_loaders import UnstructuredPDFLoader |
14.RAG之chunking方法介绍
Fixed size chunking:这是最常见、最直接的分块方法。我们只需决定分块中的tokens数量,以及它们之间是否应该有任何重叠。一般来说,我们希望在块之间保持一些重叠,以确保语义上下文不会在块之间丢失。与其他形式的分块相比,固定大小的分块在计算上便宜且使用简单,因为它不需要使用任何NLP库。
Recursive Chunking:递归分块使用一组分隔符,以分层和迭代的方式将输入文本划分为更小的块。如果最初分割文本没有产生所需大小或结构的块,则该方法会使用不同的分隔符或标准递归地调用结果块,直至达到所需的块大小或结构。这意味着,虽然块的大小不会完全相同,但它们仍然具有相似的大小,并可以利用固定大小块和重叠的优点。
Document Specific Chunking:该方法不像上述两种方法一样,它不会使用一定数量的字符或递归过程,而是基于文档的逻辑部分(如段落或小节)来生成对齐的块。该方法可以保持内容的组织,从而保持了文本的连贯性,比如Markdown、Html等特殊格式。
Semantic Chunking:语义分块会考虑文本内容之间的关系。它将文本划分为有意义的、语义完整的块。这种方法确保了信息在检索过程中的完整性,从而获得更准确、更符合上下文的结果。与之前的分块策略相比,速度较慢。
16.介绍一下 LangChain
💡 https://python.langchain.com/docs/get_started/introduction
LangChain 是一个开源的、用于构建由大型语言模型 (LLM) 驱动的应用程序的框架 (Framework)。它的目标是简化将 LLM 与其他计算资源、数据源和工具集成的过程,从而让开发者能够创建更强大、更灵活、更具上下文感知能力的 AI 应用。
你可以把 LangChain 想象成一个“瑞士军刀”,它提供了各种预置的组件和工具,帮助你:
- 连接 LLM: 轻松地与各种 LLM (如 OpenAI GPT 系列, Hugging Face Hub 上的模型, Anthropic Claude 等) 进行交互。
- 管理 Prompt: 高效地创建、管理和优化给 LLM 的指令 (Prompt)。
- 链接组件 (Chaining): 将 LLM 与其他组件(如数据检索器、工具、其他 LLM 调用)串联起来,形成“链 (Chain)”来执行更复杂的任务。
- 赋予 LLM 记忆 (Memory): 让 LLM 能够记住之前的交互内容,实现有状态的对话。
- 赋予 LLM 工具使用能力 (Agents): 构建能够动态决定使用哪些外部工具(如搜索引擎、计算器、API)来完成任务的“智能体 (Agent)”。
- 数据增强生成 (RAG - Retrieval Augmented Generation): 将 LLM 与你自己的私有数据或外部知识库结合,生成更准确、更相关的答案。
- 评估 (Evaluation): 提供工具和方法来评估你的 LLM 应用的性能。
LangChain 的核心价值:
- 模块化与可组合性: LangChain 的设计强调模块化,允许开发者像搭积木一样组合不同的组件。
- 抽象化: 它封装了与 LLM 和其他工具交互的复杂细节,提供了更高级别的抽象接口。
- 标准化: 为构建 LLM 应用提供了一套通用的模式和组件,促进了代码的可重用性和社区协作。
- 灵活性: 支持多种 LLM、数据源和工具,并允许自定义组件。
LangChain 的核心概念 (Core Concepts):
理解以下核心概念是掌握 LangChain 的关键:
模型 (Models):
LLMs (Large Language Models):
接受文本输入,返回文本输出。这是最基础的语言模型接口。
- 示例:
OpenAI,HuggingFacePipeline
- 示例:
Chat Models (聊天模型):
专门为对话场景设计,接受一系列聊天消息 (通常带有角色,如 “user”, “assistant”, “system”) 作为输入,返回一个聊天消息作为输出。
- 示例:
ChatOpenAI,ChatAnthropic
- 示例:
Text Embedding Models (文本嵌入模型):
接受文本输入,返回一个浮点数向量 (嵌入),用于表示文本的语义。
- 示例:
OpenAIEmbeddings,HuggingFaceEmbeddings
- 示例:
提示 (Prompts):
Prompt Templates (提示模板):
用于动态生成给 LLM 的指令。它们包含一个文本字符串(模板),其中可以包含变量,这些变量在运行时会被具体的值替换。
- 示例:
PromptTemplate("告诉我一个关于 {subject} 的笑话。")
- 示例:
Chat Prompt Templates (聊天提示模板): 专门为聊天模型设计,用于生成一系列聊天消息。
Example Selectors (示例选择器): 用于在提示中动态地选择和插入少量示例 (few-shot examples),以帮助 LLM 更好地理解任务。
Output Parsers (输出解析器): 负责将 LLM 返回的原始文本输出解析成更结构化、更易于程序使用的格式(如 JSON 对象、列表、自定义类实例)。
链 (Chains):
- 核心思想: 将多个组件(可以是 LLM、Prompt、工具、其他链等)按特定顺序组合起来,形成一个调用序列,以完成更复杂的任务。前一个组件的输出通常作为下一个组件的输入。
- 常见类型:
LLMChain: 最基础的链,通常由 Prompt Template + LLM + (可选) Output Parser 组成。- Sequential Chains (顺序链): 按顺序执行多个链。
- Router Chains (路由链): 根据输入动态选择要执行的下一个链。
- RetrievalQA Chain: 用于结合检索器进行问答。
- ConversationalRetrievalChain: 带记忆的检索问答链。
索引 (Indexes) 与检索器 (Retrievers):
核心思想: 用于结构化和检索外部数据,以便 LLM 能够利用这些数据。这是实现 RAG 的关键。
Indexes (索引):
将原始数据(如文档)转换为 LLM 更易于查询的格式。
- 常见类型:
VectorStoreIndex(将文本嵌入并存储在向量数据库中),KeywordTableIndex,TreeIndex。
- 常见类型:
Retrievers (检索器):
负责根据用户的查询从索引中检索相关的文档或数据块。
- 示例: 向量存储的
as_retriever()方法。
- 示例: 向量存储的
Vector Stores (向量存储):
专门用于存储和高效检索文本嵌入向量的数据库。
- 示例:
Chroma,FAISS,Pinecone,Weaviate。
- 示例:
Document Loaders (文档加载器): 用于从各种来源(如 PDF, TXT, Web 页面, 数据库)加载数据。
Text Splitters (文本分割器): 将长文档分割成更小的、适合 LLM 处理的文本块。
记忆 (Memory):
- 核心思想: 允许链或 Agent 在多次交互之间保持状态,例如记住对话历史。
- 常见类型:
ConversationBufferMemory: 存储完整的对话历史。ConversationBufferWindowMemory: 只存储最近的 K 轮对话。ConversationSummaryMemory: 使用 LLM 对对话历史进行摘要。VectorStoreRetrieverMemory: 将对话历史存储在向量数据库中,并根据当前查询检索相关的历史片段。
智能体 (Agents) 与工具 (Tools):
核心思想: 赋予 LLM 使用外部工具的能力,使其能够与环境交互、获取信息、执行操作,从而完成更复杂的、需要多步骤推理和行动的任务。
Agents (智能体):
包含一个 LLM(作为大脑)和一套工具。Agent 会根据用户的目标,通过 LLM 进行思考和规划,决定调用哪个工具,执行工具,观察结果,然后重复这个过程,直到任务完成。
- 关键组件: LLM, Tools, Agent Executor (驱动 Agent 运行的引擎), Prompt (指导 Agent 如何思考和行动)。
Tools (工具):
代表 Agent 可以调用的具体功能。每个工具都有一个名称、描述(告诉 LLM 工具能做什么)和一个执行函数。
- 示例: 搜索引擎工具、计算器工具、Python REPL 工具、API 调用工具、自定义函数工具。
回调 (Callbacks):
- 核心思想: 提供一个机制,允许开发者在 LangChain 应用执行的各个生命周期阶段(如链开始/结束、LLM 调用开始/结束、工具使用等)插入自定义逻辑。
- 用途: 日志记录、监控、流式输出、调试、与第三方服务集成等。
17.LangChain 中 Chat Message History 是什么?
💡 https://python.langchain.com/docs/modules/memory/chat_messages/
Chat Message History 是 Langchain 框架中的一个组件,用于存储和管理聊天消息的历史记录。它可以跟踪和保存用户和AI之间的对话,以便在需要时进行检索和分析。
Langchain 提供了不同的 Chat Message History 实现,包括 StreamlitChatMessageHistory、CassandraChatMessageHistory 和 MongoDBChatMessageHistory。
您可以根据自己的需求选择适合的 Chat Message History 实现,并将其集成到 Langchain 框架中,以便记录和管理聊天消息的历史记录。
请注意,Chat Message History 的具体用法和实现细节可以参考 Langchain 的官方文档和示例代码。
18.LangChain 中 LangChain Agent 是什么?
💡 https://python.langchain.com/docs/modules/agents/
LangChain Agent 是 LangChain 框架中的一个组件,用于创建和管理对话代理。代理是根据当前对话状态确定下一步操作的组件。LangChain 提供了多种创建代理的方法,包括 OpenAI Function Calling、Plan-and-execute Agent、Baby AGI 和 Auto GPT 等。这些方法提供了不同级别的自定义和功能,用于构建代理。
代理可以使用工具包执行特定的任务或操作。工具包是代理使用的一组工具,用于执行特定的功能,如语言处理、数据操作和外部 API 集成。工具可以是自定义构建的,也可以是预定义的,涵盖了广泛的功能。
通过结合代理和工具包,开发人员可以创建强大的对话代理,能够理解用户输入,生成适当的回复,并根据给定的上下文执行各种任务。
LangChain 中常见的 Agent 类型:
- ReAct (Reasoning and Acting): 一种流行的 Agent 框架,LLM 会明确地生成“思考 (Thought)”和“行动 (Action)”步骤。
- Self-Ask with Search: 适用于需要通过一系列搜索来回答复杂问题的场景。
- OpenAI Functions Agent: 利用 OpenAI 模型内置的函数调用能力,LLM 可以直接请求调用特定的函数(工具)。这是目前推荐且效果较好的一种 Agent 类型。
- Conversational Agent: 带有记忆功能的 Agent,可以进行多轮对话。
以下是使用 LangChain 创建代理的示例代码:
1 | from langchain_openai import ChatOpenAI |
21.LangChain 如何链接多个组件处理一个特定的下游任务?
要链接多个组件处理一个特定的下游任务,您可以使用LangChain框架提供的Chain类。Chain类允许您将多个组件连接在一起,以便按顺序处理任务。以下是一个示例代码片段,展示了如何使用Chain类链接多个组件处理下游任务:
1 | from langchain.chains import Chain |
在上面的代码中,我们首先创建了多个组件的实例,例如Component1、Component2和Component3。然后,我们创建了一个Chain实例,并使用add_component方法将这些组件添加到链中。最后,我们调用process_downstream_task方法来处理下游任务,并打印输出结果。
请注意,您可以根据需要添加、删除和修改组件。Chain类提供了多种方法来操作链。更多详细信息和示例代码可以在LangChain文档中找到。
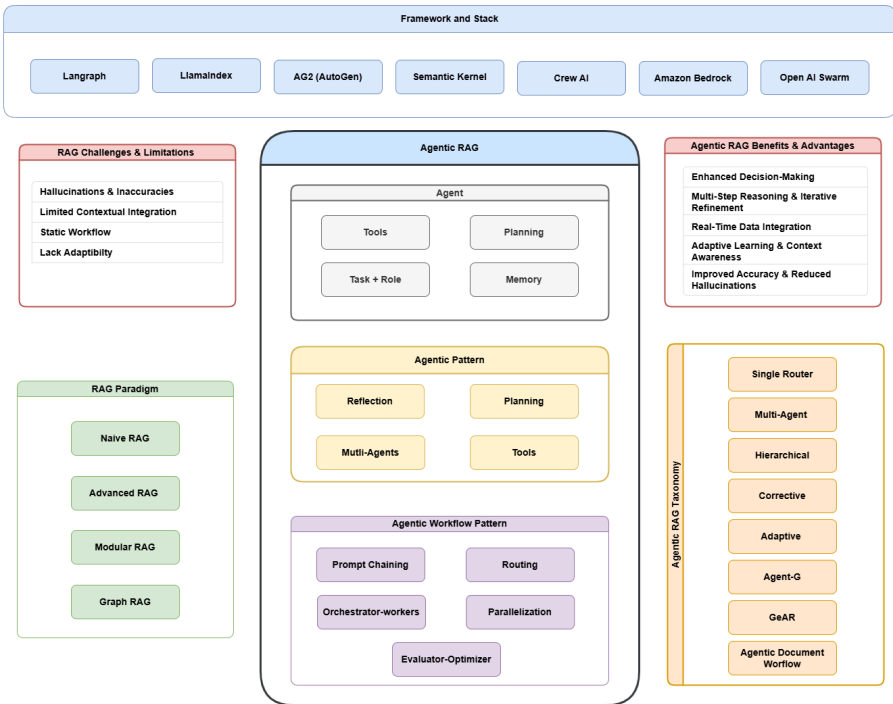
22.什么是Agentic RAG?它与传统RAG有何不同?
Agentic RAG(代理型检索增强生成) 是一种先进的自然语言处理模型架构,结合了检索(Retrieval)和生成(Generation)的能力,并引入了代理机制(Agentic Mechanism),使其具备自主决策、动态适应和多任务处理的能力。Agentic RAG不仅能够根据输入的查询从外部知识库中检索相关信息,还能通过智能代理模块优化检索策略、管理上下文信息,并生成连贯、准确且高度相关的自然语言回答。
与传统RAG相比,Agentic RAG不仅能够检索相关信息并生成回答,还能根据任务需求主动选择和优化检索策略,甚至在多轮交互中调整其行为,以实现更智能和灵活的信息处理。
Agentic RAG (智能体增强的检索增强生成) 是一种更高级、更智能的 RAG 范式。它不仅仅是在生成答案前进行一次性的简单信息检索,而是引入了智能体 (Agent) 的概念来动态地、迭代地、策略性地进行信息检索和利用。
可以将其理解为:
传统 RAG: 像一个学生,在回答问题前去图书馆查一次资料,然后根据查到的资料回答。
Agentic RAG:
像一个经验丰富的研究员或侦探,在面对一个复杂问题时,会:
- 分解问题 (Decomposition): 将复杂问题分解成更小的、可管理子问题。
- 规划检索策略 (Planning): 决定先检索什么信息,用什么关键词,从哪些数据源检索。
- 迭代检索与反思 (Iterative Retrieval & Reflection): 根据初步检索结果,判断信息是否足够,是否需要调整检索策略,是否需要进行多轮检索,甚至检索关于检索结果的元信息。
- 工具使用 (Tool Use): 可能不仅仅是文本检索,还可能调用其他工具(如代码解释器、计算器、API)来处理或验证信息。
- 综合与推理 (Synthesis & Reasoning): 在收集到足够的信息后,进行更复杂的推理和综合,最终生成答案。
Agentic RAG 的核心特征:
- 动态性与自适应性: 检索过程不是固定的,而是根据具体问题和中间结果动态调整。
- 迭代性: 可能进行多轮检索,每一轮都基于前一轮的结果进行优化。
- 规划与策略: Agent 会制定检索计划,而不是盲目检索。
- 反思与评估: Agent 会评估检索到的信息的质量和相关性,并决定是否需要进一步行动。
- 多源与多模态 (潜力): Agent 可以被设计为从多个不同的数据源(结构化、非结构化、知识图谱)甚至不同模态(文本、图像)中检索信息。
- 工具集成: 可以集成多种工具来辅助信息获取和处理。
DeepResearch:
本质是基于Agentic RAG架构的特定场景实现,但进一步强化了自动化研究流程与结构化输出能力。其核心目标是模拟人类研究员的思维模式,通过大规模信息采集、多模态数据融合和逻辑链构建,生成符合学术或商业标准的深度分析报告。例如,在完成“全球iOS与安卓市场份额趋势分析”任务时,Deep Research会自动爬取统计机构数据、清洗异常值、生成可视化图表并撰写结论。
23.Agentic RAG的核心组件有哪些?
以下是 Agentic RAG 的一些核心组件:
LLM Agent (核心大脑 - Large Language Model Agent):
- 角色: 这是整个系统的核心决策者和规划者。通常是一个强大的大型语言模型 (LLM),被赋予了 Agent 的行为模式。
- 功能:
- 理解用户意图和复杂问题。
- 规划 (Planning): 制定解决问题的步骤、检索策略、以及何时使用何种工具。
- 问题分解 (Decomposition): 将复杂问题拆解成更小、更易于处理的子问题。
- 工具选择与调用 (Tool Selection & Invocation): 根据规划决定使用哪个工具,并生成调用工具所需的参数。
- 反思与评估 (Reflection & Evaluation): 分析检索到的信息或工具执行的结果,评估其相关性、充分性和准确性,并据此调整后续计划。
- 信息综合与答案生成 (Synthesis & Generation): 在收集到足够信息后,进行推理、综合,并生成最终的答案或报告。
- 实现: 通常通过精心设计的 Prompt 工程、特定的 Agent 架构 (如 ReAct, Self-Ask, 或基于 LLM 函数调用的 Agent) 来实现。
规划器 (Planner):
- 角色: 负责根据用户的高层目标生成一个行动计划或任务序列。
- 功能:
- 将模糊或复杂的目标具体化为一系列可执行的步骤。
- 决定每个步骤需要达成的子目标或需要获取的信息类型。
- 有时会涉及到任务的优先级排序或依赖关系管理。
- 实现: 可以是 LLM Agent 自身能力的一部分(通过 Prompt 指导),也可以是一个独立的模块,甚至是一个更小的、专门用于规划的 LLM。
记忆模块 (Memory):
- 角色: 存储和管理 Agent 在执行任务过程中的信息,包括对话历史、中间思考、检索到的上下文、工具使用历史等。
- 功能:
- 短期记忆 (Working Memory / Scratchpad): 存储当前任务的中间步骤、观察结果、LLM 的思考过程,供 LLM 在后续决策时参考。
- 长期记忆 (Long-term Memory): (可选,但对于复杂任务或持续学习很重要) 存储过去的经验、成功的策略、重要的知识片段,以便在未来任务中复用。
- 对话历史: 记录与用户的交互,保持对话的连贯性。
- 实现: LangChain 中的
ChatMessageHistory,ConversationBufferMemory,VectorStoreRetrieverMemory等,以及更复杂的自定义记忆结构。
工具集 (Tool Set / Toolkit):
角色: 提供 Agent 与外部世界交互、获取信息或执行操作的具体能力。
功能:
Agentic RAG 中的工具通常侧重于信息获取和处理:
- 检索工具 (Retrieval Tools):
- 向量数据库检索器 (Vector Store Retriever)
- 关键词检索引擎 (Keyword Search Engine)
- 知识图谱查询工具 (Knowledge Graph Querier)
- SQL 数据库查询工具 (SQL Database Querier)
- Web 搜索引擎 (e.g., DuckDuckGo, Google Search API)
- 数据处理工具 (Data Processing Tools):
- 代码解释器 (Code Interpreter, e.g., Python REPL) 用于数据分析、计算。
- 文本处理工具 (e.g., summarizer, entity extractor)。
- API 调用工具 (API Callers): 用于与外部服务交互。
- 检索工具 (Retrieval Tools):
实现: LangChain 中的
Tool对象,每个工具都有名称、描述 (给 LLM 看) 和执行逻辑。
动态检索与查询模块 (Dynamic Retrieval & Query Module):
- 角色: 负责执行实际的检索操作,并根据 Agent 的指令进行动态调整。
- 功能:
- 查询生成/重写 (Query Generation/Rewriting): 根据 Agent 的规划或反思结果,生成或修改检索查询。
- 多源检索 (Multi-source Retrieval): 从不同的数据源(向量库、文本文件、数据库、网页)获取信息。
- 迭代检索 (Iterative Retrieval): 支持多轮检索,逐步缩小范围或探索不同方面。
- 结果融合与排序 (Result Fusion & Ranking): (可选) 如果从多个来源或通过多种方式检索,需要将结果进行合并和排序。
- 实现: 通常是检索器 (Retriever) 的组合和封装,由 Agent 控制其行为。
反思/评估模块 (Reflection / Evaluation Module):
- 角色: 对检索到的信息或 Agent 的中间步骤进行评估,判断其质量和对任务的贡献。
- 功能:
- 相关性评估: 判断检索到的内容是否与当前子问题或整体目标相关。
- 充分性评估: 判断当前信息是否足以回答问题或完成子任务。
- 准确性/一致性检查: (更高级) 尝试发现信息中的矛盾或不准确之处。
- 生成反馈: 将评估结果反馈给 LLM Agent,以便其调整计划。
- 实现: 可以通过让 LLM Agent 自我提问、自我批评 (Self-Critique Prompts),或者使用一些启发式规则,甚至训练一个专门的评估模型。
执行器/控制器 (Executor / Controller):
- 角色: 驱动整个 Agentic RAG 的工作流程,协调各个组件的交互。
- 功能:
- 接收用户输入。
- 调用规划器(或让 LLM Agent 规划)。
- 根据计划调用工具。
- 管理记忆模块。
- 将工具输出和记忆信息传递给 LLM Agent 进行反思和下一步决策。
- 循环执行,直到任务完成或达到停止条件。
- 实现: LangChain 中的
AgentExecutor或类似的编排逻辑。
这些组件如何协同工作 (简化流程):
- 用户提出一个复杂问题。
- LLM Agent (大脑) 和 规划器 理解问题,将其分解,并制定初步的检索计划。
- 根据计划,LLM Agent 选择一个工具 (例如,Web 搜索引擎) 并生成查询。
- 动态检索模块 执行查询,获取初步结果。
- 结果存入记忆模块 (短期记忆)。
- LLM Agent 和 反思/评估模块 分析检索结果:是否相关?是否足够?
- 如果信息不足或不佳,LLM Agent 可能会调整计划 (例如,修改查询、尝试不同工具、或进一步分解问题),然后回到步骤 3 或 4。这个过程可能会迭代多次。
- 当 LLM Agent 认为收集到足够的高质量信息后,它会进行信息综合,并生成最终答案。
- 整个过程由执行器/控制器驱动。
24.在Agentic-RAG中,代理模块如何决定检索哪些文档?
代理模块通常基于以下几个因素决定检索哪些文档:
- 查询理解:分析用户查询的意图和需求。
- 上下文信息:考虑之前的交互历史和上下文。
- 检索策略:应用预定义或动态优化的检索策略,如基于关键词、语义相似度或学习到的模型。
- 资源管理:评估可用的计算资源和时间限制,选择最优的检索方式。
25.Agentic RAG如何处理检索到的信息以生成高质量的回答?
Agentic RAG通过以下步骤处理检索到的信息:
- 信息筛选与排序:根据相关性和重要性对检索到的文档进行筛选和排序。
- 信息融合:将多篇文档中的相关信息进行整合,避免冗余和冲突。
- 生成优化:利用生成模型(如GPT)将整合后的信息转化为连贯、准确的自然语言回答,同时确保信息的完整性和可信度。
26.请解释Agentic-RAG中的自主学习机制是如何工作的?
Agentic RAG的自主学习机制通常包括以下几个步骤:
- 反馈收集:获取用户对生成回答的反馈,如评分、修正或确认。
- 性能评估:自动评估系统性能,识别不足之处。
- 模型更新:利用反馈数据对检索模型、生成模型或代理策略进行微调或优化。
- 策略调整:根据评估结果动态调整检索和生成策略,以提高未来任务的性能。
27.Agentic-RAG在哪些实际应用中具有优势?请举例说明。
Agentic RAG在以下应用中具有显著优势:
- 智能客服:能够理解用户复杂的问题,从多个知识库中检索相关信息,并生成准确、自然的回答。
- 医疗诊断辅助:检索患者的历史记录和相关医学文献,生成综合诊断建议。
- 法律咨询:分析法律条文和案例,为用户提供精准的法律意见。
- 教育辅导:根据学生的学习情况,检索相关学习资料并生成个性化的辅导内容。
28.在多轮对话中,Agentic-RAG如何保持上下文一致性和信息连贯性?
Agentic RAG在多轮对话中通过以下方式保持上下文一致性和信息连贯性:
- 上下文跟踪:维护一个动态的上下文记忆,记录对话历史和关键信息。
- 检索整合:在每一轮对话中,结合当前查询和历史上下文进行检索,确保信息的连续性。
- 生成优化:在生成回答时考虑之前的交互内容,确保回答的连贯性和相关性。
- 代理决策:利用代理模块动态调整检索和生成策略,以适应对话的发展和变化。
29.Agentic-RAG面临的主要挑战有哪些?如何应对这些挑战?
主要挑战包括:
- 检索效率:在大规模数据中快速准确地检索相关信息。
- 应对:采用高效的索引结构和检索算法,如近似最近邻搜索(ANN)。
- 信息质量:确保检索到的信息准确、相关且最新。
- 应对:引入信息筛选和验证机制,定期更新知识库。
- 生成准确性:生成内容需高度准确且与检索信息一致。
- 应对:优化生成模型,结合检索到的信息进行细粒度控制。
- 系统复杂性:集成多个模块导致系统复杂,难以维护和扩展。
- 应对:采用模块化设计,使用标准化接口和自动化工具。
30.如何评估Agentic-RAG系统的性能?有哪些关键指标?
评估Agentic RAG系统的性能可以采用以下关键指标:
- 检索准确率:检索到的文档与用户需求的相关性。
- 生成质量:生成回答的流畅性、准确性和相关性,常用指标如BLEU、ROUGE、BERTScore。
- 用户满意度:通过用户反馈评分或满意度调查评估系统表现。
- 响应时间:系统处理查询和生成回答的速度。
- 鲁棒性:系统在处理复杂或模糊查询时的表现。
- 自适应能力:系统在动态环境和多轮对话中的适应性和稳定性。
31.在设计Agentic-RAG时,如何平衡检索与生成模块的权重?
平衡检索与生成模块的权重可以通过以下方法实现:
- 联合训练:同时优化检索和生成模块,使两者相互促进,提升整体性能。
- 反馈循环:利用生成模块的输出作为检索模块的反馈,动态调整检索策略。
- 权重调节:根据任务需求和应用场景,动态调整检索和生成模块的决策权重。
- 模块化设计:保持检索和生成模块的独立性,通过中间层(如代理模块)进行协调和优化。
- 实验验证:通过大量实验和评估,找到最佳的权重组合,以满足不同应用场景的需求。
2.提示工程
1.零样本提示(Zero shot)是什么?
原则:与大模型交互的提示仅包含指令,不包含任何示例。
应用:一般性问题(文本翻译,摘要总结等)。
论文:[A Survey of Zero-Shot Learning] (https://dl.acm.org/doi/10.1145/3293318)
例:
请将以下内容翻译成为英文。
内容: 我爱看三年面试五年模拟。
2.少样本提示(Few shot)是什么?
原则:提示中包含少量示例,旨在通过例子作为上下文来引导大模型的响应。
应用:需要上下文学习的问题(文本仿写,格式约束等)。
论文:Language Models are Few-Shot Learners
例:
《三年面试五年模拟》太棒了 // Positive
内容对小白很友好哇 // Positive
学习的时候网络十分糟糕 // Negative
请问”多么优秀的知识分享项目”是Positve还是Negative?
3.思考链提示(Chain of thought, COT)是什么?
原则:提示包括相似问题的思维过程或中间推理步骤。
应用:包含多步推理的问题(数学推导等)。
论文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
例:
这组数中奇数位的数加起来是偶数还是奇数:6, 8, 12, 0, 17, 5, 3。
A:找出所有奇数位的数,是6, 12, 17, 5。将它们相加6+12+17+5
=18+17+5=35+5=40。答案为True。
请问这组数中偶数位的数加起来是偶数还是奇数:5, 7, 0, 19, 35, 7, 5
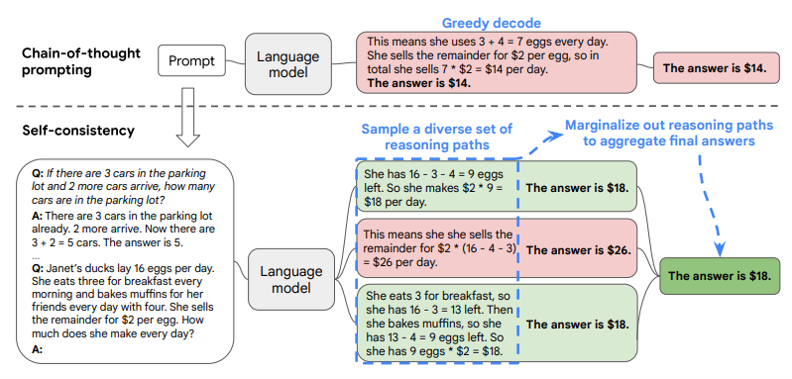
4.自我一致性(Self-consistency)是什么?
原则:通过少样本COT提示生成多个推理路径,选择最一致的结果作为大模型的响应。
应用:包含多步推理的复杂问题(数学推导等)。
论文:Self-Consistency Improves Chain of Thought Reasoning in Language Models
例:
5.ReAct提示 (Reasoning and action, ReAct)是什么?
提示工程 (Prompt Engineering) 框架,旨在让大型语言模型 (LLM) 能够交错地生成推理轨迹 (reasoning traces) 和任务特定的行动 (actions)。这种方式使得 LLM 在解决复杂问题时,能够更有效地进行动态推理、规划、工具使用和从错误中学习。
原则:以交错的方式生成COT推理轨迹和特定于任务的动作,从而实现两者之间更大的协同作用。
应用:包含多步推理的复杂问题(数学推导等)。
论文:ReAct: Synergizing Reasoning and Acting in Language Models
例:
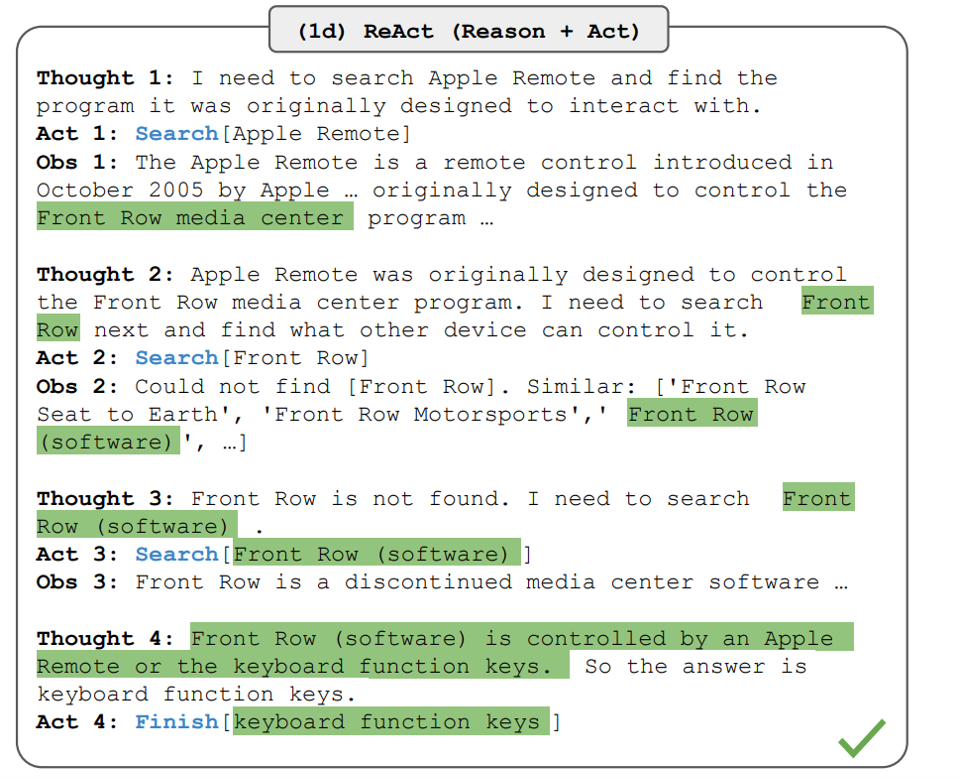
6.思维树提示 (Tree of thought, TOT)是什么?
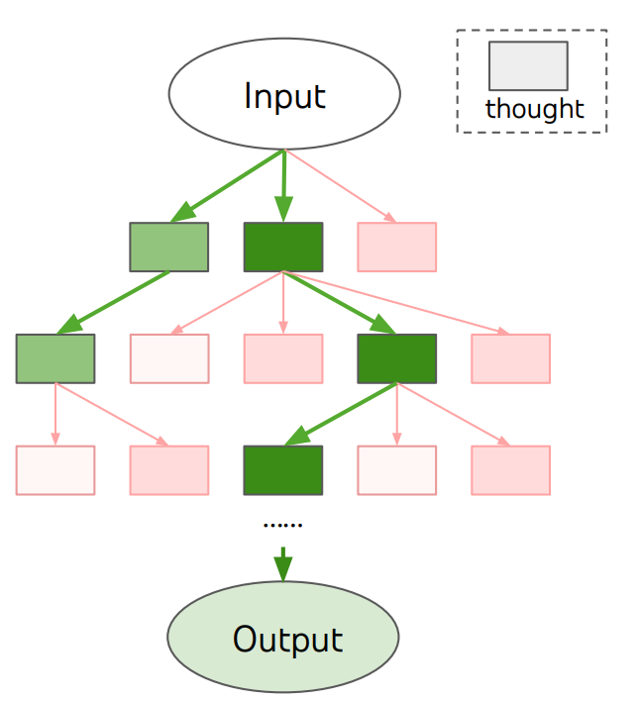
原则:采用树结构考虑多种不同的推理路径和自我评估来决定下一步的行动方案,并在必要时进行选择回溯。
应用:包含多步推理的复杂问题(数学推导等)。
论文:Tree of Thoughts: Deliberate Problem Solving with Large Language Models
例:
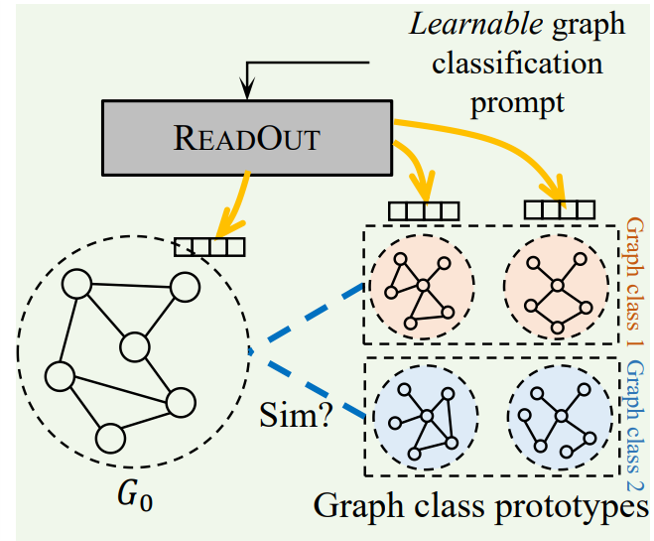
7.基于图的提示 (Graph prompting)是什么?
原则:使用图结构存储和查询相关知识,并生成合适的提示。
应用:图相关问题。
为什么使用图结构进行提示?
- 显式表达关系: 图能够清晰地展示实体间的多种关系(例如,”is-a”, “part-of”, “causes”, “related-to”),这是线性文本难以高效表达的。
- 上下文聚合: 图可以将相关的上下文信息聚合在局部结构中,帮助 LLM 关注与当前推理步骤最相关的信息。
- 结构化推理引导: 图的结构可以为 LLM 的推理过程提供一种“脚手架”,引导其沿着图中的路径进行多跳推理 (multi-hop reasoning)。
- 处理复杂依赖: 对于涉及复杂依赖关系和相互作用的任务(如知识图谱问答、推荐系统、程序理解),图结构是天然的表示方式。
- 减少信息冗余: 图可以通过共享节点来避免重复提及相同实体,使提示更紧凑。
- 整合异构信息: 图可以方便地整合来自不同来源或不同类型的结构化和半结构化信息。
如何将图结构呈现给 LLM?
由于 LLM 主要处理文本,将图结构输入给它们需要进行转换:
- 三元组列表 (Triple Lists):
(subject, predicate, object),例如(Paris, isCapitalOf, France)。 - 邻接列表 (Adjacency Lists): 对于每个节点,列出其所有邻居节点和连接它们的边。
- 自然语言描述: 用自然语言描述图的结构和内容,例如:“节点 A 通过‘连接到’关系连接到节点 B 和节点 C。节点 B 的属性是 X。”
- 专门的图描述语言: 类似于 GraphML, GML, DOT 等语言的简化文本版本。
- 线性化的路径/子图: 提取图中的重要路径或子图,并将其转换为文本序列。
- 三元组列表 (Triple Lists):
论文: GraphPrompt: Unifying Pre-Training and Downstream Tasks for Graph Neural Networks
例
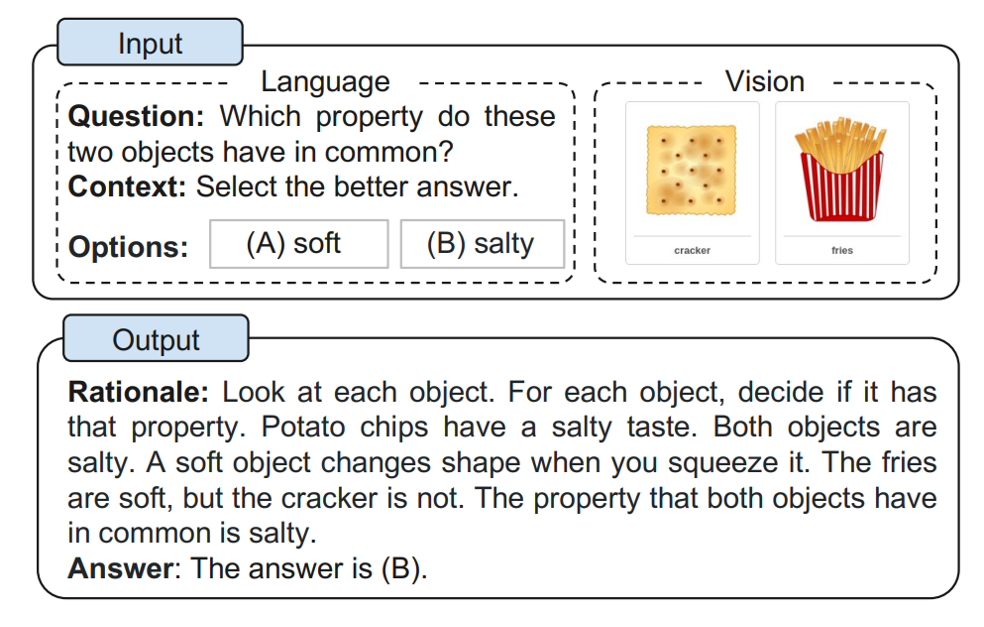
8.多模态思维链提示 (Multimodel COT)是什么?
原则:将COT提示拓展到多模态(文本,图像)
应用:多模态的多步推理问题。
论文:Multimodal Chain-of-Thought Reasoning in Language Models
例:
1.视觉问答场景示例:
输入:
- 图片:显示一个杂乱的客厅场景
- 问题:”房间里最需要整理的是什么?”
思维链过程:
Step 1: 场景分析
- 视觉识别:扫描整个场景
- 定位关键元素:沙发、茶几、地板等
- 评估杂乱程度:每个区域的混乱状况
Step 2: 问题分解
- 任务目标:找出最需要整理的区域
- 评估标准:1) 杂物数量 2) 影响程度 3) 整理优先级
Step 3: 详细推理
- 沙发区域:衣物散落(严重度:7/10)
- 茶几表面:杂志和餐具混放(严重度:8/10)
- 地板状况:玩具分散(严重度:6/10)
Step 4: 得出结论
答案:茶几区域最需要整理,因为:
- 杂物混合程度最高
- 影响日常使用最大
- 整理难度适中
2.多媒体教育内容分析示例:
输入:
- 视频:一段物理实验视频
- 音频:教师讲解
- 文本:实验步骤说明
- 问题:”实验中可能的错误点在哪里?”
思维链过程:
Step 1: 多模态信息整合
- 视频分析:观察实验操作过程
- 音频处理:提取教师重点提示
- 文本理解:对照标准实验步骤
Step 2: 交叉验证
- 视频vs文本:对比实际操作与标准步骤
- 音频vs操作:检查是否符合口头指导
- 时序对应:确认各步骤时间点
Step 3: 问题定位
- 时间点 1:23:仪器摆放不稳定
- 时间点 2:45:测量读数角度不当
- 时间点 3:12:记录数据不完整
Step 4: 综合分析
答案:主要错误点:
- 仪器稳定性问题(高风险)
- 测量精度误差(中等影响)
- 数据记录疏漏(可补救)
9.程序辅助语言模型提示(Program-Aided Language Models)是什么?
原则:使用 LLM 读取自然语言问题并生成程序作为中间推理步骤。
论文:PAL: Program-aided Language Models
例:

10.什么是DTG提示方法?
- DTG提示的步骤
(1)清晰明确地说出要求,并给出生成地指导;(2)提供一个合成文本作为候选输出;(3)通过鼓励大模型发现潜在错误,并进行自我思考改进输出。ONE-SHOT样本如下所示:

核心:强调错误检测而不是即时响应
效果:在语言翻译, 摘要生成,风格转化上面优于大多数提示工程。
3.推理优化
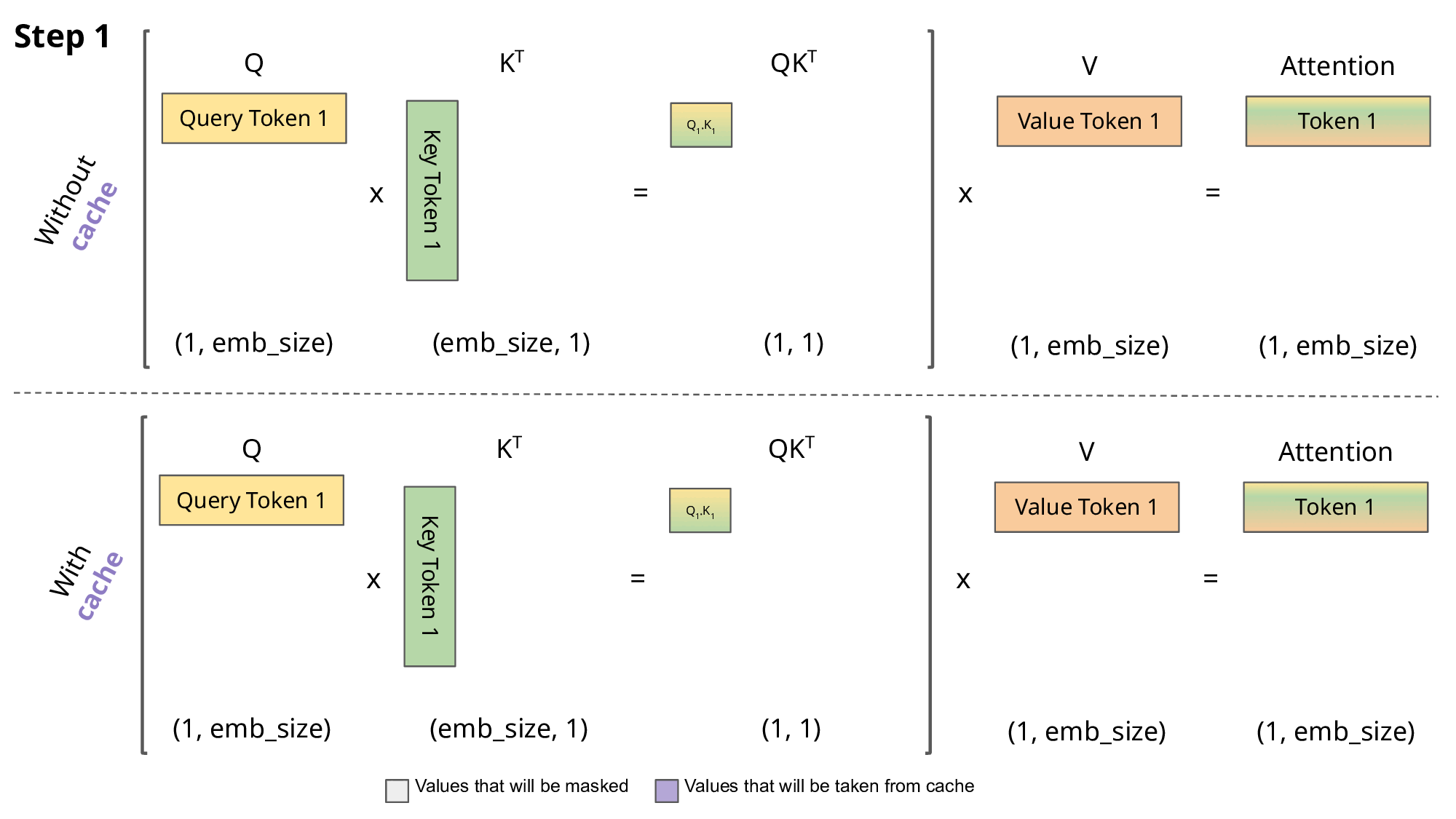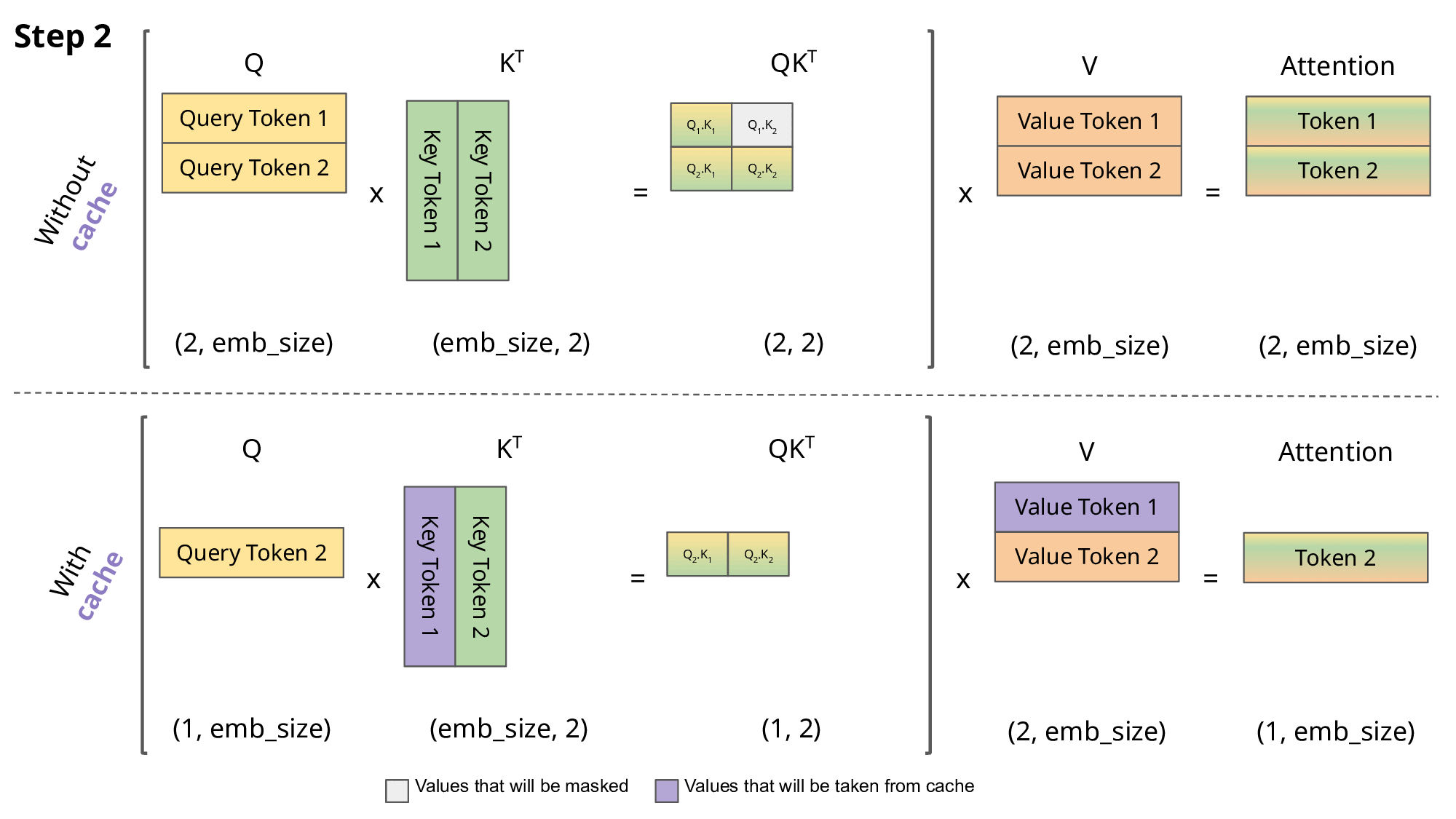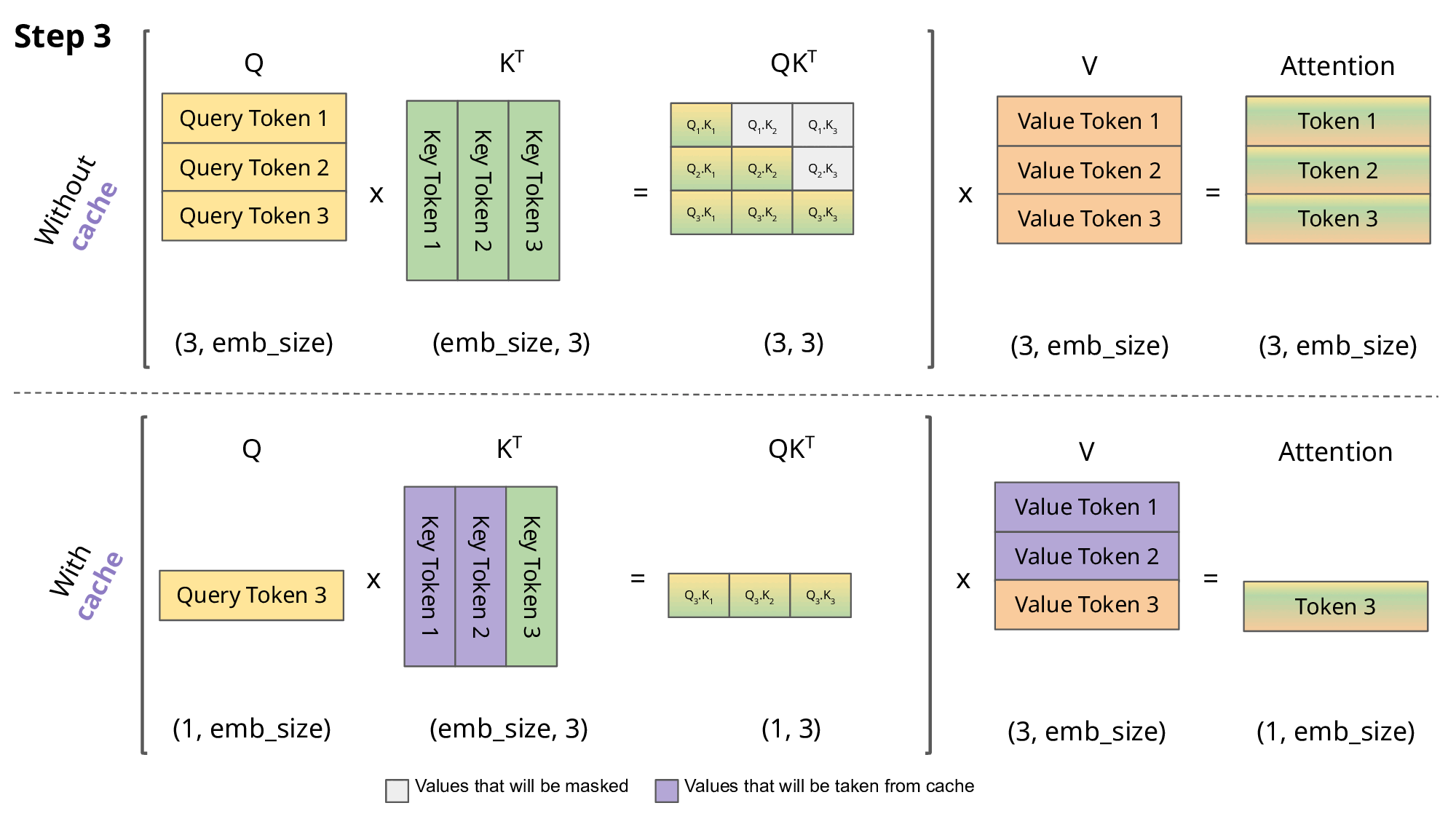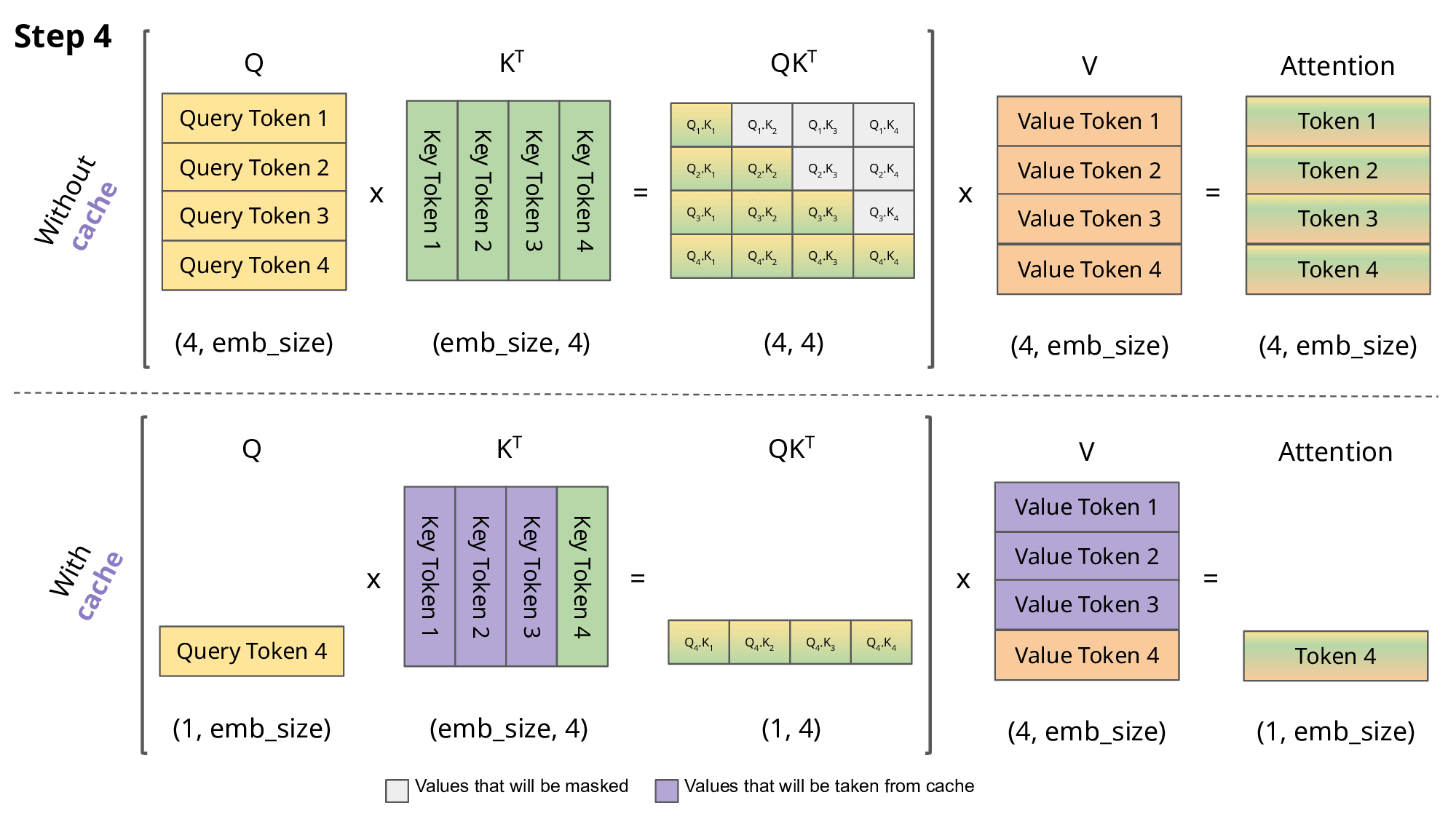
1.简要介绍一下KV-Cache
对于单个样本来说,生成式模型是next token prediction,随着序列变长,next token预测成本越来越高,FLOPs越来越大。但实际上它们重复计算了很多previous tokens。
KV-Cache的作用就是将计算过的token缓存起来不再重复计算。
假设没有KV-Cache,则next token prediction遵循如下伪代码。
1 | EOS_token = torch.tensor([198]) |
1 | EOS_token = torch.tensor([198]) |
如果一个mini-batch内的样本共享相同的meta/system prompt或图像,则可以先统一做一次预填充,再通过past_key_value参数传入generate的方式实现不同样本间的KV-Cache。
2.kv-cache的作用
什么是kv-cache
KV Cache是一种缓存技术,通过存储键值对的形式来复用计算结果,以达到提高性能和降低内存消耗的目的。在大规模训练和推理中,KV Cache可以显著减少重复计算量,从而提升模型的推理速度。
工作原理
KV Cache的核心思想是以空间换时间。在推理过程中,模型会根据输入数据计算出相应的输出结果,并将这些结果存储在缓存中。当遇到相同的输入时,可以直接从缓存中获取结果,避免了重复计算。通过这种方式,KV Cache能够显著降低计算压力,提高推理性能。
为什么没有Q-cache
Q矩阵通常是由模型输入计算得出的,每次都不同,无法进行缓存
3.llama-index和LangChain的区别和联系
LlamaIndex的重点放在了Index上,也就是通过各种方式为文本建立索引,有通过LLM的,也有很多并非和LLM相关的。LangChain的重点在 Agent 和 Chain 上,也就是流程组合上。可以根据你的应用组合两个,如果你觉得问答效果不好,可以多研究一下LlamaIndex。如果你希望有更多外部工具或者复杂流程可以用,可以多研究一下LangChain。
尽管它们侧重点不同,但 LlamaIndex 和 LangChain 并非互斥,而是高度互补的。在实际开发中,它们经常被一起使用:
- LlamaIndex 作为 LangChain 的一个组件/工具:
- 你可以使用 LlamaIndex 来构建一个强大的检索系统(包括数据加载、索引和检索)。
- 然后,将这个 LlamaIndex 的查询引擎 (Query Engine) 或检索器 (Retriever) 作为 LangChain 智能体 (Agent) 的一个工具 (Tool)。
- 这样,LangChain 智能体在执行任务时,就可以调用 LlamaIndex 的工具来查询外部数据,并将检索到的信息用于生成更准确、更丰富的回答。
- 例如,一个 LangChain 智能体在回答用户关于公司内部政策的问题时,可以调用 LlamaIndex 构建的、索引了公司文档的检索工具来获取相关信息。
- LangChain 提供更广泛的应用框架,LlamaIndex 提供数据能力:
- LangChain 可以处理用户输入、管理对话历史(Memory)、决定调用哪个工具(Agent)、组织最终输出格式等。
- LlamaIndex 则专注于提供核心的“从外部数据中找到相关信息”的能力。
总结:
- LlamaIndex 是一个数据框架,核心是帮助 LLM 理解和利用外部数据,擅长构建基于 RAG 的问答系统。
- LangChain 是一个应用框架,核心是编排各种组件构建复杂的 LLM 应用,擅长构建多步骤、多功能的智能体和工作流。
4.llama-factory简单介绍
LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调,框架特性包括:
模型种类:LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等等。
训练算法:(增量)预训练、(多模态)指令监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等等。
运算精度:16 比特全参数微调、冻结微调、LoRA 微调和基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
优化算法:GaLore、BAdam、DoRA、LongLoRA、LLaMA Pro、Mixture-of-Depths、LoRA+、LoftQ 和 PiSSA。
加速算子:FlashAttention-2 和 Unsloth。
推理引擎:Transformers 和 vLLM。
实验面板:LlamaBoard、TensorBoard、Wandb、MLflow 等等。
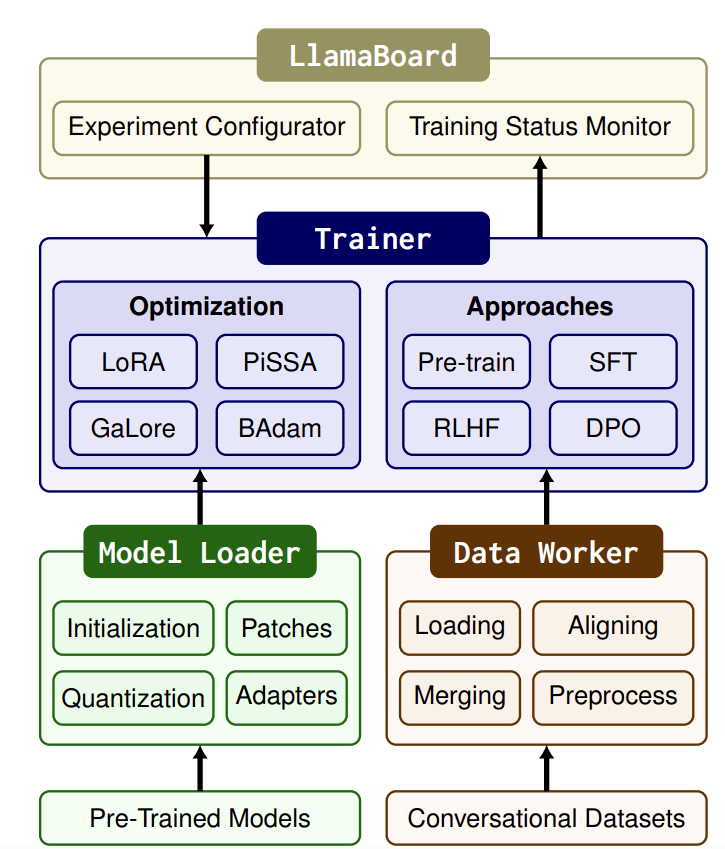
Llama-Factory 的设计目标是简化大语言模型(LLM)的微调和推理过程,其架构涵盖了从模型加载、模型补丁、量化到适配器附加的全流程优化。这种模块化的设计不仅提升了微调的效率,还确保了在不同硬件环境下的高性能运行。
- 模型加载与初始化
Llama-Factory 采用 Transformer 框架的 AutoModel API 进行模型加载,这一方法支持自动识别和加载多种预训练模型。加载过程中,用户可以根据具体任务需求调整嵌入层的大小,并利用 RoPE scaling 技术(旋转位置编码缩放)来处理超长上下文输入。这确保了模型在处理长文本时依然能够保持高效和准确。
- 模型补丁(Model Patching)
为了加速模型的前向计算,Llama-Factory 集成了 flash attention 和 S2 attention 技术。这些技术通过优化注意力机制的计算方式,大幅提升了模型的计算效率。此外,Llama-Factory 采用 monkey patching 技术,进一步优化了计算过程,特别是在处理大规模模型时表现尤为出色。这些优化手段不仅缩短了训练时间,还减少了资源消耗。
- 模型量化
模型量化是 Llama-Factory 的另一大亮点。它支持 4位和8位量化(LLM.int8 和 QLoRA),通过减少模型权重的比特数,显著降低了内存占用。这不仅使得在资源受限的设备上进行模型微调成为可能,还在不显著影响模型精度的前提下,提升了推理速度。量化技术的应用,使得 Llama-Factory 能够在更广泛的硬件环境中高效运行。
- 适配器附加
适配器(Adapter)技术允许在不大规模调整模型参数的情况下,实现对模型的高效微调。Llama-Factory 自动识别并附加适配器,优化了微调性能,同时减少了内存消耗。这种方法不仅提高了模型的灵活性,还使得在多任务场景下,能够快速切换和适应不同的任务需求。
5.Agent应用
1.什么是大模型Agent?其核心能力与传统AI系统有何区别?
大模型Agent的定义
大模型Agent是一种基于大型语言模型(LLM)构建的智能体,它结合了强大的语言理解和生成能力,并具备自主感知、决策和执行任务的能力。大模型Agent可以被视为一个具有“大脑”(LLM)和“手脚”(工具使用和执行能力)的完整系统。
大模型Agent的核心能力
大模型Agent的核心能力包括以下几个方面:
环境感知:通过传感器或其他方式获取环境信息,例如语音识别、图像识别等。
决策制定:基于感知信息和内部逻辑,做出合理的决策,包括长期规划和风险评估。
动作执行:将决策转化为具体行动,例如控制设备、发送消息或执行任务。
记忆能力:存储短期和长期记忆,支持未来的行动决策。
工具使用:与外部工具(如API、数据库)交互,扩展自身能力。
多模态处理:处理多种类型的数据(如文本、图像、语音),并综合这些数据做出决策。
与传统AI系统的区别
大模型Agent与传统AI系统的主要区别如下:
模型规模与复杂度:
大模型Agent:通常包含数十亿甚至数万亿参数,模型复杂,需要大量计算资源。
传统AI:模型规模较小,参数数量少,计算资源需求低。
泛化能力:
大模型Agent:具有强大的泛化能力,能够处理多种任务和场景。
传统AI:通常针对特定任务优化,泛化能力较弱。
任务范围:
大模型Agent:可以处理多种自然语言处理任务,如文本生成、问答、翻译等,并具备多模态处理能力。
传统AI:通常专注于特定领域的简单任务,如图像识别或语音识别。
持续学习能力:
大模型Agent:支持持续学习,能够适应新数据和新场景。
传统AI:通常需要重新设计和训练模型以适应新任务。
可解释性与透明度:
大模型Agent:由于模型复杂,可解释性较差。
传统AI:结构简单,可解释性较高。
交互方式:
大模型Agent:支持多样化交互,包括文本、语音、视觉等。
传统AI:主要通过文本或特定接口交互。
总结:
大模型Agent通过结合强大的语言模型和自主行动能力,能够在复杂环境中完成多种任务。与传统AI系统相比,它在泛化能力、任务范围和持续学习能力上有显著优势,但也面临可解释性和计算资源需求的挑战。
2.如何设计一个支持多轮对话的Agent?需考虑哪些关键技术模块?
设计一个支持多轮对话的Agent需要考虑多个关键技术模块,以下是其核心模块及设计要点:
对话管理模块
对话管理是多轮对话系统的核心,负责控制对话流程、维护对话状态以及选择合适的响应策略。基于大模型的对话管理模块可以通过学习大量对话数据,自动优化对话策略,使系统能够在不同情境下做出恰当的回应。此外,对话管理还需要处理多轮对话中的上下文关系,确保系统能够连续、准确地回答用户的问题。知识图谱与实体链接
知识图谱为对话系统提供了丰富的背景知识库,有助于系统更准确地理解用户意图并给出相关信息。通过实体链接技术,系统可以将用户提到的实体与知识图谱中的实体进行关联,从而实现对话内容的深度理解和推理。自然语言处理模块
自然语言处理(NLP)模块是Agent理解用户输入的基础。它需要具备以下功能:意图识别:准确判定用户输入的意图,支持自定义意图扩展。
槽位填充:动态识别并填充关键信息(如时间、地点、对象等)。
情感分析:识别用户情绪,使Agent能够以更加人性化的方式与用户交流。
状态管理模块
状态管理模块负责跟踪对话的上下文信息,确保在多个回合的对话中能够准确理解用户的意图和槽位信息。例如,LangChain通过状态流图(State Graph)来管理多轮对话,将用户输入和对话状态结合在一起,动态调度模型调用或其他任务。模型调用与工具集成模块
Agent需要根据用户输入调用合适的模型或工具来生成响应。例如,LangChain的LangGraph框架通过图结构管理任务流,将模型调用、工具操作等抽象为节点,并通过边定义任务的流转关系。个性化与定制化模块
根据用户的历史记录和行为习惯,为用户提供个性化的服务和建议。例如,Agent可以根据用户的偏好选择不同的语音音色和风格,或提供符合用户习惯的交互方式。安全与隐私保护模块
确保对话数据的安全和用户隐私的保护。例如,通过数据加密、权限管理和匿名化处理等措施,保障系统的安全性。
应用案例
以智能客服场景为例,多轮对话Agent可以通过以下方式实现高效交互:意图识别与槽位填充:当用户询问“我想预订明天去上海的机票”,Agent通过意图识别确定用户需要预订机票,并通过槽位填充提取出“明天”和“上海”等关键信息。
对话管理:Agent根据对话状态,继续追问用户“您需要预订经济舱还是商务舱?”以获取更多信息。
知识图谱支持:结合知识图谱中的航班信息,Agent可以为用户提供准确的航班选择。
个性化服务:如果用户之前预订过商务舱,Agent可以主动推荐商务舱选项,提供个性化的服务。
通过以上模块的协同工作,多轮对话Agent能够实现高效、智能的交互体验。
3.如何解决大模型Agent的“幻觉”(生成错误事实)问题?
大模型Agent的“幻觉”问题,即生成与事实不符的内容,是当前大模型应用中面临的一个重要挑战。以下是一些解决该问题的方法:
大模型Agent的“幻觉”问题,即生成错误事实或与上下文不一致的内容,是当前生成式人工智能面临的重要挑战之一。以下是几种解决大模型Agent幻觉问题的方法:
调整生成策略
降低温度参数(Temperature):温度参数控制模型生成文本的随机性和创造性。降低温度参数可以减少模型生成多样化内容的倾向,从而降低幻觉现象。
优化解码策略:采用束搜索(beam search)、拓扑抽样(top-k sampling)或核心抽样(nucleus sampling)等策略,平衡生成文本的多样性和准确性。- 束搜索(beam search)工作原理: 在每一步保留概率最高的 K 个可能的序列(束),然后在下一步基于这 K 个序列继续扩展,最终从所有可能的序列中选择概率最高的那个。K 是束宽 (beam width)。
- 特点: 比贪婪搜索能探索更多可能性,通常能找到概率更高的序列。多样性比贪婪搜索高,但仍相对较低,特别是当束宽较小时。
提示工程(Prompt Engineering)
逐步推理提示:要求模型在生成回答时逐步思考,并在回复中提供事实性信息和参考来源。这种方法可以引导模型更谨慎地生成内容。
思维链提示(Chain of Thought Prompting):通过设计更复杂的提示,让模型在生成过程中进行多步推理,从而提高回答的准确性和可靠性。检索增强生成(Retrieval-Augmented Generation, RAG)
结合检索和生成:在生成过程中,通过检索外部知识库中的相关文档或信息,为模型提供更准确的背景知识,从而减少幻觉现象。
动态检索:在推理过程中,从外部知识源中动态检索信息,确保生成内容的时效性和准确性。多智能体协作(如AutoGen)
多智能体相互验证:通过创建多个具有不同角色的智能体,让它们相互协作、共享信息,并相互检查工作。这种方法可以利用多重视角和内置自我纠正机制,降低单个智能体产生错误的风险。
特定领域专业知识:每个智能体可以针对特定知识领域进行微调,确保生成信息的相关性和准确性。模型优化与训练
高质量预训练数据:使用更高质量、更具代表性的数据集进行预训练,减少数据中的错误和偏见。
微调与强化学习:在微调阶段,使用与目标任务更相关的数据集,或采用强化学习方法,进一步优化模型的生成能力。幻觉检测与后处理
可解释性工具:分析生成模型的输出,识别和纠正潜在的幻觉问题。
用户反馈集成:通过用户反馈和持续学习算法,动态调整模型的生成策略,确保内容的可靠性。
通过上述方法的组合使用,可以在一定程度上减少大模型Agent的幻觉现象,提高生成内容的准确性和可靠性。
4.如何让Agent具备长期记忆能力?请列举两种技术方案。
以下是两种可以让Agent具备长期记忆能力的技术方案:
向量数据库存储方案
工作原理:向量数据库是实现AI Agent长期记忆的有效方式。它将信息编码为向量形式进行存储,便于快速检索和访问。Agent可以将需要长期记忆的信息,如用户的历史对话、偏好设置、知识库内容等,经过向量化处理后存储到向量数据库中。当需要回忆信息时,通过向量相似度搜索,快速找到与当前查询最相关的记忆内容。
优势:
高效检索:向量数据库能够支持大规模数据的快速检索,即使存储的信息量很大,也能在较短时间内找到与查询最相关的记忆。
语义理解:基于向量表示的信息存储和检索方式,能够更好地理解记忆内容的语义,而不仅仅是简单的关键词匹配,从而提供更准确的回忆结果。
扩展性强:可以方便地扩展存储容量,以应对不断增长的长期记忆需求。
应用示例:在智能客服场景中,Agent可以通过向量数据库存储用户的历史问题和回答,当用户再次咨询时,快速检索出之前的相关对话,从而提供更连贯和准确的回答结构化数据库与模型参数结合方案
工作原理:一方面利用结构化数据库存储Agent的历史数据、用户偏好、任务记录等信息,这些信息以结构化的形式组织,便于查询和管理。另一方面,通过训练机器学习模型(如推荐算法、强化学习模型等),将用户的行为模式、兴趣偏好等学习到的知识存储在模型的参数中,这些参数可以视为Agent的长期记忆的一部分。在Agent运行过程中,根据当前的输入和上下文,结合数据库中的历史数据和模型参数,做出相应的决策和响应。
优势:
精准个性化服务:模型参数能够捕捉到用户的个性化特征和行为模式,结合结构化数据库中的历史数据,可以为用户提供更加精准的个性化服务和智能推荐。
任务驱动的优化:模型参数可以根据不同的任务需求进行优化和调整,使Agent在特定任务的执行上更加高效和准确。
数据管理方便:结构化数据库使得数据的存储、更新和查询更加规范和高效,便于对Agent的长期记忆进行管理和维护。
应用示例:在智能旅游助手Agent中,通过结构化数据库存储用户的历史旅行记录和偏好设置等信息,同时利用模型参数学习用户的旅行兴趣点和偏好。当用户进行新的旅行规划时,Agent可以结合这些长期记忆的结构化数据和模型参数,快速给出精准的景点推荐和行程规划建议。
5.在工具调用场景中,如何让Agent动态选择最佳工具?
在工具调用场景中,让Agent动态选择最佳工具的关键在于如何根据当前任务需求和上下文信息,智能地调用合适的工具。以下是实现这一目标的几种方法和策略:
- 基于上下文的动态决策
Agent需要根据当前对话的上下文信息来决定调用哪个工具。上下文信息包括用户的历史输入、之前的对话内容、以及当前任务的目标。通过分析这些信息,Agent可以判断出当前最需要的工具。
例如,在LangChain框架中,可以通过定义工具的触发条件和逻辑,让Agent根据上下文动态选择工具。例如,当用户询问旅行目的地时,Agent可以调用get_travel_recommendations工具;当用户需要酒店推荐时,Agent可以调用get_hotel_recommendations工具。 - 强化学习与策略学习
通过强化学习(Reinforcement Learning),Agent可以学习到在不同情境下选择最佳工具的策略。强化学习模型可以根据历史数据和奖励信号,优化工具选择策略,从而在面对新任务时能够做出更合理的决策。
例如,UNICORN模型通过强化学习统一了询问和推荐的决策过程,利用图结构和动态权重图来表示当前对话状态,并通过动作选择模块来决定下一步的动作。 - 多智能体协作与工具传递
在复杂的任务场景中,单个Agent可能无法完成所有任务。此时,可以采用多智能体协作的方式,让不同的Agent专注于不同的任务,并在需要时将任务传递给其他Agent。
例如,在旅行推荐场景中,travel_advisor Agent可以负责推荐旅行目的地,而hotel_advisor Agent可以负责推荐酒店。当travel_advisor Agent需要酒店推荐时,它可以将任务传递给hotel_advisor Agent。 - 工具调用的优先级和条件
为每个工具定义明确的优先级和调用条件,Agent可以根据这些规则动态选择工具。例如,某些工具可能更适合处理特定类型的任务,或者在特定条件下更有效。 - 实时反馈与优化
通过实时收集用户反馈和任务执行结果,Agent可以不断优化工具选择策略。例如,如果某个工具的调用结果不理想,Agent可以调整策略,优先选择其他工具。 - 调试与优化
通过开启调试模式,观察Agent在执行任务时的工具调用过程,可以帮助开发者了解Agent的决策逻辑,并根据实际情况进行优化。
应用案例
假设用户询问:“我想去一个温暖的地方旅行,你能推荐一个目的地吗?”Agent首先调用get_travel_recommendations工具,推荐一个目的地(如“三亚”)。用户接着问:“你能推荐一家不错的酒店吗?”Agent根据上下文,调用get_hotel_recommendations工具,为用户推荐酒店。
通过上述方法,Agent可以在工具调用场景中动态选择最佳工具,从而更高效地完成任务并提供更好的用户体验。
6.如何优化大模型Agent的响应延迟?列举三种工程方法。
优化大模型Agent的响应延迟是提升用户体验和系统性能的关键。以下是三种有效的工程方法:
优化Prompt设计
Prompt设计对响应延迟影响显著。通过优化Prompt,可以减少模型处理的复杂度和Token数量,从而降低响应时间。拆分Prompt:将复杂的Prompt拆分成多个层次,例如将规划和执行分开,分别由不同的Agent处理。这样可以减少每次调用时发送的Token数量,从而降低响应延迟。
约束输出结构:在Prompt中明确指定输出的结构和内容,减少模型生成冗余信息的可能,从而减少输出Token数量。采用流式输出与异步处理
流式输出和异步处理可以显著提升响应速度,让用户更快地看到初步结果。流式输出:将大模型的输出结果分段返回给用户,而不是等待全部结果生成后再返回。例如,可以先返回部分结果,让用户快速了解核心信息,后续再补充详细内容。
异步处理:对于一些可以并行处理的任务,如调用外部API获取数据,可以采用异步方式,减少用户等待时间。合理选择和使用工具
工具的选择和使用方式直接影响响应延迟,需要根据具体任务合理选择。避免过度使用Agent:Agent虽然功能强大,但会显著增加Token消耗和响应延迟。对于一些简单的任务,可以直接使用简单的指令或工具,而不是依赖复杂的Agent。
使用高效工具进行计算:对于数据计算等任务,可以将问题转换为SQL或Python等更高效的工具进行处理,而不是完全依赖大模型。4.优化 LLM 推理速度:
- 选择更快的模型: 使用专门为推理优化的模型版本,或者在性能允许的情况下,使用参数量更小但能力足够完成任务的模型。
- 模型量化 (Quantization): 将模型参数从 FP16/BF16 量化到 INT8 或 INT4 等更低的精度,可以显著减少模型大小和显存占用,从而加速推理。
- 使用高性能推理引擎**:** 利用专门的推理引擎,如 vLLM, TensorRT-LLM, TGI (Text Generation Inference), ONNX Runtime 等,它们通过优化模型加载、批处理、KV Cache 管理、并行计算等技术来加速推理。
- 优化硬件**:** 使用更高性能的 GPU(如 A100, H100)或专门的 AI 推理芯片。
- 批处理 (Batching): 如果 Agent 系统处理并发请求,将多个请求打包成一个批次进行推理可以提高 GPU 利用率,降低平均延迟(尽管单个请求的端到端延迟可能受批次大小影响)。
- KVCache 优化: 高效管理 Attention 机制中的 Key 和 Value 缓存,避免重复计算。vLLM 等推理引擎在这方面做得很好。
- 推测解码 (Speculative Decoding): 使用一个小型、快速的模型预测一部分文本,然后用大型模型验证,可以加速生成过程。
- Prompt 优化: 尝试缩短 Prompt 长度,减少不必要的上下文,有时也能略微加速推理。
通过以上方法,可以在不同场景下有效优化大模型Agent的响应延迟,提升用户体验和系统性能。