AIGC算法高频面试题目
1.携程推荐算法面试题8道
问题1:讲一讲推荐系统包含哪些流程?
推荐系统的流程通常包括以下几个步骤:
- 数据收集:收集用户行为数据(如浏览记录、购买记录、点击记录等)和物品数据(如物品特征、分类、标签等)。
- 数据预处理:对数据进行清洗、归一化、特征提取等预处理操作。
- 特征工程:构建用户画像和物品画像,提取有助于推荐的特征。
- 模型选择:选择合适的推荐算法,如基于内容的推荐、协同过滤、矩阵分解、深度学习等。
- 模型训练:使用历史数据训练推荐模型。
- 推荐生成:根据训练好的模型生成推荐列表。
- 评估与调优:使用评价指标(如准确率、召回率、F1-score等)评估推荐效果,并进行模型调优。
- 上线与更新:将推荐系统上线,并定期更新模型和数据。
使用 7B 模型部署推荐系统,通常不是直接用 LLM 替代整个推荐流程,而是将其作为增强或补充现有推荐系统的一个组件。以下是包含的流程和注意事项:
核心流程:
- 数据准备与处理:
- 用户数据: 用户历史行为(点击、购买、浏览、评分等)、用户画像(年龄、性别、兴趣标签等)、用户输入的查询或偏好描述。
- 物品数据: 物品的详细描述(文本、图片、视频)、类别、标签、价格、销售数据等。
- 交互数据: 用户与物品之间的交互记录。
- LLM 特定的数据处理:
- 将用户行为序列、物品描述等转换为 LLM 可以理解的文本格式。
- 可能需要将图像、视频等非文本数据通过多模态编码器转换为向量表示,供 LLM 使用(如果使用多模态 LLM)。
- 构建用于微调 LLM 的推荐任务数据集(例如,用户历史 + 当前场景 -> 推荐物品列表/解释)。
- LLM 的选择与准备 (7B 模型):
- 选择基础模型: 选择一个合适的 7B 规模的基础模型(如 LLaMA-2 7B, Mistral 7B, Qwen 7B 等)。考虑模型的通用能力、多模态能力(如果需要)、开源许可和社区支持。
- 模型微调 (Fine-tuning) 或适配 (Adaptation):
- 监督微调 (SFT): 在构建好的推荐任务数据集上对 7B 模型进行微调,使其学会理解推荐场景、用户偏好和物品特征,并生成推荐结果或解释。
- 参数高效微调 (PEFT): 使用 LoRA, QLoRA 等方法进行微调,以降低计算资源需求。
- Prompt Engineering: 设计有效的 Prompt 来引导基础模型进行推荐,可能结合 Few-Shot 示例。
- Adapter/Plugin: 将 LLM 作为插件集成到现有推荐系统中,LLM 负责理解复杂查询或生成解释,核心推荐逻辑仍由传统模型处理。
- 集成 LLM 到推荐系统架构:
- 作为召回阶段的增强: LLM 理解用户复杂查询或长尾偏好,生成更相关的关键词或向量,用于从大规模物品库中召回初步的候选集。
- 作为排序阶段的特征: LLM 生成的用户或物品的文本/向量表示,作为传统排序模型的输入特征。或者 LLM 直接对召回的候选集进行重排序,考虑更复杂的上下文和用户意图。
- 作为解释生成器: 在传统推荐模型给出推荐结果后,LLM 根据用户历史、物品特征和推荐结果,生成自然语言的推荐理由或解释。
- 作为对话式推荐的核心: LLM 理解用户的多轮对话,动态调整推荐策略,并与用户进行交互。
- 作为多模态推荐的核心: LLM 结合图像、文本等信息,理解用户对多模态内容的偏好,并推荐多模态物品。
- 部署与推理:
- 选择推理硬件: 7B 模型需要一定的 GPU 资源进行推理。考虑使用高性能 GPU(如 A100, V100, T4 等),并根据并发请求量进行扩容。
- 使用高性能推理引擎: 利用 vLLM, TensorRT-LLM, TGI 等推理引擎来加速 7B 模型的推理速度,降低延迟。
- 模型服务化: 将微调好的 7B 模型部署为可扩展的推理服务(如使用 FastAPI, Flask, Triton Inference Server 等),供推荐系统其他组件调用。
- 延迟优化: 结合前面提到的 LLM 推理优化技术(量化、批处理、KV Cache 等)来降低推荐过程中的 LLM 引入的延迟。
- 评估与迭代:
- 离线评估: 使用传统的推荐系统指标(如准确率、召回率、NDCG 等)以及 LLM 特有的指标(如生成文本的流畅度、相关性、解释的合理性等)进行评估。
- 在线 A/B 测试: 在实际用户流量上进行 A/B 测试,比较集成 LLM 后的推荐系统与基线系统的效果(点击率、转化率、用户满意度等)。
- 用户反馈: 收集用户对推荐结果和解释的反馈,用于进一步优化模型和 Prompt。
注意事项:
- 计算资源需求: 即使是 7B 模型,其微调和推理仍然需要相当的 GPU 资源。需要仔细评估成本和性能需求,选择合适的硬件和推理方案。PEFT 方法可以显著降低微调的资源需求。
- 延迟问题: LLM 推理通常比传统推荐模型慢得多。将 LLM 集成到实时推荐路径中可能会显著增加响应延迟。需要重点优化推理速度,或者将 LLM 用于对延迟不那么敏感的环节(如离线生成解释、辅助召回等)。
- 数据格式与对齐: 将各种模态和结构化数据转换为 LLM 能理解的文本格式是一个挑战。需要设计有效的 Prompt 和数据序列化方法。
- 微调数据的构建: 构建高质量的、针对推荐任务的微调数据集是关键。这可能需要大量的用户行为数据和人工标注来构建 Prompt-Response 对。
- 幻觉与准确性: LLM 可能产生“幻觉”,生成不准确的推荐理由或基于错误信息的推荐。需要通过微调、Prompt Engineering、引入外部知识检索(RAG)以及后处理校验等方法来缓解。
- 可解释性与控制: 虽然 LLM 可以生成解释,但其内部决策过程是黑箱。如何确保 LLM 的推荐逻辑符合业务规则和用户偏好,以及如何控制其生成行为,是一个挑战。
- 冷启动问题: 对于新用户或新物品,LLM 可能因为缺乏足够的交互数据而难以做出准确推荐。可能需要结合传统冷启动策略。
- 公平性与偏见: LLM 可能继承训练数据中的偏见,导致推荐结果不公平。需要关注和缓解模型中的偏见问题。
- 维护与更新: LLM 模型较大,更新和维护成本较高。需要建立有效的模型管理和部署流程。
- 成本效益: 需要评估引入 7B LLM 带来的性能提升是否值得额外的计算和开发成本。
为什么是传统推荐算法的增强或补充,而不是完全替代?
核心原因在于:
- 规模和效率的巨大差异:
- 传统推荐系统: 核心任务是在海量用户(百万、千万、甚至上亿)和海量物品(百万、千万、甚至上亿)之间进行高效匹配。它们依赖于高度优化的算法(如矩阵分解、协同过滤、Embedding 相似度搜索)和数据结构(如向量数据库、倒排索引),能够在毫秒级别内从数百万甚至数亿物品中召回相关的几十到几百个候选。这是它们的核心竞争力。
- 7B LLM: 即使是 7B 这样相对较小的 LLM,其推理计算量仍然远大于传统的推荐模型。在实时推荐场景下,让一个 7B 模型对数百万甚至数亿物品进行打分或排序,其延迟是不可接受的。LLM 的优势在于处理复杂、序列化的文本信息,而不是大规模的向量匹配或矩阵运算。
- 数据处理能力的侧重点不同:
- 传统推荐系统: 擅长处理结构化和半结构化的用户行为数据(点击、购买、评分、浏览时长)、用户画像标签、物品的结构化属性(价格、类别、品牌)以及这些数据之间的协同信号(“喜欢这个物品的用户也喜欢那个物品”)。
- 7B LLM: 擅长处理非结构化文本(用户查询、物品描述、评论)和多模态信息(图像、视频描述)。它们能理解文本的深层含义、用户意图的细微差别、物品描述的丰富细节,并生成自然语言。但将大规模的结构化行为数据直接喂给 LLM 进行端到端处理效率低下且可能丢失信息。
- 实时性要求:
- 推荐系统: 大多数在线推荐场景(如电商首页、短视频流)对响应延迟要求极高,通常需要在几十到几百毫秒内返回结果。
- 7B LLM 推理: 即使经过优化,单次 7B 模型的推理(尤其是生成较长文本或进行复杂思考)也需要几十到几百毫秒,甚至更长。将其串行地用于每个用户的每次推荐请求的核心路径,会严重影响用户体验。
体现在哪些方面是增强或补充?
基于上述原因,7B LLM 通常被集成到推荐系统的不同阶段,发挥其独特的优势,来增强或补充传统方法的不足:
- 增强用户意图理解 (Enhanced User Intent Understanding):
- 体现: 当用户输入自然语言查询(例如:“我想找一件适合春季穿的、颜色鲜艳的、参加户外野餐的连衣裙”)时,传统方法可能只能匹配关键词。LLM 可以理解更复杂的意图、隐含的偏好(“春季”、“户外野餐”对应的场景和功能需求)、甚至情感色彩。LLM 可以将这种复杂意图转化为更精确的查询关键词、物品属性或用户兴趣向量,用于后续的召回或排序。
- 补充了: 传统方法在理解复杂、非结构化用户输入方面的不足。
- 增强物品理解和表示 (Enhanced Item Understanding and Representation):
- 体现: LLM 可以深入分析物品的详细文本描述、用户评论、甚至关联的图像/视频内容(如果是多模态 LLM),提取更丰富、更细粒度的特征或生成高质量的 Embedding。这些特征或 Embedding 可以作为传统推荐模型的输入,或者用于计算物品间的语义相似度,发现传统方法难以捕捉的关联。
- 补充了: 传统方法主要依赖于结构化标签和协同信号,对物品非结构化内容的理解有限。
- 辅助召回 (Assisted Retrieval/Candidate Generation):
- 体现: LLM 可以根据用户当前上下文和意图,生成一些相关的关键词、概念或示例物品。这些生成的内容可以用来扩展用户的查询,或者作为种子,结合向量搜索等技术从大规模物品库中召回更相关的初步候选集。例如,LLM 理解用户想“放松”,可能会生成“瑜伽垫”、“香薰”、“轻音乐”等关键词。
- 补充了: 传统召回方法可能过于依赖直接的历史行为或简单的属性匹配,难以覆盖长尾或跨领域的物品。
- 精细化重排序 (Refined Re-ranking):
- 体现: 传统召回阶段会返回几百到几千个候选物品。LLM 可以对这个相对较小的候选集进行更精细的打分或排序。它可以结合用户历史、当前场景、物品详细信息,进行更复杂的推理(例如,考虑物品描述中的细节是否符合用户隐含的需求,或者判断多个物品组合在一起是否合理),从而优化最终呈现给用户的列表顺序。
- 补充了: 传统排序模型可能难以捕捉所有细微的用户偏好和物品特征交互。
- 生成推荐解释 (Generating Recommendations Explanations):
- 体现: 这是 LLM 在推荐系统中最直接且广泛应用的场景之一。在确定了推荐结果后,LLM 可以根据推荐的物品、用户的历史行为、用户的查询等信息,生成自然语言的解释,告诉用户“为什么推荐这个给你”。例如:“根据您最近浏览的户外装备,我们推荐这款冲锋衣,它的防水透气功能非常适合您下次的徒步旅行。”
- 补充了: 传统推荐系统通常难以提供自然、个性化且有说服力的推荐理由。
- 实现对话式推荐 (Enabling Conversational Recommendation):
- 体现: LLM 是构建对话式推荐系统的核心。它可以理解用户的多轮对话、跟踪用户偏好的变化、询问澄清问题、并以自然流畅的方式提供推荐和解释。
- 补充了: 传统推荐系统通常是单轮的、非交互式的。
问题2:Transformer 位置编码是什么?
Transformer中的位置编码(Positional Encoding)是为了弥补自注意力机制中缺乏顺序信息的缺陷。位置编码有两种常见方式:
固定位置编码:如原始Transformer论文中使用的正弦和余弦函数。每个位置的编码是一个固定的向量,不随训练变化。
- 正弦/余弦位置编码:使用不同频率的正弦和余弦函数来为每个位置生成唯一的编码向量。
可训练位置编码:将位置编码作为可训练的参数,与模型其他参数一起训练。
绝对位置编码 (Absolute Positional Embeddings):
- 核心思想: 为序列中的每一个绝对位置 (0, 1, 2, …,
max_sequence_length - 1) 分配一个独立的可学习的嵌入向量。 - 实现: 创建一个嵌入层 (Embedding Layer),其大小为
(max_sequence_length, d_model)。输入序列中每个词元的词嵌入会与其对应位置的 learned positional embedding 相加。 - 代表模型: BERT, GPT-2 (早期版本), ViT (Vision Transformer) 等。
- 优点:
- 灵活性高: 模型可以根据数据学习到最优的位置表示,可能比固定的函数编码更适合特定任务。
- 实现简单直观。
- 缺点:
- 泛化性问题: 对于超过训练时最大序列长度的序列,模型没有见过相应位置的编码,泛化能力可能受限(尽管有一些插值或外推技术可以缓解)。
- 参数量: 如果最大序列长度非常大,位置编码本身会占用一定的参数量。
- 核心思想: 为序列中的每一个绝对位置 (0, 1, 2, …,
可训练的相对位置编码 (Trainable Relative Positional Encodings):
核心思想: 模型学习的是词元之间相对距离的表示,而不是绝对位置。
实现方式 (多种变体):
- 在自注意力计算中引入偏置项: 在计算注意力分数
q_i^T k_j时,加入一个可学习的偏置项,该偏置项取决于i和j之间的相对距离j-i。例如,为每个可能的相对距离(在一个窗口内,如 -k 到 +k)学习一个标量或向量偏置。 - 修改键 (Key) 或值 (Value) 向量: 根据相对位置来调整键或值向量。
- 在自注意力计算中引入偏置项: 在计算注意力分数
代表模型/思想: Transformer-XL (引入了相对位置编码的思想,其原始实现是固定的,但启发了可训练变体), T5 (使用了简化的相对位置偏置), DeBERTa (使用解耦的注意力和可训练的相对位置编码)。
优点:
- 更好的序列长度泛化性: 因为关注的是相对距离,而不是绝对位置。
- 更自然地捕捉局部依赖关系。
缺点: 实现可能比绝对位置编码更复杂一些
旋转位置编码 (Rotary Positional Embedding - RoPE)让研究人员绞尽脑汁的Transformer位置编码 - 科学空间|Scientific Spaces
RoPE 是一种非常巧妙且目前非常流行的相对位置编码方法。它不是直接学习一个位置嵌入表,也不是简单地在注意力中加入偏置。它的核心在于通过旋转操作将位置信息融入到查询 (Query) 和键 (Key) 向量中。
本质和工作原理:
- 目标: RoPE 的设计目标是让两个词元
x_m和x_n(分别在位置m和n) 的查询向量q_m和键向量k_n之间的内积(点积,用于计算注意力分数)只依赖于它们的相对位置m-n和它们的内容 (词嵌入),而不直接依赖于它们的绝对位置m和n。 - 数学实现 (二维情况简化理解):
- 假设我们有一个二维的词嵌入向量
x = [x_1, x_2]。 - RoPE 会将这个向量与一个位置
m相关联的旋转矩阵R_m相乘:R_m = [[cos(mθ), -sin(mθ)], [sin(mθ), cos(mθ)]]
其中θ是一个预定义的、不可训练的常数(类似于正弦编码中的频率基数)。 - 那么,位置
m处的查询向量q_m可以看作是原始查询内容向量q经过R_m旋转得到的:q_m = R_m * q。 - 同理,位置
n处的键向量k_n可以看作是原始键内容向量k经过R_n旋转得到的:k_n = R_n * k。
- 假设我们有一个二维的词嵌入向量
- 内积的相对性:
- 现在计算
q_m和k_n的内积:q_m^T k_n = (R_m q)^T (R_n k) = q^T R_m^T R_n k - 由于旋转矩阵的性质,
R_m^T R_n = R_{n-m}(即先逆时针旋转m,再顺时针旋转n,等效于顺时针旋转m-n,或者说逆时针旋转n-m)。 - 所以,
q_m^T k_n = q^T R_{n-m} k。 - 关键点: 这个内积的结果只依赖于原始的查询内容
q、键内容k以及它们之间的相对位置n-m(通过旋转矩阵R_{n-m}体现)。绝对位置m和n的影响被消除了,只保留了相对位置信息。
- 现在计算
- 高维扩展:
- 在实际的
d_model维度中,RoPE 将d_model维向量两两配对,对每一对应用上述的二维旋转。不同的配对使用不同的旋转频率θ_i(类似于正弦编码中不同维度的不同频率)。 f(x, m)_i = x_i * cos(mθ_j) + x_{i+1} * (-sin(mθ_j))(如果i是偶数)f(x, m)_{i+1} = x_i * sin(mθ_j) + x_{i+1} * cos(mθ_j)(如果i是偶数,j=i/2)
- 在实际的
- 如何表达位置信息:
- 通过旋转角度: 词元在序列中的绝对位置
m决定了其嵌入向量被旋转的角度mθ。 - 通过相对旋转: 当计算注意力时,查询向量和键向量之间的相对旋转角度 (由
R_{n-m}决定) 编码了它们之间的相对位置。 - 衰减特性 (Implicitly): 随着相对距离
|m-n|的增大,R_{n-m}导致的旋转会使得原始向量q和k之间的对齐关系逐渐减弱(除非它们本身在旋转后恰好对齐)。这在某种程度上实现了注意力分数的“距离衰减”效应,即模型更关注邻近的词元。
- 通过旋转角度: 词元在序列中的绝对位置
RoPE 的优点:
- 良好的序列长度外推性: 由于其相对位置的性质和基于函数的旋转,RoPE 在处理比训练时更长的序列时表现良好。
- 实现相对简单高效: 只需要在查询和键向量上进行元素级的乘法和加法操作。
- 性能优越: 在许多现代 LLM (如 LLaMA, PaLM) 中被证明非常有效。
- 保留了范数: 旋转操作不改变向量的长度(范数)。
- 目标: RoPE 的设计目标是让两个词元
问题3:QKV 注意力公式为什么除以根号 d
除以根号 $( \sqrt{d_k} )$ 的原因是为了防止内积值过大导致softmax函数的梯度消失问题。由于Q和K的维度较高,其内积的值会随 $( d_k )$ 增加而增大,
从而导致softmax的输出极端化(接近0或1)。除以根号 $( \sqrt{d_k} )$ 可以使得内积值的方差接近1,保持梯度稳定。
问题4:简单讲讲 GCN
GCN(Graph Convolutional Network,图卷积网络)是一种用于图数据的神经网络。GCN通过在图的节点上进行卷积操作来提取节点的特征。基本的GCN操作步骤包括:
- 邻接矩阵:用邻接矩阵 ( A ) 表示图结构。
- 节点特征矩阵:用矩阵 ( X ) 表示节点特征。
- 卷积操作:将节点特征与邻接矩阵进行卷积。
问题5:简单讲讲RNN
RNN(Recurrent Neural Network,循环神经网络)是一类用于处理序列数据的神经网络。RNN通过循环结构使得网络可以在序列的每个时间步共享参数,
从而记忆和处理序列中的上下文信息。RNN的基本结构包括:
输入层:接收序列的当前时间步输入。
隐藏层:通过循环连接,将前一时间步的隐藏状态和当前时间步的输入一起处理,生成当前时间步的隐藏状态。
输出层:生成当前时间步的输出。
1. 普通RNN
先简单介绍一下一般的RNN。
其主要形式如下图所示(图片均来自台大李宏毅教授的PPT):
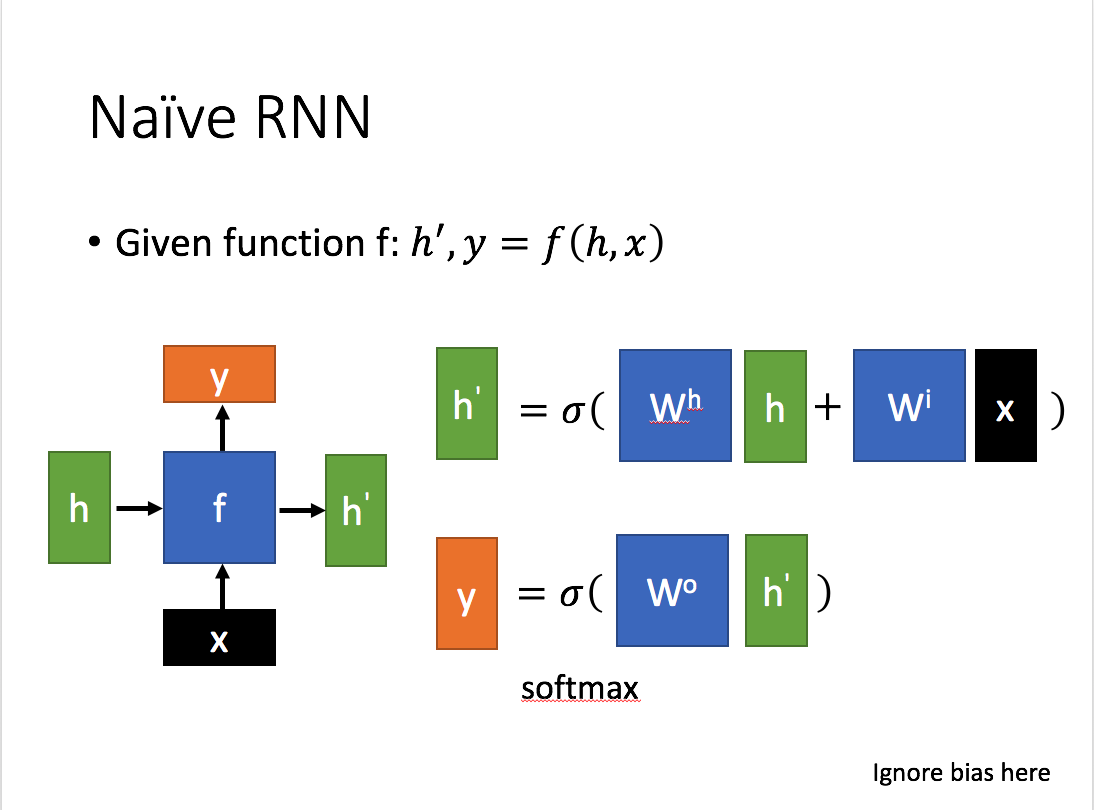
这里:
x 为当前状态下数据的输入, h 表示接收到的上一个节点的输入。
y 为当前节点状态下的输出,而 h′ 为传递到下一个节点的输出。
通过上图的公式可以看到,输出 h’ 与 x 和 h 的值都相关。
而 y 则常常使用 h’ 投入到一个线性层(主要是进行维度映射)然后使用softmax进行分类得到需要的数据。
对这里的y如何通过 h’ 计算得到往往看具体模型的使用方式。
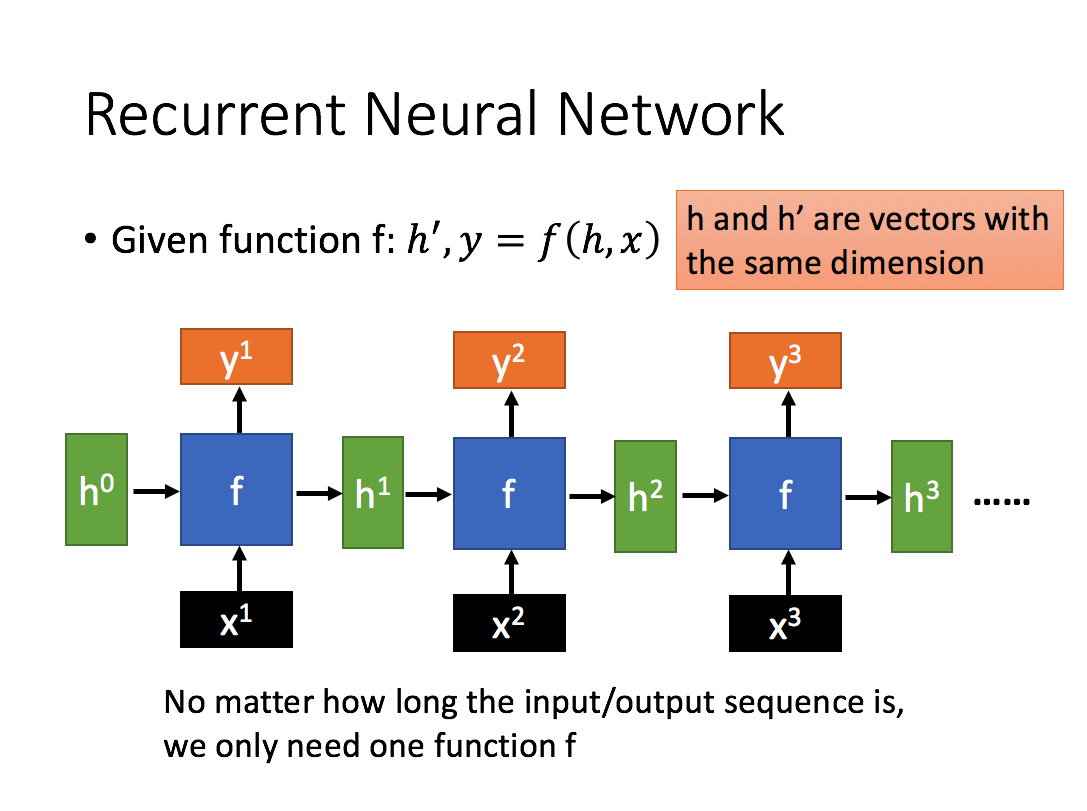
通过序列形式的输入,我们能够得到如下形式的RNN。
2. LSTM
2.1 什么是LSTM
长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。
LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
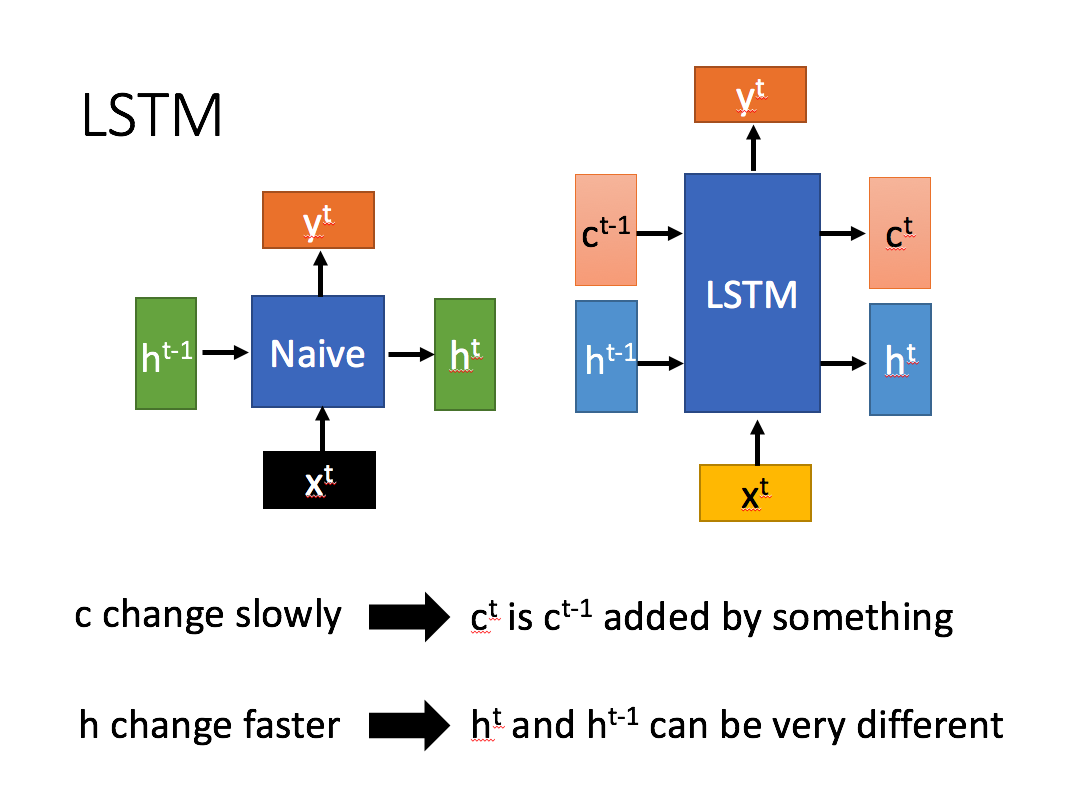
相比RNN只有一个传递状态 ht ,LSTM有两个传输状态,一个 ct (cell state),和一个 ht (hidden state)。(Tips:RNN中的 ht 对于LSTM中的 ct )
其中对于传递下去的 ct 改变得很慢,通常输出的 ct 是上一个状态传过来的 ct−1 加上一些数值。
而 ht 则在不同节点下往往会有很大的区别。
2.2 深入LSTM结构
下面具体对LSTM的内部结构来进行剖析。
首先使用LSTM的当前输入 xt 和上一个状态传递下来的 ht−1 拼接训练得到四个状态。
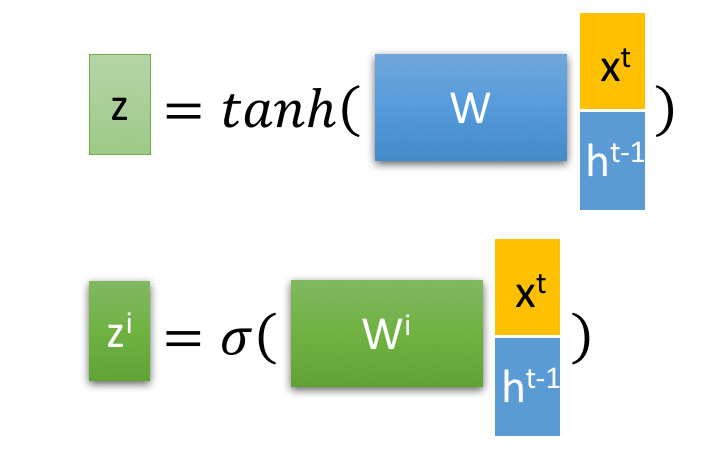
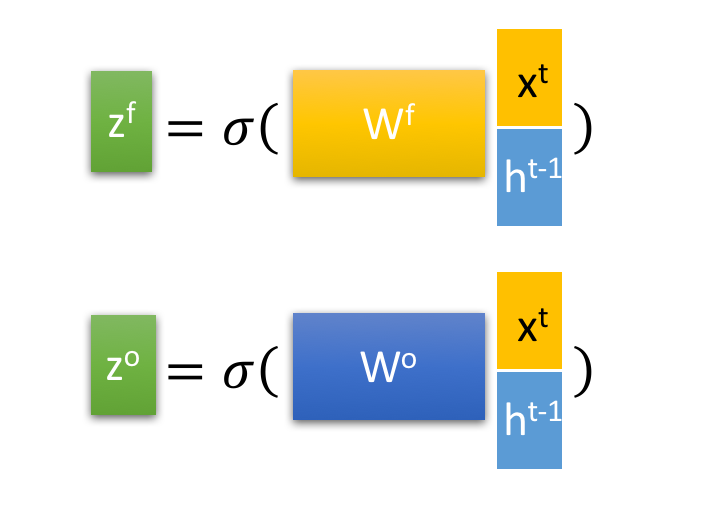
其中, zf , zi ,zo 是由拼接向量乘以权重矩阵之后,再通过一个 sigmoid 激活函数转换成0到1之间的数值,来作为一种门控状态。而 z 则是将结果通过一个 tanh 激活函数将转换成-1到1之间的值(这里使用 tanh 是因为这里是将其做为输入数据,而不是门控信号)。
下面开始进一步介绍这四个状态在LSTM内部的使用。

⊙ 是Hadamard Product,也就是操作矩阵中对应的元素相乘,因此要求两个相乘矩阵是同型的。 ⊕ 则代表进行矩阵加法。
问题6:RNN 里的参数有什么特点?
RNN的参数具有共享性,即在序列的每个时间步使用相同的一组参数。这使得RNN能够有效处理不同长度的序列,并在参数数量固定的情况下学习序列中的时间依赖关系。
问题7:Dropout 是怎么做的?有什么作用?推理和训练时 Dropout 的区别?如果推理也用 dropout 会怎么样?
Dropout是一种正则化技术,通过在训练过程中随机丢弃(即设置为零)一部分神经元来防止过拟合。具体步骤为:
- 在每一层的输出中,以一定的概率 $( p )$ 随机丢弃一些神经元。
- 对保留的神经元进行放大 $( \frac{1}{1-p} )$ ,以保持总的激活值不变。
作用:通过随机丢弃神经元,减少节点之间的相互依赖,从而提高模型的泛化能力。
推理和训练时 Dropout 的区别
- 训练时:应用Dropout,即随机丢弃神经元,并对保留的神经元进行放大。
- 推理时:不应用Dropout,使用完整的网络。
如果推理时也用Dropout,模型的输出将变得不稳定,因为每次推理时网络结构都不同,导致结果不可预测且精度下降。
问题8:讲讲 BN?BN 训练和推理什么区别?有什么用?
Batch Normalization(BN)是一种加速深层神经网络训练并提高其稳定性的方法。BN通过对每一层的输入进行标准化,使得输入具有零均值和单位方差,
同时允许网络学习最优的均值和方差。
训练和推理的区别
- 训练时:使用mini-batch的均值和方差,并更新全局均值和方差的移动平均值。
- 推理时:使用训练过程中计算的全局均值和方差。
作用
- 减少内部协变量偏移(Internal Covariate Shift)。
- 加快训练速度。
- 提高模型的泛化能力。
2. 趣玩科技推荐算法面试题9道
问题1:二分类的分类损失函数?
二分类的分类损失函数一般采用交叉熵(Cross Entropy)损失函数,即 CE 损失函数。二分类问题的 CE 损失函数可以写成:
$$-y \log(p) - (1 - y) \log(1 - p)$$
其中, $y$ 是真实标签, $p$ 是预测标签,取值为0或1。
log 函数在其参数接近 0 时会急剧下降到负无穷。这意味着当模型对一个错误的类别给出了非常高的概率时,损失会变得非常大,从而强烈地惩罚这种“自信的错误”。
问题2:多分类的分类损失函数(Softmax)?
多分类问题一般采用交叉熵损失函数与Softmax激活函数结合使用。多分类问题的交叉熵损失函数可以写成:
$$-\sum_{i=1}^{N} y_i \log(p_i)$$
其中, $N$ 是类别的数量, $y_i$ 是第 $i$ 类的真实标签, $p_i$ 是第 $i$ 类的预测概率。
问题3:关于梯度下降的sgdm,adagrad,介绍一下。
SGD(Stochastic Gradient Descent)是最基础的梯度下降算法,每次迭代随机选取一个样本计算梯度并更新模型参数。
SGDM(Stochastic Gradient Descent with Momentum)在 SGD 的基础上增加了动量项,可以加速收敛。
Adagrad(Adaptive Gradient)是一种自适应学习率的梯度下降算法,它根据每个参数的梯度历史信息调整学习率,可以更好地适应不同参数的变化范围。
问题4:为什么不用 MSE 分类用交叉熵?
MSE ( Mean Squared Error )损失函数对离群点敏感,而交叉熵(Cross Entropy)损失函数在分类问题中表现更好,
因为它能更好地刻画分类任务中标签概率分布与模型输出概率分布之间的差异。
对错误预测的惩罚机制 (Penalty for Wrong Predictions):
交叉熵:
- 当模型对一个错误的类别给出了非常高的概率时,交叉熵损失会变得非常大(趋向于无穷大)。例如,真实标签是 1,模型预测概率
p趋近于 0,则-log(p)趋近于无穷大。 - 这种特性使得模型会强烈地避免对错误类别给出高置信度的预测。
- 当模型对一个错误的类别给出了非常高的概率时,交叉熵损失会变得非常大(趋向于无穷大)。例如,真实标签是 1,模型预测概率
MSE:
- MSE 对所有误差的惩罚是平方的。例如,如果真实标签是 1:
- 模型预测
p=0.1(错误,但不太自信),损失是(0.1-1)^2 = (-0.9)^2 = 0.81。 - 模型预测
p=0.001(错误,且非常自信地认为是类别0),损失是(0.001-1)^2 = (-0.999)^2 ≈ 0.998。
- 模型预测
- 虽然自信的错误惩罚也更大,但与交叉熵相比,其增长速度较慢,并且不会像交叉熵那样趋向于无穷大。在梯度消失的情况下,这种惩罚可能不足以驱动模型快速修正。
- MSE 对所有误差的惩罚是平方的。例如,如果真实标签是 1:
交叉熵: 源于信息论,衡量的是两个概率分布之间的差异。当模型的输出是概率分布时(通过 Softmax),交叉熵自然地衡量了模型预测的概率分布与真实的 one-hot 概率分布之间的“距离”或“不相似度”。
MSE: 最初是为回归问题设计的,衡量的是预测值与真实值之间的平方差。直接将其应用于概率(0到1之间的值)可能不是最自然或最有效的方式来表达分类任务的目标。例如,MSE 假设输出是连续的,并且误差的分布是对称的(高斯分布),这可能不完全符合分类问题中概率的特性。
问题5:yolov5 相比于之前增加的特性有哪些?
YOLOv5 相比于之前版本增加了一些特性,包括:使用 CSP(Cross Stage Partial)架构加速模型训练和推理;采用 Swish 激活函数代替 ReLU;
引入多尺度训练和测试,以提高目标检测的精度和召回率;引入 AutoML 技术,自动调整超参数以优化模型性能。
YOLOv5 最核心的是什么?
如果非要说一个“最核心”的点,我认为是卓越的工程实践和对用户体验的极致追求,最终实现了速度、精度和易用性的高度统一。
具体来说,可以分解为:
- PyTorch 原生实现带来的易用性和灵活性: 这是其能够快速普及和被广泛采用的基础。
- 对现有优秀技术的巧妙融合与优化: YOLOv5 并没有发明很多全新的革命性算法,而是非常聪明地借鉴、融合并优化了当时及后续出现的优秀技术(如 CSPNet、PANet、Mosaic、AutoAnchor 等),并将它们高效地集成到一个统一的框架中。
- 对速度和精度的极致平衡: 继承了 YOLO 系列“快准狠”的特点,并通过模型缩放满足不同场景的需求。
- 以用户为中心的开发理念: 从文档、教程、易用的 API 到快速的迭代和社区支持,都体现了对开发者友好性的重视。
YOLOv5 的成功更多是工程上的胜利,它将许多先进的理念和技术以一种非常高效和用户友好的方式呈现出来,使得最先进的物体检测技术能够被更广泛的开发者和研究人员所使用。它不是一个孤立的算法创新,而是一个精心打磨的、综合性的优秀目标检测框架。
YOLOv5 和 YOLOv8 的主要本质区别:
- 检测头 (Detection Head) 的变化:从耦合到解耦 (Coupled to Decoupled):
- YOLOv5 (及之前的 YOLOv3/v4): 使用的是耦合头 (Coupled Head)。这意味着用于预测边界框坐标、目标置信度(objectness)和类别概率的卷积层是共享的。
- YOLOv8: 采用了解耦头 (Decoupled Head)。用于分类和回归(边界框预测)的卷积层是分开的,有各自独立的路径。
- 本质影响: 解耦头是现代目标检测模型(如 Faster R-CNN, FCOS, YOLOv6, YOLOv7 等)的一个常见趋势。它通常能带来更高的检测精度 (mAP),因为它允许模型更专业地学习分类和回归任务的特征,避免了它们之间的潜在冲突。这是 YOLOv8 提升性能的一个重要因素。
- 检测方式的变化:从基于锚框到无锚框 (Anchor-Based to Anchor-Free):
- YOLOv5: 是一个基于锚框 (Anchor-Based) 的模型。它在每个预测位置预设了不同尺寸和长宽比的锚框,模型预测的是相对于这些锚框的偏移量和缩放比例。
- YOLOv8: 采用了无锚框 (Anchor-Free) 的检测方式。它直接预测目标中心点的位置以及到边界框四条边的距离(左、上、右、下)。
- 本质影响:
- 简化: 无锚框方法消除了预设锚框、计算锚框与真实框的匹配(Anchor Matching)等步骤,简化了训练过程和后处理。
- 灵活性: 无需针对不同数据集调整锚框参数。
- 性能: 无锚框模型在处理不同形状和尺寸的目标时可能更灵活,有助于提升性能。这是 YOLOv8 另一个重要的架构变化。
- 骨干网络 (Backbone) 和颈部网络 (Neck) 的变化:
- YOLOv5: 使用了 CSPDarknet 作为骨干网络,PANet 作为颈部网络。
- YOLOv8: 虽然整体结构类似(骨干+颈部+头),但在具体的模块实现上有所更新。例如,骨干网络中可能使用了 C2f 模块(在 YOLOv6 中引入),颈部网络(PAN-FPN 结构)也可能有一些调整(如 SPPF 模块的变体)。
- 本质影响: 这些模块的更新旨在提高特征提取和融合的效率和能力,为后续的检测头提供更好的输入。虽然不如解耦头和无锚框那样是“范式”上的变化,但也是性能提升的重要组成部分。
- 损失函数 (Loss Functions) 的变化:
- 由于检测方式(无锚框)和头部结构(解耦头)的变化,YOLOv8 使用了不同的损失函数组合。例如,回归损失可能使用了 Distribution Focal Loss (DFL),分类损失可能使用了 VFL (VariFocal Loss) 或 BCE (Binary Cross Entropy)。
- 本质影响: 损失函数的设计与模型架构紧密相关,用于更有效地训练无锚框和解耦头的模型。
- 任务支持:
- YOLOv5: 主要是一个目标检测模型。
- YOLOv8: 被设计成一个更通用的视觉任务框架,除了目标检测,还原生支持实例分割 (Instance Segmentation) 和图像分类 (Image Classification) 任务,使用相同的骨干和颈部,但搭配不同的任务头。
- 本质影响: YOLOv8 不仅仅是一个检测模型的新版本,而是 Ultralytics 构建的一个更全面的视觉 AI 平台的基础。
总结本质区别:
YOLOv8 相对于 YOLOv5 的本质区别主要体现在:
- 从耦合检测头变为解耦检测头: 提升分类和回归的专业性,提高精度。
- 从基于锚框变为无锚框检测: 简化模型,提高灵活性,可能提升性能。
- 骨干和颈部模块的更新: 提高特征处理效率。
- 支持多任务: 不仅是检测,还包括分割和分类。
问题6:可以介绍一下 attention 机制吗?
Attention 机制是一种用于序列建模的技术,它可以自适应地对序列中的不同部分赋予不同的权重,以实现更好的特征表示。
在 Attention 机制中,通过计算查询向量与一组键值对之间的相似度,来确定每个键值对的权重,最终通过加权平均的方式得到 Attention 向量。
问题7:关于 attention 机制,三个矩阵 Q,K,V的作用是什么?
在 Attention 机制中,KQV 是一组与序列中每个元素对应的三个矩阵,其中 K 和 V 分别代表键和值,用于计算对应元素的权重,Q 代表查询向量,
用于确定权重分配的方式。三个矩阵 K、Q、V 在 Attention 机制中的具体作用如下:
- Q(Query)向量:Q 向量是用来确定权重分配方式的向量,与输入序列中的每个元素都有一个对应的相似度,可以看作是一个加权的向量。
- K(Key)矩阵:K 矩阵用于计算每个元素的权重,是一个与输入序列相同大小的矩阵。通过计算查询向量 Q 与每个元素的相似度,
确定每个元素在加权平均中所占的比例。 - V(Value)矩阵:V 矩阵是与输入序列相同大小的矩阵,用于给每个元素赋予一个对应的特征向量。在 Attention 机制中,
加权平均后的向量就是 V 矩阵的加权平均向量。- 假设我们正在处理一个序列(比如一个句子中的词语),并且想计算序列中某个词语(称为当前词)对序列中所有词语的注意力。
- Q (Query) - 查询矩阵:
- 作用: 代表当前正在处理的词语(或更广义地说,当前正在计算其输出的元素)的表示。它就像你提出的“问题”或“查询”。
- 来源: 通常由输入序列中当前词语的 Embedding 经过一个线性变换(乘以一个权重矩阵 W_Q)得到。
- 意义: 决定了“我正在寻找什么信息?”
- K (Key) - 键矩阵:
- 作用: 代表序列中所有词语(包括当前词语本身)的表示,用于与 Query 进行匹配。它就像文档的“关键词列表”或“索引”。
- 来源: 通常由输入序列中所有词语的 Embedding 经过另一个线性变换(乘以一个权重矩阵 W_K)得到。
- 意义: 决定了“我有什么信息可以被查询到?”
- V (Value) - 值矩阵:
- 作用: 代表序列中所有词语(包括当前词语本身)的实际内容或信息表示。它就像文档的“实际内容”。
- 来源: 通常由输入序列中所有词语的 Embedding 经过第三个线性变换(乘以一个权重矩阵 W_V)得到。
- 意义: 决定了“如果我被查询到,我能提供什么信息?”
- Q (Query) - 查询矩阵:
- 假设我们正在处理一个序列(比如一个句子中的词语),并且想计算序列中某个词语(称为当前词)对序列中所有词语的注意力。
通过K、Q、V三个矩阵的计算,Attention机制可以自适应地为输入序列中的每个元素分配一个权重,以实现更好的特征表示。
问题8:介绍一下文本检测 EAST?
EAST(Efficient and Accurate Scene Text)是一种用于文本检测的神经网络模型。EAST 通过以文本行为单位直接预测文本的位置、方向和尺度,
避免了传统方法中需要多次检测和合并的过程,从而提高了文本检测的速度和精度。EAST 采用了一种新的训练方式,即以真实文本行作为训练样本,
以减少模型对背景噪声的干扰,并在测试阶段通过非极大值抑制(NMS)算法进行文本框的合并。
EAST 的核心流程和特点:
端到端: EAST 将文本检测的多个阶段(如文本区域建议、非极大值抑制等)整合到一个统一的神经网络模型中,直接输出最终的文本框。
多尺度特征提取: 使用一个卷积神经网络(CNN)作为骨干网络(如 PVANet, VGG16),提取图像在不同尺度的特征。
特征融合: 采用类似 FPN (Feature Pyramid Network) 的结构,将不同尺度的特征图进行融合,以便检测不同大小的文本。
直接预测:
在融合后的特征图上,通过一个输出层直接预测每个像素点是否属于文本区域,以及该文本区域的几何形状。
Score Map (得分图): 预测每个像素是文本中心的概率。
Geometry (几何形状):
预测文本区域的形状。EAST 支持两种几何形状的预测:
- Rotated Bounding Box (旋转矩形框): 预测文本框的中心坐标 (x, y)、宽度 (w)、高度 (h) 和旋转角度 (angle)。
- Quadrilateral (四边形): 预测文本框四个顶点的坐标 (x1, y1, x2, y2, x3, y3, x4, y4)。
NMS (Non-Maximum Suppression): 在预测出大量的文本区域后,使用非极大值抑制算法去除重叠的、冗余的预测框,得到最终的文本检测结果。
问题9:编程题(讲思路):给定两个字符串 s,t,在 s 字符串中找到包含 t 字符串的最小字符串。
给定两个字符串 s、t,可以采用滑动窗口的方式在 s 中找到包含 t 的最小子串。具体做法如下:
- 定义两个指针 left 和 right,分别指向滑动窗口的左右边界。
- 先移动 right 指针,扩展滑动窗口,直到包含了 t 中的所有字符。
- 移动 left 指针,缩小滑动窗口,直到无法再包含 t 中的所有字符。
- 记录当前滑动窗口的长度,如果小于之前记录的长度,则更新最小长度和最小子串。
- 重复(2)到(4)步骤,直到 right 指针到达 s 的末尾为止。
- 扩展窗口 (Expand): 移动
right指针,将新的字符加入窗口。 - 收缩窗口 (Shrink): 当窗口满足条件时,尝试移动
left指针,缩小窗口,看是否还能保持条件满足。如果仍然满足,说明找到了一个更短的有效子串;如果不满足了,就停止收缩,继续扩展窗口。
- 扩展窗口 (Expand): 移动
3.快手推荐算法面试题7道
问题1:为什么 self-attention 可以堆叠多层,有什么作用?
Self-attention 能够捕捉输入序列中的长距离依赖关系,通过堆叠多层 self-attention,模型可以学习序列中更深层次的模式和依赖关系。
多层 self-attention 就像神经网络中的多个隐藏层一样,使模型能够学习和表示更复杂的函数。
问题2:多头有什么作用?如果想让不同头之间有交互,可以怎么做?
多头注意力(Multi-head attention)的设计是为了让模型同时学习到输入序列的不同表示。每个“头”都有自己的参数,可以学习到不同的注意力分布,
这样可以让模型同时关注不同的特征或信息。至于不同头之间的交互,这通常在所有头的输出被拼接和线性转换之后自然实现。如果你希望在这之前增加交互,
你可能需要设计新的结构或者机制。
问题3:讲一讲多目标优化,MMoE 怎么设计?如果权重为 1,0,0 这样全部集中在某一个专家上该怎么办?
多目标优化是指优化多个目标函数,通常需要在不同目标间找到一个权衡。多门专家混合网络(MMoE, Multi-gate Mixture-of-Experts)
是一种处理多目标优化的方法,其中每个目标都由一个专家网络来处理,而门网络则决定每个专家对最终输出的贡献。如果权重全部集中在某一个专家上,
那么模型的输出就完全由那个专家决定。这可能在某些情况下是合理的,但在大多数情况下,你可能希望各个专家都能对输出有所贡献,
这需要通过训练和调整权重来实现。
如何解决专家坍塌问题?
解决专家坍塌的核心思路是激励门控网络更均匀地利用专家,或者激励专家学习更具区分性的表示。常用的方法包括:
门控输出的正则化 (Gating Output Regularization):
熵正则化 (Entropy Regularization):
在总损失中加入一个项,惩罚门控输出的低熵(即惩罚权重分布过于集中)。目标是让门控输出的概率分布更平坦。
- 损失项:
- lambda * Sum(p_i * log(p_i)),其中p_i是门控输出的概率向量。lambda是一个超参数,控制正则化强度。
- 损失项:
L2 正则化: 对门控网络的权重或输出应用 L2 正则化,间接防止输出过于极端。
专家负载均衡 (Expert Load Balancing):
- 核心思想: 鼓励所有专家在每个训练批次中接收到大致相同数量的“流量”(即被门控选中的总权重)。
- 实现: 在总损失中加入一个负载均衡损失项。这个损失项通常衡量每个专家在当前批次中被所有任务门控选中的总权重的方差或标准差。最小化这个损失项会促使门控网络更均匀地分配流量给所有专家。
- 损失项示例: 可以计算每个专家在批次中的平均门控权重,然后计算这些平均权重的方差,并将其加到总损失中。
梯度控制/调整 (Gradient Control/Adjustment):
- 梯度归一化或缩放: 调整不同任务对共享专家产生的梯度大小,防止某个任务的梯度过度主导。
- 更复杂的梯度操作: 如 GradNorm, PCGrad 等方法,尝试调整或投影不同任务的梯度,以减少冲突并促进更均衡的学习。
架构改进:
- Progressive Experts: 在训练过程中逐步增加专家数量,而不是一开始就使用全部专家。
- Hierarchical MMoE: 构建分层的专家结构。
初始化策略: 仔细初始化门控网络的偏置项,使其在训练初期倾向于更均匀的权重分布。
问题4:介绍一下神经网络的优化器有哪些。
常见的神经网络优化器有:
- 梯度下降(GD)
- 随机梯度下降(SGD)
- 带动量的随机梯度下降(Momentum SGD)
- Adagrad
- RMSProp
- Adam
- Adadelta
- Nadam
- Muon:神经网络隐藏层的优化器 | Keller Jordan 博客 — Muon: An optimizer for hidden layers in neural networks | Keller Jordan blog
问题5:介绍一下推荐算法的链路流程。
推荐系统通常包括以下步骤:
- 数据收集(用户行为、物品信息等)
- 特征工程
- 模型选择和训练
- 推荐列表生成
- 排序等
问题6:介绍一下神经网络的初始化方法。
常见的神经网络初始化方法有:
- 零初始化(所有权重设为 0)
- 随机初始化(权重随机设定,如高斯初始化或均匀分布初始化)
- Xavier/Glorot 初始化(权重初始化为均值为 0,方差为 $( \frac{1}{n} )$ 的正态分布或均匀分布,其中 $( n )$ 为输入神经元的数量)
- He 初始化(类似于 Xavier,但方差为 $( \frac{2}{n} )$,适用于 ReLU 激活函数)
问题7:讲一讲推荐算法序列建模的模型。
推荐算法中的序列建模通常使用序列模型来捕捉用户行为的时间依赖性。常见的序列模型有:
- RNN(如 LSTM 和 GRU)
- 序列到序列模型(Seq2Seq)
- 注意力模型(如 Transformer)
- 预训练模型(如 BERT、GPT 等)
这些模型可以处理用户行为序列,学习用户的历史行为对他们未来行为的影响,并据此进行推荐。
4.华为NLP算法面试题9道
问题1. NLP中常见的分词方法有哪些?
常见的中文分词方法包括基于规则、基于统计和基于深度学习的方法。 其中,基于规则的方法根据预先定义的规则对文本进行切分;基于统计的方法通过统计某个词
在语料库中出现的概率来进行分词;基于深度学习的方法则利用深度神经网络模型从大规模语料中学习分词模型。
问题2. 讲一下BERT的结构?
BERT(Bidirectional Encoder Representations from Transformers)是**一种基于Transformer模型的预训练语言模型。**其中的 “Bidirectional”(双向)是其核心创新点之一。 其结构由多层Transformer编码器组成,其中每层包含多头自注意力机制和前馈神经网络。BERT还采用了双向训练策略,使得模型能够在不同层次、不同粒度下理解输入序列中的上下文信息。
为什么需要双向?
在传统的语言模型中(比如基于 RNN 或早期的 Transformer Decoder),模型通常是单向的,要么从左到右(根据前面的词预测下一个词),要么从右到左。这种单向性限制了模型对词语上下文的理解。例如,在句子 “The bank can be a river bank or a financial bank.” 中,要理解第一个 “bank” 的含义(河岸),需要依赖后面的词 “river”;要理解第二个 “bank” 的含义(银行),需要依赖后面的词 “financial”。单向模型很难同时利用到词语左右两侧的完整上下文信息。
虽然 ELMo 等模型通过拼接两个独立的单向 LSTM 来实现“双向”,但它们并没有在深层真正融合左右两侧的上下文。BERT 则通过其独特的预训练任务和 Transformer Encoder 结构,实现了在每一层都能够同时利用词语左右两侧的信息。
BERT 的双向训练策略:两个预训练任务
BERT 通过在海量无标注文本数据上执行两个无监督的预训练任务来学习双向表示:
- Masked Language Model (MLM) - 掩码语言模型
- Next Sentence Prediction (NSP) - 下一句预测
这两个任务是同时进行的,模型的总损失是这两个任务损失的加权和。
1. Masked Language Model (MLM)
- 目标: 预测输入序列中被随机“遮盖”(Mask)掉的词语。
- 如何训练:
- 在输入文本序列中,随机选择 15% 的 token。
- 对于这 15% 的被选中 token:
- 80% 的情况下,将其替换为特殊的
[MASK]token。 - 10% 的情况下,将其替换为词汇表中的一个随机 token。
- 10% 的情况下,保持原样(不替换)。
- 80% 的情况下,将其替换为特殊的
- 模型的任务是预测这些被选中 token 的原始身份。
- 为什么是双向的: 为了预测一个被
[MASK]的词语,模型必须同时利用该词语左边和右边的上下文信息。例如,在句子 “The man went to the [MASK] .” 中,模型需要根据 “The man went to the” 和 “.” 来预测[MASK]可能是 “store”, “park”, “bank” 等。而在 “The man went to the [MASK] bank .” 中,模型则需要根据左右上下文预测[MASK]可能是 “river” 或 “financial”。这种预测方式迫使模型学习到词语在完整上下文中的表示,从而实现了真正的双向性。 - 与传统 LM 的区别: 传统的语言模型(如 GPT)是预测序列中的下一个词,它只能看到当前词及其之前的词。MLM 预测的是序列中任意位置的词,并且可以看到整个序列(除了被 Mask 的词本身)。
2. Next Sentence Prediction (NSP)
- 目标: 判断输入的两个句子是否是连续的。
- 如何训练:
- 从训练语料中构建输入样本,每个样本包含两个句子:Sentence A 和 Sentence B。
- 50% 的情况下,Sentence B 是 Sentence A 在原始文本中紧随其后的下一句。这种样本的标签是
IsNext。 - 50% 的情况下,Sentence B 是从语料库中随机抽取的句子,与 Sentence A 没有实际的连续关系。这种样本的标签是
NotNext。 - 输入到 BERT 的格式是
[CLS] Sentence A [SEP] Sentence B [SEP]。[CLS]token 的最终隐藏状态被用作整个句子对的表示。 - 模型的任务是基于
[CLS]token 的表示,进行一个二分类预测,判断 Sentence B 是否是 Sentence A 的下一句。
- 为什么重要: MLM 关注的是 token 级别的关系,而 NSP 关注的是句子级别的关系。许多下游任务(如问答、自然语言推理)需要模型理解句子之间的关系,NSP 任务帮助 BERT 学习到这种能力。
BERT 的结构可以概括为:
- 输入层: 将 Token Embedding, Segment Embedding, Positional Embedding 相加,形成输入向量序列。
- 堆叠的 Transformer Encoder 层:
- 每个 Encoder 层包含 Multi-Head Self-Attention 和 Position-wise Feed-Forward Network 两个子层。
- 每个子层后都有残差连接和层归一化。
- 输出层: 最后一层 Encoder 的输出向量序列,每个向量代表对应输入 token 的上下文表示。
BERT 的强大之处在于其基于双向 Transformer Encoder 的结构,结合大规模的无监督预训练任务(Masked Language Model 和 Next Sentence Prediction),使其能够学习到丰富的语言表示,这些表示可以迁移到各种下游的 NLP 任务中,只需在 BERT 的输出层之上添加一个简单的任务特定层进行微调即可。
问题3. 自然语言处理有哪些任务?
自然语言处理任务包括文本分类、命名实体识别、情感分析、机器翻译、文本生成、问答系统等。
问题4. L1,L2正则化的区别,岭回归是L1正则化还是L2正则化?
正则化的基本思想是:在模型的损失函数(用来衡量模型预测误差)中添加一个惩罚项。这个惩罚项与模型的复杂度相关,通常是模型参数(权重)的函数。通过最小化带有惩罚项的总损失,模型在努力减小预测误差的同时,也被“惩罚”其复杂度,从而倾向于选择更简单、泛化能力更好的模型。
L1正则化和L2正则化都是用来约束模型的复杂度,以避免过拟合。 L1正则化通过将模型参数的绝对值之和作为正则项,使得一些参数变为0,从而达到特征选择的目的;L2正则化通过将模型参数的平方和作为正则项,使得参数的值都变小,从而使模型更加稳定。
岭回归 (Ridge Regression) 使用的是 L2 正则化。
岭回归是在标准的线性回归的损失函数(通常是均方误差 MSE)中添加了 L2 正则化项。
- 线性回归目标: 最小化
Σ (y_i - ŷ_i)^2(即 MSE) - 岭回归目标: 最小化
Σ (y_i - ŷ_i)^2 + λ * Σ w_i^2
通过添加 L2 惩罚项,岭回归限制了模型权重的总平方和,从而控制了模型的复杂度,防止过拟合,并且在特征之间存在高度相关性时表现良好,因为它会缩小所有相关特征的权重,而不是像 Lasso 那样可能只保留其中一个。
与之对应的是 Lasso 回归 (Lasso Regression),它是在线性回归的损失函数中添加了 L1 正则化项:
- Lasso 回归目标: 最小化
Σ (y_i - ŷ_i)^2 + λ * Σ |w_i|
Lasso 回归由于其 L1 正则化项,可以实现特征选择,将一些不重要的特征的权重变为零。
问题5. 怎么处理类别不平衡?
类别不平衡问题可以通过过采样、欠采样、生成新样本、集成学习等方法来解决。 过采样方法包括随机过采样、SMOTE等;欠采样方法包括随机欠采样、
TomekLinks等;生成新样本方法包括GAN、VAE等;集成学习方法包括Bagging、Boosting等。
问题6. 模型提速的方法有哪些?
模型提速的方法包括模型压缩、剪枝、量化、分布式训练等。 模型压缩包括权重共享、低秩近似、深度可分离卷积等方法;
剪枝包括通道剪枝、结构剪枝、权重剪枝等;量化包括权重量化、激活量化等;分布式训练则是利用多个计算节点共同完成模型训练任务,加速训练过程。
问题7. 了解数据挖掘的方法嘛?
数据挖掘包括数据预处理、特征工程、模型构建和模型评估等步骤。 其中,数据预处理包括数据清洗、数据集成、数据变换和数据规约;
特征工程包括特征提取、特征选择和特征构建;模型构建包括选择合适的模型和模型参数调优;模型评估包括模型效果评估和模型泛化能力评估。
问题8. 了解对比学习嘛?
对比学习是一种无监督学习方法, 通过训练模型使得相同样本的表示更接近,不同样本的表示更远离,从而学习到更好的表示。
对比学习通常使用对比损失函数,例如Siamese网络、Triplet网络等,用于学习数据之间的相似性和差异性。
1. 对比损失 (Contrastive Loss) - 基础版本
这是最早期的对比损失形式之一,通常用于 Siamese Network 等结构。它为正样本对和负样本对分别定义损失。
假设我们有一个样本对 (x_i, x_j),它们的嵌入是 z_i 和 z_j。我们定义一个指示变量 y:
- 如果
x_i和x_j是正样本对,则y = 1。 - 如果
x_i和x_j是负样本对,则y = 0。
我们还需要一个距离度量函数 dist(z_i, z_j),例如欧氏距离 ||z_i - z_j||_2。
损失函数公式:
1 | L(z_i, z_j, y) = y * L_p(dist(z_i, z_j)) + (1 - y) * L_n(dist(z_i, z_j)) |
其中:
L_p是正样本对的损失函数。当y=1时激活。我们希望正样本距离小,所以L_p应该随着距离增大而增大。常见的形式是dist(z_i, z_j)^2。L_n是负样本对的损失函数。当y=0时激活。我们希望负样本距离大,但当距离已经足够大时,就不再惩罚了。这通常通过引入一个间隔 (margin)m来实现。常见的形式是max(0, m - dist(z_i, z_j))^2。
结合起来的常见形式:
1 | L(z_i, z_j, y) = y * ||z_i - z_j||_2^2 + (1 - y) * max(0, m - ||z_i - z_j||_2)^2 |
- 当
y=1(正样本对): 损失是||z_i - z_j||_2^2。模型会努力减小正样本对之间的距离。 - 当
y=0(负样本对): 损失是max(0, m - ||z_i - z_j||_2)^2。只有当负样本对之间的距离小于间隔m时,才会产生损失。模型会努力将负样本对推开,直到它们的距离大于等于m。
特点:
- 概念直观,易于理解。
- 需要手动设置一个间隔
m。 - 需要构建正样本对和负样本对。
2. 三元组损失 (Triplet Loss)
三元组损失是另一种经典的对比损失,常用于人脸识别等领域(如 FaceNet)。它基于一个三元组 (Triplet):一个锚点 (Anchor) a,一个与锚点相似的正样本 (Positive) p,以及一个与锚点不相似的负样本 (Negative) n。
假设它们的嵌入分别是 z_a, z_p, z_n。
损失函数公式:
1 | L(z_a, z_p, z_n) = max(0, dist(z_a, z_p) - dist(z_a, z_n) + margin) |
dist(z_a, z_p)是锚点与正样本之间的距离。dist(z_a, z_n)是锚点与负样本之间的距离。margin是一个设定的间隔,通常是一个小的正数。
目标: 最小化这个损失函数。
- 当
dist(z_a, z_p) + margin < dist(z_a, z_n)时,损失为 0。这意味着锚点与正样本的距离,加上一个间隔,已经小于锚点与负样本的距离,满足了我们的要求。 - 当
dist(z_a, z_p) + margin >= dist(z_a, z_n)时,损失为正值。模型会努力减小dist(z_a, z_p)并增大dist(z_a, z_n),直到满足上述条件。
特点:
- 直接优化相对距离:锚点与正样本的距离要小于与负样本的距离。
- 需要构建三元组。如何有效地选择负样本(Hard Negative Mining,即选择那些与锚点比较相似的负样本)对训练效果至关重要。
- 需要手动设置一个间隔
margin。
3. InfoNCE Loss (Normalized Temperature-scaled Cross-Entropy Loss)
InfoNCE Loss 是近年来在自监督对比学习框架(如 SimCLR, MoCo, BYOL 的变体)中广泛使用的损失函数。它的思想是将对比学习问题转化为一个分类问题。
假设我们有一个锚点嵌入 z_i,它的正样本嵌入是 z_j,以及一批 K 个负样本嵌入 {z_k} (k=1 to K)。总共有 K+1 个样本(1个正样本,K个负样本)与 z_i 进行对比。
InfoNCE Loss 将问题看作是:给定 z_i,从 K+1 个候选样本 {z_j, z_1, ..., z_K} 中,正确识别出 z_j(即正样本)的概率。
我们通常使用余弦相似度 (Cosine Similarity) 作为相似度度量 sim(u, v) = u . v / (||u|| ||v||)。
损失函数公式 (对于锚点 z_i):
1 | L(z_i, z_j, {z_k}) = - log [ exp(sim(z_i, z_j) / τ) / ( exp(sim(z_i, z_j) / τ) + Σ_{k=1}^K exp(sim(z_i, z_k) / τ) ) ] |
sim(z_i, z_j)是锚点z_i与正样本z_j的相似度。sim(z_i, z_k)是锚点z_i与第k个负样本z_k的相似度。τ(tau) 是一个温度参数 (Temperature Parameter),通常是一个小的正数。它控制着相似度分布的锐利程度。τ越小,模型对相似度的微小差异越敏感,越倾向于将正样本与最难的负样本区分开。- 分母是锚点与正样本以及所有负样本的相似度经过指数化(Softmax 的一部分)后的总和。
- 整个表达式是 Softmax 函数的对数形式,等价于一个 (K+1) 类分类问题的交叉熵损失,目标是最大化锚点
z_i与正样本z_j之间的相似度相对于与所有负样本相似度的比例。
总损失: 在一个批次中,通常对所有正样本对计算 InfoNCE Loss,并将它们加起来。例如,如果批次大小为 N,经过两次增强得到 2N 个视图。对于每个视图,另一个视图是正样本,批次中其他 2N-2 个视图是负样本。总损失是对这 2N 个视图计算的 InfoNCE Loss 的平均值。
特点:
- 将对比问题转化为分类问题,利用了交叉熵损失的优化特性。
- 不使用间隔 (margin),而是通过温度参数
τ来调整相似度分布。 - 对负样本数量非常敏感,负样本越多效果通常越好。
- 在自监督学习中表现出色,能够学习到高质量的表示。
总结:
- 基础对比损失和三元组损失都依赖于一个间隔 (margin) 来定义“足够远”的阈值。
- InfoNCE Loss 不使用间隔,而是通过温度参数 (τ) 和 Softmax 结构来优化正样本相似度与负样本相似度的相对比例,将对比学习转化为一个分类任务。
InfoNCE Loss 由于其在自监督学习中的优异表现和不需要手动设置间隔的特性,成为了当前对比学习领域最主流的损失函数。
这些框架都属于自监督学习 (Self-Supervised Learning) 的范畴,它们的核心目标是:在没有人工标注标签的情况下,从大规模的无标注数据中学习到高质量、通用的数据表示 (Representation)。
它们主要应用于计算机视觉 (Computer Vision) 领域,用于预训练 (Pre-training) 图像特征提取器(通常是卷积神经网络如 ResNet 或 Vision Transformer)。
共同作用:
- 学习通用视觉表示: 通过设计巧妙的自监督任务(如对比不同视图),模型被迫去学习图像中具有语义意义、对各种变换(如裁剪、颜色变化)具有鲁棒性的特征。
- 为下游任务提供更好的初始化: 预训练好的模型(特别是其编码器部分)可以作为许多下游计算机视觉任务(如图像分类、目标检测、语义分割等)的良好初始化。相比于随机初始化或在 ImageNet 等有标注数据集上进行有监督预训练,自监督预训练可以在更多样化的数据上进行,有时能学到更通用的特征,尤其是在下游任务的数据量较少时,优势更明显。
- 利用海量无标注数据: 互联网上存在海量的图像数据,但标注成本高昂。自监督学习能够充分利用这些无标注数据,挖掘其中的信息。
4.各个对比学习框架的特点、作用和区别:
这几个框架都是基于孪生网络 (Siamese Network) 或动量编码器 (Momentum Encoder) 的思想,通过比较不同视图的表示来学习。它们的主要区别在于如何构建正负样本对以及如何防止模型学到平凡解(即所有图像都映射到同一个向量)。
- SimCLR (A Simple Framework for Contrastive Learning of Visual Representations)
- 核心思想: 简单、端到端的对比学习框架。对于每张图片,生成两个不同的增强视图作为正样本对,批次中的其他图片(的增强视图)作为负样本。使用 InfoNCE Loss 优化。
- 关键组件: 强大的数据增强、一个编码器 (Encoder)、一个非线性的投影头 (Projection Head)。
- 特点: 依赖于大批次 (Large Batch Size) 来获取足够多的负样本。批次越大,负样本越多,效果越好。
- 作用: 证明了在对比学习中,数据增强的强度和负样本的数量(通过大批次实现)是至关重要的。提供了一个简洁有效的对比学习基线。
- 用在哪里: 作为自监督预训练框架,用于学习图像编码器。
- MoCo (Momentum Contrast for Unsupervised Visual Representation Learning)
- 核心思想: 解决 SimCLR 对大批次的依赖。通过维护一个动量编码器 (Momentum Encoder) 和一个队列 (Queue) 来提供大量负样本。
- 关键组件: 一个在线编码器 (Online Encoder),一个动量编码器 (Target/Momentum Encoder),一个队列。在线编码器通过梯度更新,动量编码器是其参数的指数移动平均 (EMA) 更新。队列存储动量编码器处理过的样本的表示,作为负样本。
- 特点: 不依赖于大批次,可以使用较小的批次进行训练。队列可以存储非常多的负样本,提供更丰富的对比信息。
- 作用: 使得对比学习可以在计算资源有限的情况下进行,并且能够利用更大的负样本集。是 SimCLR 的一个重要改进。
- 用在哪里: 作为自监督预训练框架,用于学习图像编码器。
- BYOL (Bootstrap Your Own Latent)
- 核心思想: 一个不需要负样本的自监督学习方法。通过让一个网络(在线网络)预测另一个网络(目标网络,动量更新)对同一个图像不同增强视图的表示来学习。
- 关键组件: 一个在线网络 (Online Network),一个目标网络 (Target Network),一个预测器 (Predictor)。目标网络的参数是根据在线网络的参数进行动量更新的。在线网络有一个额外的预测器 MLP。
- 特点: 不需要显式的负样本,简化了训练过程(无需管理负样本队列或依赖大批次)。通过预测器和动量更新来防止模型坍塌。
- 作用: 挑战了“对比学习必须有负样本”的传统观念,提供了一种新的自监督学习范式。在许多任务上取得了与基于负样本的方法相当甚至更好的性能。
- 用在哪里: 作为自监督预训练框架,用于学习图像编码器。
- SimSiam (Simple Siamese Representation Learning)
- 核心思想: 进一步简化 BYOL,证明即使没有动量编码器和负样本,通过简单的停止梯度 (Stop-Gradient) 操作和预测器,也可以防止模型坍塌。
- 关键组件: 两个共享权重的编码器(形成 Siamese 结构),一个预测器。关键在于,在计算损失时,只对其中一个分支(带有预测器的分支)进行梯度回传,另一个分支(目标分支)的梯度被停止。
- 特点: 结构非常简单,不需要负样本,不需要动量编码器。通过停止梯度来防止模型学到平凡解。
- 作用: 提供了一个极其简洁有效的自监督学习方法,进一步揭示了自监督学习成功的关键因素。
- 用在哪里: 作为自监督预训练框架,用于学习图像编码器。
5.如何集成在已有的模型中?
这里的“已有的模型”通常指的是用于下游任务(如图像分类、目标检测、语义分割等)的神经网络模型。集成这些自监督预训练框架学到的表示,通常是指将预训练好的编码器 (Encoder / Backbone) 应用到下游任务模型中。
集成步骤通常如下:
- 预训练阶段:
- 选择一个骨干网络(例如 ResNet-50)。
- 使用 SimCLR, MoCo, BYOL, SimSiam 等框架,在大规模的无标注图像数据集上(例如 ImageNet 的无标注版本)训练这个骨干网络。
- 训练完成后,我们得到了一个预训练好的编码器。注意: 在预训练阶段使用的投影头 (Projection Head) 或预测器 (Predictor) 在迁移到下游任务时通常会被丢弃。我们只需要预训练好的骨干网络参数。
- 下游任务阶段 (迁移学习):
- 选择一个用于特定下游任务的现有模型架构(例如,用于分类的 ResNet + 全连接层,用于目标检测的 Faster R-CNN,用于分割的 U-Net)。
- 将预训练好的编码器(在步骤1中训练得到的骨干网络)替换现有模型架构中的原始骨干网络。
- 在预训练编码器之上,添加或保留下游任务所需的特定头部 (Task-Specific Head)(例如,分类层、检测头、分割头等)。这些头部通常是随机初始化的。
- 使用有标注的下游任务数据集来训练整个模型(预训练编码器 + 新添加的头部)。这个过程称为微调 (Fine-tuning)。通常使用比从头训练更小的学习率。
- 在某些情况下(例如下游数据集非常小),也可以选择冻结 (Freeze) 预训练编码器的权重,只训练新添加的头部。但这通常不如微调整个模型效果好。
总结集成方式:
将 SimCLR, MoCo, BYOL, SimSiam 等框架集成到已有模型中,本质上就是利用它们进行自监督预训练,然后将预训练好的骨干网络作为特征提取器或初始化,用于下游的有监督任务模型。这种方式能够利用海量无标注数据学习通用特征,从而提升模型在下游任务上的性能,尤其是在下游任务标注数据有限的情况下。
问题9. 说一下广度优先遍历和深度优先遍历?
- 广度优先遍历(BFS) 是一种图形搜索算法,从起点开始,依次访问与起点相邻的所有节点,再访问与这些节点相邻的所有未访问过的节点,
直到找到目标节点或者所有节点都被访问。广度优先遍历使用队列来保存访问过的节点。 - 深度优先遍历(DFS) 是一种图形搜索算法,从起点开始,一直访问相邻节点,直到达到最深的节点,再返回上一级节点,继续访问其他未访问过的节点,
直到找到目标节点或者所有节点都被访问。深度优先遍历使用栈来保存访问过的节点。与广度优先遍历相比,深度优先遍历更适用于搜索深度较深的图形。
5.联想算法面试题9道
问题1:分类问题的交叉熵是什么?
分类问题的交叉熵(cross-entropy) 是一种用来衡量分类模型输出与真实标签之间差异的指标。在二分类问题中,交叉熵可以表示为以下公式:
$$H(p, q) = -\sum_{c=1}^{2} p(c) \log(q(c))$$
其中, $p$ 表示真实标签, $q$ 表示模型预测的标签, $N$ 表示样本数量。
问题2:分类问题是否可以用MSE?
分类问题通常不能使用均方误差(MSE)作为损失函数, 因为分类问题中的标签通常是离散的,而MSE适用于连续变量的回归问题。
当使用MSE作为损失函数时,模型的输出可能会超过1或小于0,这是因为MSE的计算方式不适用于概率值的范围。
问题3:推荐系统中,相比于余弦相似度,是否可以用欧几里得距离判断相似度?
在推荐系统中,通常使用余弦相似度来度量用户或物品之间的相似度。 因为余弦相似度考虑的是向量之间的夹角,而不是向量的长度,
因此它对于不同大小的向量比较稳健。而欧几里得距离则是考虑向量之间的长度,因此对于不同大小的向量比较敏感。
1. 欧几里得距离 (Euclidean Distance)
- 衡量标准: 衡量两个向量在多维空间中的直线距离。
- 公式: 对于两个向量 A 和 B,欧几里得距离
dist(A, B) = ||A - B||_2 = sqrt(Σ (A_i - B_i)^2)。 - 相似度转换: 距离越小,相似度越高。通常需要将距离转换为相似度,例如
Similarity = 1 / (1 + dist)或Similarity = exp(-dist)。 - 特点: 对向量的绝对值大小 (Magnitude) 非常敏感。如果两个向量的维度值都很大,即使它们的方向相似,欧几里得距离也可能很大。
问题4:过拟合怎么处理?
过拟合是指模型在训练集上表现良好,但在测试集上表现较差的现象。过拟合的常见处理方法包括:
- 增加数据量:通过增加训练数据来降低模型对于训练集的过度拟合。
- 简化模型:减少模型的参数量,简化模型的结构,降低模型的复杂度。
- 正则化:通过在损失函数中添加正则化项,限制模型参数的大小,从而避免模型过度拟合。常见的正则化方法包括L1正则化和L2正则化。
问题5:L1、L2正则化的效果、区别、原理?
L1正则化和L2正则化都是正则化方法,目的是通过限制模型参数的大小,降低模型的复杂度,防止过拟合。
- L1正则化: $$( \text{L1 Regularization} = \lambda \sum |w_i| )$$ ,会使一部分参数变为0,从而实现特征选择的效果, 适合处理稀疏数据。
- L2正则化: $$( \text{L2 Regularization} = \lambda \sum w_i^2 )$$ ,会让所有参数都趋向于较小的值,但不会使参数为0。
问题6:Dropout的原理、在训练和测试时的区别?
Dropout是一种常用的正则化方法, 其原理是在每次迭代中随机将一部分神经元的输出置为0,从而减少神经元之间的共适应性,防止过拟合。
在训练时,Dropout会随机将一定比例的神经元的输出置为0,而在测试时,为了保持网络的稳定性,Dropout通常被关闭。
问题7:SGD、Adam、动量优化的SGD?
SGD(Stochastic Gradient Descent)是一种基本的梯度下降算法,使用单个样本的梯度来更新模型参数。
动量优化的SGD(Momentum SGD) 在SGD的基础上引入了动量,使得更新方向更加平稳,收敛速度更快。
Adam是一种基于梯度的优化算法,结合了RMSProp和动量优化的思想,
通过维护一个梯度的指数加权移动平均和梯度平方的指数加权移动平均来自适应地调整每个参数的学习率。
问题8:Adam和动量优化的SGD效率上的区别?
Adam相对于动量优化的SGD有自适应性、速度快和可靠性高的优点。 Adam能够自适应地调整每个参数的学习率,从而在不同的参数空间下能够更加快速地收敛,
并且对超参数的选择不太敏感。
问题9:推荐系统中,如何进行负采样?
在推荐系统中,负采样是一种重要的技术,用于构造负样本,以便训练推荐模型。 负采样的过程通常包括计算每个物品的权重、根据权重进行采样、
去除已有的正样本和控制负采样比例等步骤。
负采样的核心目的:
- 生成训练数据: 为模型提供负例,使其能够学习区分正负样本。
- 提高训练效率: 用户没有交互过的物品数量巨大,不可能将所有未交互物品都作为负样本进行训练。负采样使得训练在计算上可行。
- 学习更好的表示: 通过对比正样本和精心挑选的负样本,模型能够学习到更具区分性的用户和物品表示。
常见的负采样策略:
不同的负采样策略会显著影响模型的训练效果和效率。以下是一些常见的策略:
- 均匀随机采样 (Uniform Random Sampling):
- 方法: 从用户 U 没有交互过的所有物品中,完全随机地抽取
K个物品。 - 优点: 实现简单,计算成本低。
- 缺点: 采样的负样本中,很多可能是非常冷门或用户显然不会喜欢的物品(“简单负样本”)。模型很容易就能区分这些简单负样本和正样本,导致模型学习到的区分能力不够强,难以处理那些与正样本比较相似的“困难负样本”。
- 方法: 从用户 U 没有交互过的所有物品中,完全随机地抽取
- 基于流行度的采样 (Popularity-Based Sampling):
- 方法: 按照物品的流行度(例如,物品被交互的总次数)进行采样。流行度越高的物品,被采样的概率越大。通常使用物品流行度的
α次幂作为采样概率分布,其中α是一个超参数(例如,Word2Vec 中的负采样使用了α=0.75)。 - 优点: 更有可能采样到用户可能见过或与正样本在流行度上接近的物品。这些物品更有可能是“困难负样本”,因为它们更容易与正样本混淆。这能迫使模型学习更精细的区分能力。
- 缺点: 可能会过度偏向流行物品,忽略长尾物品。如果
α设置不当,可能效果不佳。
- 方法: 按照物品的流行度(例如,物品被交互的总次数)进行采样。流行度越高的物品,被采样的概率越大。通常使用物品流行度的
- 模型采样 / Hard Negative Mining (困难负样本挖掘):
- 方法: 利用当前训练中的模型,找出那些模型预测用户 U 可能喜欢,但用户实际上没有交互过的物品。这些就是模型当前难以区分的“困难负样本”。
- 具体实现:
- 在线挖掘: 在每个训练批次中,对于每个正样本 (U, I_pos),计算用户 U 对一批候选物品的预测得分,然后选择得分最高但未交互的物品作为负样本。
- 离线挖掘: 定期使用当前模型对所有用户-物品对进行预测,找出预测得分高但无交互的对,将它们加入负样本库。
- 优点: 提供了最有挑战性的训练样本,能显著提升模型的区分能力和性能。
- 缺点: 计算成本非常高,需要频繁进行预测。存在“假负样本”的风险,即用户 U 实际上会喜欢某个物品,只是还没有交互,但被模型误判为困难负样本。
- Item-Based Sampling (基于物品的采样):
- 方法: 对于正样本 (U, I_pos),采样与 I_pos 相似的物品作为负样本。这里的相似性可以是基于物品属性、协同过滤相似性或通过其他方式计算。
- 优点: 采样的负样本与正样本在某些方面相似,有助于模型学习区分细微的差异。
- 缺点: 需要预先计算物品相似性,且相似性定义可能影响效果。
- In-Batch Negative Sampling (批内负采样):
- 方法: 在一个训练批次中,对于每个正样本 (U_i, I_pos_i),将批次中其他用户的正样本物品 {I_pos_j | j ≠ i} 作为用户 U_i 的负样本。
- 优点: 非常高效,不需要额外的采样步骤。自然地提供了大量负样本(批次大小的
N-1倍)。在对比学习框架(如 SimCLR)中广泛使用。 - 缺点: 负样本数量受限于批次大小。存在“假负样本”的风险:如果用户 U_i 实际上也喜欢物品 I_pos_j,但它被当作负样本。在推荐系统中,由于用户-物品交互的稀疏性,这种假负样本的概率相对较低,但在通用对比学习中需要注意。
6.字节电商CV算法实习岗面试题8道
问题1:如何解决类别极度不平衡的问题?
- 在机器学习中,类别不平衡是指数据集中各类样本的数量差异较大,这可能导致模型对多数类过度拟合,而对少数类泛化能力差。
问题2:说下 Transformer 模型
- Transformer 模型 是一种基于自注意力机制的神经网络架构,广泛应用于序列到序列的任务中。Transformer 本身是一个典型的encoder-decoder模型,
Encoder端和Decoder端均有6个Block, Encoder 端的Block 包括两个模块,多头self-attention模块以及一个前馈神经网络模块;Decoder端的
Block 包括三个模块,多头self-attention模块,多头Encoder-Decoder attention交互模块,以及一个前 馈神经网络模块;
需要注意:Encoder端和Decoder端中的每个模块都有残差层和LayerNormalization层。
问题3:说下 Focal Loss
- Focal loss 是目标检测中解决正负样本严重不平衡的方法,在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,
使得模型在训练时更专注于稀疏的难分类的样本;防止大量易分类负样本在loss 中占主导地位
标准交叉熵损失 (Cross-Entropy Loss)
对于二分类问题,标准交叉熵损失的公式如下:
1 | CE(p, y) = - y * log(p) - (1 - y) * log(1 - p) |
其中:
y是真实标签,y = 1表示正类,y = 0表示负类。p是模型预测为正类的概率。
为了方便表示,我们可以定义 p_t:
- 如果
y = 1(正类),则p_t = p(模型预测为正类的概率)。 - 如果
y = 0(负类),则p_t = 1 - p(模型预测为负类的概率)。
那么,交叉熵损失可以简化为:
1 | CE(p_t) = - log(p_t) |
分析标准交叉熵损失在类别不平衡下的问题:
考虑一个易分样本,例如一个背景区域,真实标签 y = 0。如果模型对其预测的概率 p 非常接近 0(例如 p = 0.01),那么 p_t = 1 - p = 0.99。此时,损失 CE(0.99) = -log(0.99) 是一个非常小的正数。
虽然单个易分样本的损失很小,但由于易分样本数量巨大,它们的总损失 Σ CE(p_t) 会非常大,从而主导了整个训练过程的梯度。模型会花费大量精力去优化这些已经很容易区分的样本,而对那些预测概率 p_t 较低(即模型预测错误或不确定)的困难样本关注不足。
Focal Loss 的设计思想:
Focal Loss 旨在解决这个问题,它在标准交叉熵损失的基础上引入了两个修改:
- 平衡交叉熵 (Balanced Cross-Entropy): 引入一个权重因子
α_t来平衡正负样本的贡献。 - 聚焦参数 (Focusing Parameter): 引入一个调制因子
(1 - p_t)^γ来降低易分样本的权重,从而将训练的焦点“聚焦”在困难样本上。
平衡交叉熵 (Balanced Cross-Entropy)
为了解决正负样本数量差异带来的问题,可以在交叉熵损失前乘以一个权重因子 α_t:
1 | CE'(p_t) = - α_t * log(p_t) |
其中:
- 如果
y = 1(正类),则α_t = α(一个超参数,通常α < 0.5,给正类较小的权重)。 - 如果
y = 0(负类),则α_t = 1 - α(给负类较大的权重)。
或者更常见的做法是,如果正样本是少数类,负样本是多数类,则给正样本的损失乘以一个较大的权重 α,给负样本的损失乘以一个较小的权重 1-α。例如,如果正样本占总数的 1%,可以设置 α = 0.99。
1 | Balanced_CE(p, y) = - α * y * log(p) - (1 - α) * (1 - y) * log(1 - p) |
或者使用 p_t 表示:
1 | Balanced_CE(p_t) = - α_t * log(p_t) |
其中 α_t 的定义与上面类似,但 α 的取值可能根据少数类的比例来设置。
平衡交叉熵可以在一定程度上缓解类别不平衡,但它只是简单地调整了正负样本的总权重,并没有区分易分样本和困难样本。
聚焦参数 (Focusing Parameter)
Focal Loss 的核心创新在于引入了一个调制因子 (1 - p_t)^γ。
1 | Focal_Loss(p_t) = - (1 - p_t)^γ * log(p_t) |
其中 γ (gamma) 是一个非负的超参数,称为聚焦参数。
- 当
γ = 0时:(1 - p_t)^0 = 1,Focal Loss 退化为标准的交叉熵损失CE(p_t) = - log(p_t)。 - 当
γ > 0时:- 对于易分样本 (即
p_t接近 1,模型预测很准确),(1 - p_t)接近 0,(1 - p_t)^γ会更接近 0。调制因子会显著降低这些易分样本的损失贡献。 - 对于困难样本 (即
p_t较小,模型预测不准确),(1 - p_t)接近 1,(1 - p_t)^γ也接近 1。调制因子对这些困难样本的损失影响较小。
- 对于易分样本 (即
γ 的值越大,调制因子对易分样本的权重降低得越多,模型就越会“聚焦”在那些预测错误的困难样本上。论文中发现 γ = 2 时效果最好。
Focal Loss 的最终公式:
Focal Loss 通常结合了平衡交叉熵和聚焦参数:
1 | FL(p_t) = - α_t * (1 - p_t)^γ * log(p_t) |
其中 α_t 的定义与平衡交叉熵中相同,用于平衡正负样本的总权重;(1 - p_t)^γ 是调制因子,用于降低易分样本的权重。
公式解释:
p_t: 模型预测为真实类别的概率。y: 真实标签 (0 或 1)。α_t: 平衡因子,根据真实类别y取α或1-α。用于平衡正负样本数量差异。γ: 聚焦参数,非负。用于调整调制因子的强度,控制对易分样本损失的降低程度。(1 - p_t)^γ: 调制因子。当p_t接近 1 (易分样本) 时,此项接近 0,损失被降低。当p_t较小 (困难样本) 时,此项接近 1,损失影响较小。- log(p_t): 标准交叉熵损失。
Focal Loss 的作用:
通过引入调制因子,Focal Loss 动态地调整了每个样本的权重:
- 易分样本 (p_t 接近 1): 权重
α_t * (1 - p_t)^γ变得非常小,对总损失的贡献微乎其微。 - 困难样本 (p_t 较小): 权重
α_t * (1 - p_t)^γ相对较大,对总损失的贡献更大。
这样,即使易分样本数量巨大,它们的总损失也不会淹没困难样本的损失,模型能够更有效地学习那些难以区分的样本,从而在类别不平衡问题上取得更好的性能。
问题4:介绍下深度可分离卷积和传统卷积的区别
- 深度可分离卷积首先在每个通道上独立进行空间卷积,然后使用 $1 \times 1$ 的卷积来组合通道特征,与传统卷积相比,它大大减少了参数数量和计算量。
- 传统的卷积是各个通道上采用不同的卷积核,然后不同的卷积核用于提取不同方面的特征。
- 深度可分离卷积先在各个通道上采用不同的卷积核提取不同的特征,但是这样对于某个通道来说,就只提取了一方面的特征,因此在此基础上加入点卷积,
用1*1的卷积对提取特征后的特征图再次提取不同方面的 特征,最终产生和普通卷积相同的输出特征图。
问题5:如何防止过拟合
- 防止过拟合的方法包括:获取更多数据、数据增强、正则化(如L1、L2正则化)、Dropout、Early Stopping等。
问题6:BN 在训练和测试的时候的区别?可以防止过拟合吗?
- Batch Normalization (BN) 在训练时对每个mini-batch的数据进行归一化,而在测试时使用整个训练集的统计量。
- BN有助于防止过拟合,因为它使得模型对于输入数据的分布变化更加鲁棒。 BN算法防止过拟合:在网络的训练中,BN的使用使得一个minibatch中所有样本都被关联在了一起,
因此网络不会从某一个训练样本中生成确定的结果,即同样一个样本的输出不再仅仅取决于样本的本身,也取 决于跟这个样本同属一个batch的其他样本,
而每次网络都是随机取batch,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
问题7:什么是 AUC?
AUC(Area Under the Curve)是ROC曲线下的面积,用来衡量分类器的排序能力。 AUC可以解读为从所有正例中随机选取一个样本A,
再从所有负例中随机选取一个样本B,分类器将A判为正例的概率比将B判为正例的概率大的可能性。AUC反映的是分类器对样本的排序能力。
AUC越大,自然排序能力越好,即分类器将越多的正例排在负例之前。AUC (Area Under the Curve)
AUC 就是 ROC 曲线下方区域的面积。
- 取值范围: AUC 的值介于 0 到 1 之间。
- 意义: AUC 的值可以解释为:随机抽取一个正样本和一个负样本,模型将正样本的预测得分高于负样本的预测得分的概率。
AUC 值的含义:
- AUC = 1: 完美的模型,能够完全区分正负样本。
- AUC = 0.5: 随机猜测的模型,没有区分能力。
- AUC < 0.5: 比随机猜测还差的模型(可能是预测逻辑反了)。
- 0.5 < AUC < 1: 模型具有一定的区分能力,AUC 值越大,模型的性能越好。
如何生成 ROC 曲线?
对于一个二分类模型,它通常会输出一个样本属于正类的概率得分。为了将这个概率得分转换为最终的分类结果(正类或负类),我们需要设定一个分类阈值 (Threshold)。如果概率得分高于阈值,则预测为正类;否则预测为负类。
ROC 曲线是通过遍历所有可能的分类阈值(从 0 到 1)来生成的。对于每一个阈值,我们计算对应的 FPR 和 TPR,然后在坐标系中绘制一个点。将所有阈值对应的点连接起来,就得到了 ROC 曲线。
- 当阈值设为 1 时,模型将所有样本都预测为负类,此时 TP=0, FP=0,所以 TPR=0, FPR=0,对应 ROC 曲线的起点 (0, 0)。
- 当阈值设为 0 时,模型将所有样本都预测为正类,此时 FN=0, TN=0,所以 TPR=1, FPR=1,对应 ROC 曲线的终点 (1, 1)。
ROC 曲线的意义:
ROC 曲线反映了模型在不同分类阈值下,识别正类的能力 (TPR) 与误报负类的能力 (FPR) 之间的权衡。
- 一个好的模型,其 ROC 曲线应该尽可能地靠近左上角。这意味着在较低的 FPR 下,能够获得较高的 TPR。
- 一条对角线 (从 (0,0) 到 (1,1)) 代表一个随机猜测的模型
问题8:卷积核计算公式
- 卷积层的输出特征图大小可以通过以下公式计算:
$$Output = (W - K + 2P) / S + 1$$
其中 $W$ 是输入特征图的大小, $K$ 是卷积核的大小,
$P$ 是padding的大小, $S$ 是步长。
- 步长 S=1 时保持输出特征图大小等于输入特征图大小所需的填充 P 的值,通常会设定padding为:
$$P = \frac{K - 1}{2}$$
7.快手多模态算法岗面试题7道
问题1:PPO 和 DPO 有什么区别?
PPO算法会多次采样,标注样本并不是只有好与不好两种样本,而是会存在多个样本,会有打分排序,还会引入奖励模型(reward model)。
DPO 可以直接依据策略来定义偏好损失。当存在一个关于模型响应的人类偏好数据集时,DPO 能够在训练过程中,使用简单的二元交叉熵目标来对策略进行优化,而无需明确地去学习奖励函数或者从策略中进行采样。
PPO (Proximal Policy Optimization)
PPO 是一种基于策略梯度 (Policy Gradient) 的在线 (On-policy) RL 算法。它通过迭代地收集数据并更新策略来最大化奖励。为了提高训练的稳定性和效率,PPO 引入了裁剪 (Clipping) 的机制,限制每次策略更新的幅度,防止新策略与旧策略差异过大,从而避免训练崩溃。
策略梯度 (Policy Gradient)
策略梯度方法的核心目标是学习一个策略 (Policy),这个策略是一个函数,它告诉我们在给定状态 (State) 下,应该以多大的概率 (Probability) 去执行某个动作 (Action)。我们希望找到一个最优的策略,使得在遵循这个策略与环境交互时,能够获得最大的预期累积奖励 (Expected Cumulative Reward)。
策略通常用参数 θ 来表示,记作 π_θ(a | s),表示在状态 s 下采取动作 a 的概率。我们的任务就是找到最优的 θ。
为了最大化预期累积奖励,我们使用梯度上升 (Gradient Ascent) 的方法来更新参数 θ。梯度上升的方向是函数值增加最快的方向。所以,我们需要计算预期累积奖励对策略参数 θ 的梯度 ∇_θ J(θ),其中 J(θ) 表示策略 π_θ 的性能指标(即预期累积奖励)。
策略梯度定理 (Policy Gradient Theorem) 提供了计算这个梯度的方法。一个常用的、基于轨迹采样的策略梯度公式(简化版,忽略了折扣因子和基线)如下:
$$∇θ J(θ) \approx \mathbb{E}{\tau \sim \pi_\theta} \left[ \sum_{t=0}^T ∇θ \log \pi\theta(a_t | s_t) A^{\pi_\theta}(s_t, a_t) \right]$$
现在,我们逐一解释公式中的每个部分:
∇_θ:- 这是一个梯度算子 (Gradient Operator)。
- 它表示对后面的表达式计算关于参数
θ的偏导数向量。 - 如果
θ是一个向量或矩阵,∇_θ计算出的结果也是一个向量或矩阵,其中每个元素是表达式对θ中对应参数的偏导数。 - 在梯度上升中,我们沿着梯度的方向更新参数,以增加目标函数的值。
J(θ):- 这是策略
π_θ的性能指标 (Performance Measure) 或目标函数 (Objective Function)。 - 它通常定义为在遵循策略
π_θ与环境交互时,从某个起始状态开始获得的预期累积奖励。 - 我们的目标就是最大化这个
J(θ)。
- 这是策略
≈:- 表示近似 (Approximation)。
- 策略梯度定理给出了梯度的精确表达式,但那个表达式通常涉及对所有可能的状态和动作进行求和或积分,这在实际中是不可行的。
- 这个公式是基于蒙特卡洛方法 (Monte Carlo Method) 的近似,通过从环境中采样轨迹 (Trajectory) 来估计梯度的期望值。
E:- 表示期望 (Expectation)。
E[X]表示随机变量X的平均值。- 这里的期望是关于轨迹
τ的分布。
τ:- 表示一个轨迹 (Trajectory) 或回合 (Episode)。
- 一个轨迹是智能体与环境交互过程中经历的一系列状态、动作和奖励的序列:
τ = (s_0, a_0, r_1, s_1, a_1, r_2, s_2, ..., s_T, a_T, r_{T+1})。 s_t: 在时间步t智能体所处的状态。a_t: 在时间步t智能体根据策略π_θ在状态s_t下采取的动作。r_{t+1}: 在时间步t采取动作a_t后,环境给出的奖励,并转移到状态s_{t+1}。
τ ~ π_θ:- 表示轨迹
τ是通过遵循策略π_θ与环境交互采样得到的。 - 这意味着在每个状态
s_t,智能体根据策略π_θ(a_t | s_t)的概率分布来选择动作a_t。 - 这是在线 (On-policy) 算法的特点:用于训练的数据是由当前正在学习的策略产生的。
- 表示轨迹
Σ_{t=0}^T:- 表示对轨迹中的所有时间步进行求和 (Summation)。
t是时间步索引,从 0 开始。T是轨迹的结束时间步(或回合的长度)。
π_θ(a_t | s_t):- 这是策略
π_θ在状态s_t下采取动作a_t的概率。 - 这是一个函数,输入是状态
s_t和动作a_t,输出是一个介于 0 和 1 之间的概率值。 - 这个函数由参数
θ决定。
- 这是策略
log π_θ(a_t | s_t):- 这是策略在状态
s_t下采取动作a_t的对数概率 (Log Probability)。 - 在计算梯度时使用对数概率是一个标准的技巧,因为
∇ log f(x) = ∇ f(x) / f(x)。这使得计算概率分布(如 Softmax)的梯度更加方便。 ∇_θ log π_θ(a_t | s_t)的意义是:如何调整参数θ,才能增加在状态s_t下采取动作a_t的概率。
- 这是策略在状态
∇_θ log π_θ(a_t | s_t):- 这是对数概率关于策略参数
θ的梯度。 - 这个向量指明了调整
θ的方向,以便提高在状态s_t下采取实际执行的动作a_t的概率。
- 这是对数概率关于策略参数
A^{\pi_\theta}(s_t, a_t):- 这是在状态
s_t下采取动作a_t的优势函数 (Advantage Function)。 - 它衡量了在状态
s_t下采取动作a_t所获得的预期未来累积奖励,与在状态s_t下平均而言遵循策略π_θ所获得的预期未来累积奖励之间的差值。 - 形式上,
A^{\pi_\theta}(s, a) = Q^{\pi_\theta}(s, a) - V^{\pi_\theta}(s)。Q^{\pi_\theta}(s, a): 在状态s下采取动作a后,再遵循策略π_θ所获得的预期未来累积奖励(状态-动作价值函数)。V^{\pi_\theta}(s): 在状态s下,遵循策略π_θ所获得的预期未来累积奖励(状态价值函数)。
- 核心作用:信用分配 (Credit Assignment)。
- 如果
A^{\pi_\theta}(s_t, a_t) > 0:表示在状态s_t下采取动作a_t是一个好动作(比平均情况好)。我们希望增加在s_t下采取a_t的概率。公式中的∇_θ log π_θ(a_t | s_t)会指向增加π_θ(a_t | s_t)的方向,乘以正的A值,整个项会促使θ向增加π_θ(a_t | s_t)的方向更新。 - 如果
A^{\pi_\theta}(s_t, a_t) < 0:表示在状态s_t下采取动作a_t是一个坏动作(比平均情况差)。我们希望减小在s_t下采取a_t的概率。公式中的∇_θ log π_θ(a_t | s_t)会指向增加π_θ(a_t | s_t)的方向,乘以负的A值,整个项会促使θ向减小π_θ(a_t | s_t)的方向更新。
- 如果
- 在实际应用中,
A^{\pi_\theta}(s_t, a_t)通常需要被估计。常见的估计方法包括:- 使用蒙特卡洛方法计算从
s_t开始的累积奖励(Return),然后减去一个基线(如V(s_t))来估计优势。 - 使用时序差分 (TD) 误差,例如
r_{t+1} + γV(s_{t+1}) - V(s_t)。 - 使用广义优势估计 (GAE)。
- 使用蒙特卡洛方法计算从
- 这是在状态
整个公式的直观意义:
策略梯度公式告诉我们,要计算如何更新策略参数 θ 以最大化预期奖励,我们可以通过以下步骤:
- 遵循当前策略
π_θ与环境交互,收集一些轨迹。 - 对于轨迹中的每一个时间步
t,计算:- 在状态
s_t下采取实际动作a_t的对数概率关于θ的梯度∇_θ log π_θ(a_t | s_t)。这告诉我们如何调整θ来增加π_θ(a_t | s_t)。 - 动作
a_t在状态s_t下的优势A^{\pi_\theta}(s_t, a_t)。这告诉我们动作a_t是好是坏。
- 在状态
- 将这两项相乘:
∇_θ log π_θ(a_t | s_t) * A^{\pi_\theta}(s_t, a_t)。如果A是正的,我们就沿着增加π_θ(a_t | s_t)的方向更新;如果A是负的,我们就沿着减小π_θ(a_t | s_t)的方向更新。 - 将轨迹中所有时间步的这些项加起来。
- 对收集到的所有轨迹的这个总和取平均(这就是期望
E的作用)。 - 这个平均值就是我们用来更新策略参数
θ的梯度方向。
通过这种方式,策略梯度算法能够“学习”哪些动作在哪些状态下是好的,并调整策略,使得这些好的动作被选择的概率增加,而坏的动作被选择的概率减小。
在线强化学习 (On-policy RL)
- 核心思想: 用于更新策略的数据是由当前正在学习的策略与环境交互产生的。
- 流程:
- 使用当前策略
π_k与环境交互,收集一条或多条轨迹(数据)。 - 利用这些刚刚收集到的数据来更新策略参数,得到新的策略
π_{k+1}。 - 丢弃旧的数据(或者说,旧数据不能直接用于训练新的策略
π_{k+1})。 - 重复步骤 1-3,使用新的策略
π_{k+1}收集数据。
- 使用当前策略
- 特点:
- 数据利用率低: 每更新一次策略,之前收集的数据就不能再用于主要的策略更新了(尽管有些算法会有限地重用)。
- 训练过程紧密耦合: 策略的更新和数据的收集是紧密相连的。
- 探索与利用: 在线算法通常需要策略本身具有一定的探索性(例如,使用 ε-greedy 或熵正则化),以便收集到足够多样化的数据来学习。
- 为什么 PPO 是在线的?
PPO 的目标函数L^{CLIP}依赖于策略概率比r_t = π_θ(a_t | s_t) / π_θ_old(a_t | s_t)。这个比值只有在当前策略π_θ与收集数据的旧策略π_θ_old差异不大时才有效。PPO 的裁剪机制正是为了限制这种差异,从而允许在一定范围内重用由π_θ_old收集的数据进行多次更新。但是,如果策略更新幅度过大,或者经过几次更新后π_θ与最初收集数据的π_θ_old差异变大,就需要用新的策略π_θ重新收集数据。因此,PPO 仍然属于在线算法,因为它依赖于与当前或近期策略相关的轨迹数据。
与离线强化学习 (Off-policy RL) 的对比:
- 离线 RL: 用于更新策略的数据可以由任何策略(包括旧策略、随机策略或其他策略)生成。离线算法通常维护一个经验回放缓冲区 (Experience Replay Buffer),存储过去收集的数据,并在训练时从中采样。
- 特点:
- 数据利用率高: 可以重复使用旧数据。
- 训练过程解耦: 数据收集和策略更新相对独立。
- 需要重要性采样或 Q 函数: 为了使用旧策略的数据来更新当前策略,离线算法通常需要使用重要性采样 (Importance Sampling) 来校正数据分布的差异,或者依赖于 Q 函数(Q 函数的更新不直接依赖于当前策略)。
- 例子: Q-learning, DQN, DDPG, SAC。
DPO (Direct Policy Optimization)
DPO 是一种较新的算法,旨在简化强化学习中的策略优化问题。它通过直接最小化目标函数来优化策略,而不是通过PPO的对数比率和剪裁损失函数。
DPO 采用了更直接的优化方式,简化了策略更新过程。
PPO 的核心控制在于通过裁剪策略概率比 r_t 来限制每次策略更新的幅度。这使得 PPO 能够在多个训练 epoch 中重复使用同一批数据(相比于传统的策略梯度只能使用一次),提高了数据利用率和训练稳定性。
我们来详细解释 PPO (Proximal Policy Optimization) 算法中核心的裁剪目标函数 (Clipped Objective Function) 公式,以及它如何实现限制策略更新幅度、提高稳定性和数据利用率。
PPO 的目标是最大化以下目标函数(我们关注最常见的裁剪版本):
$$L^{CLIP}(\theta) = \mathbb{E}_t \left[ \min(r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t) \right]$$
这个公式看起来有点复杂,我们一步步拆解它。
核心思想回顾:
PPO 是一个基于策略梯度的算法。策略梯度方法通过计算策略参数的梯度来更新策略,以增加获得高奖励动作的概率,减少获得低奖励动作的概率。传统的策略梯度方法(如 REINFORCE)方差较高,且每次更新后需要重新收集数据(在线算法的特点),效率较低。PPO 引入了裁剪机制,限制每次策略更新的幅度,使得新策略与旧策略不会差异过大,从而允许在一定程度上重复使用旧数据,提高稳定性和数据效率。
公式符号解释:
L^{CLIP}(\theta):- 这是 PPO 算法尝试最大化的目标函数 (Objective Function)。
θ是当前策略π_θ的参数。- 通过最大化这个函数,我们来更新策略参数
θ。
E_t:- 表示在时间步
t收集的数据批次 (Batch of Data) 上的期望 (Expectation)。 - 这里的“数据”是指通过旧策略
π_θ_old与环境交互收集到的状态s_t、动作a_t和优势估计Â_t。 - 在实际训练中,这个期望通常通过对一个批次的数据进行平均来近似。
- 表示在时间步
r_t(\theta):- 这是策略概率比 (Probability Ratio)。
- 定义为:
r_t(\theta) = \frac{\pi_\theta(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)} π_\theta(a_t | s_t): 当前策略π_θ在状态s_t下采取动作a_t的概率。π_{\theta_{old}}(a_t | s_t): 收集数据时使用的旧策略π_θ_old在状态s_t下采取动作a_t的概率。- 意义:
r_t衡量了当前策略π_θ相对于旧策略π_θ_old,在状态s_t下采取动作a_t的概率变化了多少倍。- 如果
r_t > 1,说明新策略更倾向于在s_t下采取a_t。 - 如果
r_t < 1,说明新策略更不倾向于在s_t下采取a_t。 - 如果
r_t = 1,说明新策略和旧策略在s_t下采取a_t的概率相同。
- 如果
Â_t:- 这是在时间步
t的优势函数估计 (Advantage Estimate)。 - 它衡量了在状态
s_t下采取动作a_t比该状态下的平均预期回报好多少。 Â_t > 0表示动作a_t是一个好动作(比平均好)。Â_t < 0表示动作a_t是一个坏动作(比平均差)。- 在 PPO 中,
Â_t通常通过一个单独训练的价值函数 (Value Function) 来估计。
- 这是在时间步
r_t(\theta) \hat{A}_t:- 这是未裁剪的策略梯度目标项(忽略了对数概率梯度,因为优化这个表达式等价于优化策略梯度)。
- 如果
Â_t > 0,我们希望最大化这个项,这意味着增加r_t(即增加采取好动作的概率)。 - 如果
Â_t < 0,我们希望最大化这个项,这意味着减小r_t(因为Â_t是负的,减小r_t会使乘积变大,例如-2 * 0.5 = -1,-2 * 0.1 = -0.2,-0.2 > -1)。
ε(epsilon):- 这是一个小的超参数 (Hyperparameter),通常取值在 0.1 或 0.2 左右。
- 它定义了策略概率比
r_t的裁剪范围。
1 - ε和1 + ε:- 定义了策略概率比
r_t的下限和上限。
- 定义了策略概率比
text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon):- 这是一个裁剪函数 (Clipping Function)。
- 它的作用是将
r_t(\theta)的值限制在[1 - ε, 1 + ε]的范围内。 - 如果
r_t(\theta) < 1 - ε,则输出1 - ε。 - 如果
r_t(\theta) > 1 + ε,则输出1 + ε。 - 如果
1 - ε ≤ r_t(\theta) ≤ 1 + ε,则输出r_t(\theta)本身。
text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t:- 这是裁剪后的策略梯度目标项。策略概率比
r_t在乘以优势Â_t之前被裁剪了。
- 这是裁剪后的策略梯度目标项。策略概率比
min(r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1 - \epsilon, 1 + \epsilon) \hat{A}_t):这是 PPO 裁剪目标函数的核心部分。它取未裁剪目标项和裁剪目标项中的较小值。
这个
min操作是实现“限制策略更新幅度”的关键。我们分两种情况来看:情况 A:
Â_t > 0(好动作)- 我们希望增加采取动作
a_t的概率,即增加r_t。 - 未裁剪项
r_t \hat{A}_t会随着r_t的增加而线性增加。 - 裁剪项
clip(r_t, ...) \hat{A}_t会随着r_t的增加而增加,但当r_t超过1 + ε后,clip(r_t, ...)就固定在1 + ε,所以裁剪项也固定在(1 + ε) \hat{A}_t。 min函数会选择两者中较小的那个。- 当
r_t ≤ 1 + ε时,r_t \hat{A}_t ≤ (1 + ε) \hat{A}_t(因为Â_t > 0),此时min选择未裁剪项r_t \hat{A}_t。 - 当
r_t > 1 + ε时,r_t \hat{A}_t > (1 + ε) \hat{A}_t,此时min选择裁剪项(1 + ε) \hat{A}_t。
- 当
- 结果: 目标函数会奖励增加
r_t,但奖励的增加只到r_t = 1 + ε为止。即使新策略想让r_t变得非常大(比如 100),目标函数也不会继续增加,从而限制了策略过度激进地增加好动作的概率。
- 我们希望增加采取动作
情况 B:
Â_t < 0(坏动作)- 我们希望减小采取动作
a_t的概率,即减小r_t。最大化目标函数意味着让r_t \hat{A}_t变得“不那么负”,也就是让r_t变小。 - 未裁剪项
r_t \hat{A}_t会随着r_t的减小而增加(因为Â_t是负的)。 - 裁剪项
clip(r_t, ...) \hat{A}_t会随着r_t的减小而增加,但当r_t小于1 - ε后,clip(r_t, ...)就固定在1 - ε,所以裁剪项也固定在(1 - ε) \hat{A}_t。 min函数会选择两者中较小的那个。- 当
r_t ≥ 1 - ε时,r_t \hat{A}_t ≥ (1 - ε) \hat{A}_t(因为Â_t < 0),此时min选择裁剪项(1 - ε) \hat{A}_t。 - 当
r_t < 1 - ε时,r_t \hat{A}_t < (1 - ε) \hat{A}_t,此时min选择未裁剪项r_t \hat{A}_t。
- 当
- 结果: 目标函数会奖励减小
r_t,但奖励的增加(损失的减小)只到r_t = 1 - ε为止。即使新策略想让r_t变得非常小(比如 0.01),目标函数也不会继续增加,从而限制了策略过度激进地减小坏动作的概率。
- 我们希望减小采取动作
如何实现稳定性与数据利用率?
通过这个裁剪机制,PPO 确保了在一次策略更新中,新策略 π_θ 相对于旧策略 π_θ_old 的变化(由 r_t 衡量)不会超过 [1 - ε, 1 + ε] 这个范围对目标函数的影响。
- 稳定性: 限制了每次更新的步长,避免了策略在训练过程中发生剧烈变化,从而提高了训练的稳定性,减少了崩溃的可能性。
- 数据利用率: 因为策略更新的幅度被限制了,新策略
π_θ与收集数据的旧策略π_θ_old之间的差异不会太大。这意味着由π_θ_old收集的数据在一定程度上仍然适用于训练π_θ。因此,PPO 可以在收集一批数据后,使用这批数据进行多次策略更新(多个 epoch),而不需要像传统策略梯度那样每次更新后都重新收集数据。这显著提高了数据的利用效率。
总结:
PPO 的裁剪目标函数通过 min 操作结合未裁剪和裁剪后的策略概率比乘以优势项,巧妙地限制了策略更新的幅度。当策略试图过度增加好动作的概率(r_t > 1 + ε, Â_t > 0)或过度减小坏动作的概率(r_t < 1 - ε, Â_t < 0)时,目标函数不再提供额外的优化信号。这种“近端”的更新方式使得 PPO 训练更加稳定,并且能够重复利用数据,提高了训练效率。
主要区别
- 策略更新: PPO 通过限制策略变化幅度来实现稳定训练,而 DPO 直接优化目标函数。
- 稳定性和效率: PPO 通常更稳定,但训练效率可能较低;DPO 更高效,但可能牺牲一些稳定性。
DPO 能够绕过显式奖励建模的关键理论基础
log(π*(y|x) / π_ref(y|x)) ∝ r*(x, y) 是理解 DPO (Direct Preference Optimization) 乃至更广泛的 RLHF (Reinforcement Learning from Human Feedback) 中 PPO (Proximal Policy Optimization) 方法的一个关键点。
让我们来分解这个公式:
π*(y|x): 最优策略 (Optimal Policy)。在给定输入(或提示)x的情况下,我们理想中希望模型生成的输出y的概率。这个策略是经过优化后,能够最好地满足人类偏好(或者说,在某个最优奖励函数下获得最高期望回报)的策略。π_ref(y|x): 参考策略 (Reference Policy)。这通常是一个预训练好的、或者经过初步监督微调 (SFT) 的语言模型。它作为优化的一个基准,我们不希望优化后的策略π*与这个参考策略偏离太远。这种偏离通常用 KL 散度来衡量和约束。log(...): 自然对数。π*(y|x) / π_ref(y|x): 最优策略与参考策略的概率比率。- 如果这个比率大于 1,意味着最优策略
π*更倾向于生成y(相比于参考策略π_ref)。 - 如果这个比率小于 1,意味着最优策略
π*不太倾向于生成y(相比于参考策略π_ref)。 - 取对数后,
log(π*(y|x) / π_ref(y|x)):- 如果大于 0,表示
π*比π_ref更喜欢y。 - 如果小于 0,表示
π*比π_ref更不喜欢y。 - 如果等于 0,表示两者对
y的偏好程度相同。
这个对数比率可以看作是从参考策略π_ref迁移到最优策略π*时,对输出y的“偏好增益”或“偏好变化”的一种度量。
- 如果大于 0,表示
- 如果这个比率大于 1,意味着最优策略
r*(x, y): 最优奖励函数 (Optimal Reward Function)。这是一个理想化的函数,它能够准确地给每一个由输入x产生的输出y打一个分数,这个分数反映了人类对这个(x, y)对的真实偏好程度。分数越高,表示人类越喜欢这个输出。∝: 正比于 (Proportional to) 符号。A ∝ B意味着A = k * B,其中k是一个非零常数(通常是正数,表示同向变化)。- 在这个上下文中,它意味着
log(π*(y|x) / π_ref(y|x))和r*(x, y)之间存在一个线性的、正相关的关系。当一个增加时,另一个也以固定的比例增加(或减少)。
整个公式 log(π*(y|x) / π_ref(y|x)) ∝ r*(x, y) 的含义:
最优策略 π* 相对于参考策略 π_ref 对某个输出 y 的对数概率比率,与该输出 y 在最优奖励函数 r* 下获得的奖励成正比。
换句话说:
- 如果一个输出
y能够获得很高的最优奖励r*(x, y),那么最优策略π*相比于参考策略π_ref会显著地更倾向于生成这个y(即log(π*/π_ref)会是一个较大的正数)。 - 如果一个输出
y获得的奖励很低(甚至是负的),那么最优策略π*相比于参考策略π_ref会更不倾向于生成这个y(即log(π*/π_ref)会是一个较大的负数或接近零)。
这个关系是如何来的?
它源于在 RLHF 中使用 PPO 算法(或其他类似的基于 KL 散度正则化的 RL 算法)时的理论推导。具体来说,PPO 的目标函数可以写成最大化期望奖励,同时惩罚与参考策略的 KL 散度:
maximize E [r(x,y)] - β * KL(π(y|x) || π_ref(y|x))
其中 β 是 KL 散度惩罚的权重。
通过变分法或其他优化理论可以推导出,满足这个优化目标的最优策略 π*(y|x) 和最优奖励函数 r*(x,y)(或者说,是驱动这个最优策略的那个奖励函数)之间存在如下关系:
进行详细推导一下这个关系。我们的目标是最大化以下目标函数:
$$J(\pi) = \mathbb{E}{(x,y) \sim \pi} [r(x,y)] - \beta \cdot D{KL}(\pi(\cdot|x) || \pi_{ref}(\cdot|x))$$
其中:
π(y|x)是我们想要优化的策略,表示在给定提示x时生成回答y的概率。r(x,y)是奖励函数,表示回答y对提示x的好坏程度。β > 0是一个超参数,控制 KL 散度惩罚的强度。D_{KL}(\pi(\cdot|x) || \pi_{ref}(\cdot|x))是 KL 散度,衡量当前策略π在给定x时与参考策略π_ref的差异。π_ref是一个固定的、预训练好的策略(通常是原始的 LLM)。
我们的任务是找到一个策略
π*(y|x),它能够最大化J(π)。为了简化问题,我们假设提示x是固定的,我们只关注如何优化给定x下的策略π(y|x)。因此,我们可以考虑目标函数关于x的条件期望:$$J_x(\pi) = \mathbb{E}{y \sim \pi(\cdot|x)} [r(x,y)] - \beta \cdot D{KL}(\pi(\cdot|x) || \pi_{ref}(\cdot|x))$$
我们将期望和 KL 散度展开:
$$J_x(\pi) = \sum_y \pi(y|x) r(x,y) - \beta \sum_y \pi(y|x) \log \frac{\pi(y|x)}{\pi_{ref}(y|x)}$$
$$J_x(\pi) = \sum_y \pi(y|x) r(x,y) - \beta \sum_y \pi(y|x) (\log \pi(y|x) - \log \pi_{ref}(y|x))$$
$$J_x(\pi) = \sum_y \pi(y|x) r(x,y) - \beta \sum_y \pi(y|x) \log \pi(y|x) + \beta \sum_y \pi(y|x) \log \pi_{ref}(y|x)$$
我们想要找到最大化
J_x(π)的策略π(y|x),同时满足概率分布的约束:π(y|x) ≥ 0对所有y成立。∑_y π(y|x) = 1对固定的x成立。
这是一个带约束的优化问题。我们可以使用拉格朗日乘子法 (Lagrangian Multiplier Method) 来解决。我们引入一个拉格朗日乘子
λ_x来处理等式约束∑_y π(y|x) - 1 = 0。我们构建拉格朗日函数L(π, λ_x):$$L(\pi, \lambda_x) = J_x(\pi) + \lambda_x \left( \sum_y \pi(y|x) - 1 \right)$$
$$L(\pi, \lambda_x) = \sum_y \pi(y|x) r(x,y) - \beta \sum_y \pi(y|x) \log \pi(y|x) + \beta \sum_y \pi(y|x) \log \pi_{ref}(y|x) + \lambda_x \left( \sum_y \pi(y|x) - 1 \right)$$
为了找到最优策略
π*(y|x),我们对拉格朗日函数关于每一个π(y|x)(对于特定的y)求偏导数,并令其等于零。注意,在求偏导时,只有包含π(y|x)这一项的项才会被保留。$$\frac{\partial L}{\partial \pi(y|x)} = \frac{\partial}{\partial \pi(y|x)} \left[ \pi(y|x) r(x,y) - \beta \pi(y|x) \log \pi(y|x) + \beta \pi(y|x) \log \pi_{ref}(y|x) + \lambda_x \pi(y|x) \right]$$
逐项求导:
∂/∂π(y|x) [π(y|x) r(x,y)] = r(x,y)(因为r(x,y)是常数)∂/∂π(y|x) [-β π(y|x) log π(y|x)] = -β (log π(y|x) + π(y|x) * (1/π(y|x))) = -β (log π(y|x) + 1)(使用乘积法则和d/du [u log u] = log u + 1)∂/∂π(y|x) [β π(y|x) log π_{ref}(y|x)] = β log π_{ref}(y|x)(因为log π_{ref}(y|x)是常数)∂/∂π(y|x) [λ_x π(y|x)] = λ_x
将这些偏导数相加并令其等于零,得到最优策略
π*(y|x)满足的条件:$$r(x,y) - \beta (\log \pi^*(y|x) + 1) + \beta \log \pi_{ref}(y|x) + \lambda_x = 0$$
现在,我们解出
log π*(y|x):$$-\beta \log \pi^*(y|x) = -r(x,y) + \beta - \beta \log \pi_{ref}(y|x) - \lambda_x$$
$$\beta \log \pi^*(y|x) = r(x,y) - \beta + \beta \log \pi_{ref}(y|x) + \lambda_x$$
$$\log \pi^*(y|x) = \frac{1}{\beta} r(x,y) - 1 + \log \pi_{ref}(y|x) + \frac{\lambda_x}{\beta}$$
$$\log \pi^*(y|x) = \log \pi_{ref}(y|x) + \frac{1}{\beta} r(x,y) + \left(\frac{\lambda_x}{\beta} - 1\right)$$
为了得到
π*(y|x),我们将等式两边进行指数化 (exponentiate):$$\pi^*(y|x) = \exp \left( \log \pi_{ref}(y|x) + \frac{1}{\beta} r(x,y) + \left(\frac{\lambda_x}{\beta} - 1\right) \right)$$
利用指数的性质
exp(a + b + c) = exp(a) * exp(b) * exp(c)和exp(log u) = u:$$\pi^*(y|x) = \exp(\log \pi_{ref}(y|x)) \cdot \exp\left(\frac{1}{\beta} r(x,y)\right) \cdot \exp\left(\frac{\lambda_x}{\beta} - 1\right)$$
$$\pi^*(y|x) = \pi_{ref}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x,y)\right) \cdot \exp\left(\frac{\lambda_x}{\beta} - 1\right)$$
注意,
exp(λ_x/β - 1)是一个常数,它只依赖于x(通过λ_x),而不依赖于y。我们可以将它记为一个归一化常数的一部分。令C(x) = exp(λ_x/β - 1),则:$$\pi^*(y|x) = C(x) \cdot \pi_{ref}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x,y)\right)$$
由于
π*(y|x)是一个概率分布,它必须满足∑_y π^*(y|x) = 1。我们可以用这个条件来确定C(x):$$\sum_y \pi^*(y|x) = \sum_y C(x) \cdot \pi_{ref}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x,y)\right) = 1$$
$$C(x) \sum_y \pi_{ref}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x,y)\right) = 1$$
$$C(x) = \frac{1}{\sum_y \pi_{ref}(y|x) \cdot \exp\left(\frac{1}{\beta} r(x,y)\right)}$$
分母
∑_y π_{ref}(y|x) exp((1/β) r(x,y))是一个归一化因子,通常记作Z(x)。所以,最优策略
π*(y|x)的精确形式是:$$\pi^*(y|x) = \frac{1}{Z(x)} \pi_{ref}(y|x) \exp\left(\frac{1}{\beta} r(x, y)\right)$$
这个公式的意义:
这个公式表明,最大化
E[r(x,y)] - β * KL(π || π_ref)这个目标函数的最优策略π*,与参考策略π_ref和奖励函数r之间存在一个特定的指数关系。具体来说,最优策略生成某个回答y的概率,正比于参考策略生成y的概率乘以exp((1/β) * r(x, y))。奖励r(x,y)越高,exp((1/β) * r(x, y))就越大,最优策略π*相对于参考策略π_ref来说,生成y的概率就会被放大得越多。参数β控制了这种放大的强度:β越小,1/β越大,奖励对策略的影响就越剧烈。DPO 如何利用这个关系?
DPO 并没有显式地使用这个公式来计算
π*。相反,DPO 假设人类偏好数据所隐含的那个“最优”策略π*和“最优”奖励函数r*满足这个关系。然后,它将这个关系变形,得到一个直接关于r*(x,y)的表达式:从
π^*(y|x) = \frac{1}{Z(x)} \pi_{ref}(y|x) \exp\left(\frac{1}{\beta} r^*(x, y)\right)我们可以解出
r*(x,y):$$\frac{\pi^(y|x)}{\pi_{ref}(y|x)} = \frac{1}{Z(x)} \exp\left(\frac{1}{\beta} r^(x, y)\right)$$
取对数:
$$\log\left(\frac{\pi^(y|x)}{\pi_{ref}(y|x)}\right) = \log\left(\frac{1}{Z(x)}\right) + \frac{1}{\beta} r^(x, y)$$
$$\frac{1}{\beta} r^(x, y) = \log\left(\frac{\pi^(y|x)}{\pi_{ref}(y|x)}\right) - \log(Z(x))$$
$$r^(x, y) = \beta \log\left(\frac{\pi^(y|x)}{\pi_{ref}(y|x)}\right) - \beta \log(Z(x))$$
这里的
- β log(Z(x))是一个只依赖于x的常数项。在计算奖励差r*(x, y_w) - r*(x, y_l)时,这个常数项会抵消掉。所以,DPO 得到的核心关系是:最优奖励函数
r*(x,y)与最优策略π*相对于参考策略π_ref的对数概率比log(π*(y|x) / π_ref(y|x))成线性关系。DPO 利用人类偏好数据
(x, y_w, y_l)来建模P(y_w > y_l | x) = sigmoid(r*(x, y_w) - r*(x, y_l))。然后,它将上面推导出的r*的表达式代入这个偏好模型中(只保留与y相关的部分,因为常数项在差值中抵消):r*(x, y_w) - r*(x, y_l) = β log(π*(y_w|x)/π_ref(y_w|x)) - β log(π*(y_l|x)/π_ref(y_l|x))P(y_w > y_l | x) = sigmoid( β log(π*(y_w|x)/π_ref(y_w|x)) - β log(π*(y_l|x)/π_ref(y_l|x)) )最后,DPO 假设我们当前正在训练的策略
π就是这个“最优”策略π*,然后直接最小化这个偏好概率的负对数似然损失:$$L_{DPO}(\pi) = - \log \left( \sigma \left( \beta \log \frac{\pi(y_w|x)}{\pi_{ref}(y_w|x)} - \beta \log \frac{\pi(y_l|x)}{\pi_{ref}(y_l|x)} \right) \right)$$
通过最小化这个损失,DPO 直接优化策略
π,使其满足人类偏好数据所隐含的概率关系,而无需显式地训练奖励模型或进行复杂的 RL 迭代。
π*(y|x) = (1/Z(x)) * π_ref(y|x) * exp((1/β) * r*(x, y))
对这个公式两边同时除以 π_ref(y|x),然后取对数,就可以得到:
log(π*(y|x) / π_ref(y|x)) = (1/β) * r*(x, y) - log(Z(x))
这里的 Z(x) 是分区函数,只依赖于 x。如果我们只关注 y 如何影响这个关系,并且将 1/β 视为一个常数,那么我们可以说:
log(π*(y|x) / π_ref(y|x)) 与 (1/β) * r*(x, y) 之间存在一个线性关系(忽略掉只依赖于 x 的项 -log(Z(x)),因为它不影响 y 之间的相对偏好)。
因此,可以简化地写成:
log(π*(y|x) / π_ref(y|x)) ∝ r*(x, y)
这里的比例常数 k 就约等于 1/β。
为什么这个关系重要?
DPO 的核心思想就是利用这个关系。它假设存在一个隐式的最优奖励函数 r*,并且人类的偏好数据(比如 y_w 比 y_l 好)反映了这个 r*。DPO 不去显式地学习 r*,而是直接利用 log(π_θ(y|x) / π_ref(y|x)) 作为 r*(x,y) 的一个代理(或成比例的量),然后基于 Bradley-Terry 模型等来构建损失函数,直接优化策略 π_θ 来匹配人类偏好。
所以,这个公式是连接“策略”和“奖励”的桥梁,是 DPO 能够绕过显式奖励建模的关键理论基础。
好的,我们来具体解释一下 π(y|x) 和 π_ref(y|x) 在大型语言模型 (LLM) 的语境下具体代表什么,并举例说明。
在 LLM 中,策略 π 就是指语言模型本身。它是一个函数,输入是一个文本序列(通常是提示 x),输出是下一个词(token)的概率分布。通过自回归地生成词,模型可以生成一个完整的回答 y。
所以,π(y|x) 和 π_ref(y|x) 都是指语言模型在给定提示 x 的情况下,生成完整回答 y 的概率。
π_ref(y|x)(参考策略):- 这通常是指原始的、未经对齐训练的预训练大型语言模型。
- 它的参数在 DPO 训练过程中是固定不变的。
- 它代表了模型在接受人类指令或偏好调整之前的行为模式。它可能已经具备了强大的语言生成能力,但可能不够安全、不够有用、不够符合人类的价值观,或者在遵循指令方面表现不佳。
π_ref(y|x)的计算方式是:给定提示x和回答y = (y_1, y_2, ..., y_L)(其中y_i是回答中的第i个词),生成整个序列y的概率是每个词在给定前面所有词和提示x的条件概率的乘积:
$$ \pi_{ref}(y|x) = \pi_{ref}(y_1|x) \cdot \pi_{ref}(y_2|x, y_1) \cdot \pi_{ref}(y_3|x, y_1, y_2) \cdots \pi_{ref}(y_L|x, y_1, \dots, y_{L-1}) $$
这里的π_ref(y_i | x, y_1, ..., y_{i-1})是指参考模型在看到提示x和已经生成的词y_1, ..., y_{i-1}后,生成下一个词y_i的概率。
π(y|x)(当前策略):- 这是我们正在训练和优化的语言模型。
- 它的参数在 DPO 训练过程中是不断更新的。
- 我们的目标是通过 DPO 训练,调整
π的参数,使其在给定提示x时,生成符合人类偏好的回答y_w的概率π(y_w|x)增加,而生成不符合偏好的回答y_l的概率π(y_l|x)降低,并且这种调整相对于π_ref的变化要符合人类的偏好程度。 π(y|x)的计算方式与π_ref(y|x)类似,只是使用的是当前策略π的参数:
$$ \pi(y|x) = \pi(y_1|x) \cdot \pi(y_2|x, y_1) \cdot \pi(y_3|x, y_1, y_2) \cdots \pi(y_L|x, y_1, \dots, y_{L-1}) $$
举例说明:
假设我们有一个提示 x:x = "请告诉我如何制作一杯咖啡。"
我们的原始预训练模型 π_ref 可能会生成两个回答:
y_w = "制作一杯咖啡的步骤:1. 准备咖啡豆和水。2. 研磨咖啡豆。3. 使用咖啡机或手冲壶冲泡。4. 享用你的咖啡。"(人类偏好)y_l = "咖啡是一种由咖啡豆制成的饮料。它通常是热的,并且含有咖啡因。"(人类拒绝,因为它没有回答问题)
在 DPO 训练之前,原始模型 π_ref 生成 y_w 的概率可能是 π_ref(y_w|x),生成 y_l 的概率是 π_ref(y_l|x)。可能 π_ref(y_w|x) 已经高于 π_ref(y_l|x),但差距不够大,或者在其他提示下,模型会生成更多像 y_l 这样不相关的回答。
DPO 的目标是训练一个新的模型 π,使得在给定提示 x 时:
π(y_w|x)应该比π_ref(y_w|x)更高。π(y_l|x)应该比π_ref(y_l|x)更低。- 更重要的是,
π(y_w|x) / π(y_l|x)这个比值,相对于π_ref(y_w|x) / π_ref(y_l|x)这个比值,要增加。增加的幅度由人类偏好数据中的其他样本以及β参数共同决定。
DPO 的损失函数会直接计算 log(π(y_w|x)/π_ref(y_w|x)) 和 log(π(y_l|x)/π_ref(y_l|x)),并将它们的差值输入 Sigmoid 函数。通过最小化损失,模型会调整 π 的参数,使得 log(π(y_w|x)/π_ref(y_w|x)) 倾向于变大,而 log(π(y_l|x)/π_ref(y_l|x)) 倾向于变小,从而直接实现对策略 π 的调整,使其更符合人类偏好。
总结:
π_ref(y|x)是固定的原始模型生成完整回答y的概率。π(y|x)是正在训练的模型生成完整回答y的概率。- DPO 通过优化一个损失函数,直接调整
π的参数,使得π相对于π_ref在生成偏好回答上的概率提升,大于在生成拒绝回答上的概率提升。这个过程直接利用了概率比,而无需显式地计算或预测奖励值。
DPO之前进行预训练:
预训练是构建 LLM 的第一阶段,其目标是让模型从海量的文本数据中学习到通用的语言知识、语法、事实信息、推理能力以及世界模型。经过预训练的模型通常已经非常强大,能够生成连贯、语法正确的文本,甚至回答问题和完成一些任务,但它们可能还不完全符合人类的特定指令、价值观或偏好(例如,可能生成有毒、有偏见或不相关的回答)。
这个预训练阶段产生的就是 DPO 中用作参考策略 π_ref 的那个模型。
主要的预训练方法:自监督学习 (Self-Supervised Learning)
LLM 的预训练主要依赖于一种叫做自监督学习的方法。这意味着模型从数据本身生成监督信号(标签),而不需要人类进行额外的标注。
最常见的用于训练生成式LLM(如 GPT 系列、Llama、Mistral 等)的自监督任务是:
因果语言建模 (Causal Language Modeling, CLM)
- 核心思想: 模型被训练来预测序列中的下一个词 (token)。
- 数据: 使用一个极其庞大和多样化的文本数据集,通常包含从互联网(如 Common Crawl)、书籍、维基百科、代码库等来源收集的数 TB 甚至 PB 级别的文本。
- 训练过程:
- 将文本数据切分成序列。
- 对于序列中的每一个位置
i,模型被要求根据它之前的所有词(token_1, token_2, ..., token_{i-1})来预测当前位置的词token_i。 - 模型使用 Transformer 架构(通常是 Decoder-only 的变体),这种架构天然适合处理序列数据并进行自回归生成(即一个接一个地生成词)。
- 训练目标是最小化预测下一个词的负对数似然 (Negative Log-Likelihood, NLL)。简单来说,就是最大化模型对训练数据中实际出现的下一个词的概率预测。
- 公式表示: 最小化以下损失函数:
$$ L_{CLM}(\theta) = - \mathbb{E}{\text{data}} \left[ \sum{i=1}^L \log \pi_\theta(token_i | token_1, \dots, token_{i-1}) \right] $$
其中θ是模型参数,L是序列长度,π_θ(token_i | \dots)是模型在给定前面词的情况下预测下一个词token_i的概率。 - 学习到的能力: 通过在海量文本上重复这个简单的“预测下一个词”任务,模型能够学习到:
- 语法和句法结构: 什么样的词序列是符合语法的。
- 语义和词义: 词语在不同上下文中的含义。
- 事实知识: 文本中包含的关于世界的信息(尽管是以参数记忆的方式)。
- 常识和推理: 文本中隐含的逻辑关系和推理模式。
- 不同风格和主题: 适应不同类型的文本。
- 生成连贯长文本的能力: 因为训练目标就是生成序列。
其他相关预训练任务 (较少用于 DPO 的基础模型):
- 掩码语言建模 (Masked Language Modeling, MLM): 像 BERT 这样的模型使用的任务,随机遮盖输入序列中的一些词,然后训练模型预测被遮盖的词。这更侧重于学习双向上下文表示,常用于理解类任务,而不是直接生成。
- 去噪自编码 (Denoising Autoencoding): 像 T5 这样的模型使用的任务,对输入序列进行破坏(如删除、替换、打乱词),然后训练模型恢复原始序列。这是一种更通用的序列到序列学习框架。
总结预训练过程:
预训练是一个计算密集型的过程,需要巨大的数据集、庞大的模型(数十亿到数万亿参数)和强大的计算资源(数千个 GPU 运行数周或数月)。它是一个无监督或自监督的过程,不涉及人类对模型输出的质量或偏好进行评估和标注。
预训练完成后,我们就得到了一个基础的、通用的语言模型。这个模型就是 DPO 中的 π_ref。它是一个强大的文本生成器,但它还没有被“对齐”到特定的人类偏好或指令。接下来的对齐阶段(如 DPO 或 RLHF)就是在这个预训练模型的基础上进行的微调,使其行为更符合我们的期望。
问题2:DPO训练可能遇到的问题
尽管 DPO (Direct Preference Optimization) 相比于基于 PPO 的 RLHF 流程更简单、更稳定,但在实际训练过程中仍然可能遇到一些问题。这些问题有些是大型语言模型微调固有的,有些则与 DPO 特有的机制有关。
以下是一些 DPO 训练可能遇到的问题:
数据质量和数量问题 (Data Quality and Quantity Issues):
- 问题: DPO 直接依赖于人类的成对偏好数据。如果这些数据质量不高(例如,标注者不一致、有偏见、标注错误)或者数量不足,模型将无法学到真正符合人类偏好的行为。
- 影响: 训练出的模型可能无法准确反映人类偏好,甚至学到不期望的行为模式。数据量不足可能导致过拟合。
- 与 DPO 的关联: DPO 将数据中的偏好信号直接转化为策略优化的目标。数据中的任何噪声或偏差都会直接影响策略的学习方向。虽然 DPO 避免了奖励模型的误差,但它对原始偏好数据的质量要求很高。
过拟合偏好数据 (Overfitting to Preference Data):
- 问题: 如果训练数据量相对较小,或者
β参数设置不当(过大),模型可能会过度拟合训练集中的特定偏好对,导致在未见的提示或回答上表现不佳,或者生成过于模式化、缺乏多样性的回答。 - 影响: 模型在训练集上表现很好,但在实际使用中泛化能力差。
- 与 DPO 的关联: DPO 的损失函数直接驱动策略去最大化偏好回答相对于拒绝回答的概率比。如果过度优化这个比值,可能会导致策略过于极端。
β参数在这里起到了类似 KL 散度惩罚的作用,防止策略偏离π_ref太远,从而缓解过拟合。但β的选择本身就是一个挑战。
- 问题: 如果训练数据量相对较小,或者
β参数的敏感性 (Sensitivity to β Parameter):- 问题:
β参数在 DPO 损失函数中平衡了偏好对齐和与参考策略π_ref的接近程度。选择合适的β值非常重要。 - 影响:
β过大:KL 惩罚作用弱,模型可能过度拟合偏好数据,偏离π_ref太远,导致生成不自然、重复或失去通用能力的文本。β过小:KL 惩罚作用强,模型会倾向于保持接近π_ref,可能无法充分学习偏好,导致对齐效果不明显。
- 与 DPO 的关联:
β是 DPO 核心公式中的关键超参数,直接影响优化目标的形态。它的调优是 DPO 实践中的一个重要环节。
- 问题:
灾难性遗忘 (Catastrophic Forgetting):
- 问题: 在微调过程中,模型可能会遗忘预训练阶段学到的一些通用能力、事实知识或生成多样化文本的能力。
- 影响: 微调后的模型可能在对齐任务上表现良好,但在处理其他通用任务时性能下降。
- 与 DPO 的关联: DPO 通过
log(π/π_ref)项和β参数隐式地包含了对π_ref的正则化,这有助于缓解灾难性遗忘。但如果β设置不当或训练数据分布与预训练数据差异太大,仍然可能发生遗忘。
数值稳定性问题 (Numerical Stability Issues):
- 问题: DPO 损失函数涉及概率比
π(y|x) / π_ref(y|x)的对数。如果π_ref(y|x)对于某个y的概率非常接近于零,或者π(y|x)相对于π_ref(y|x)变得非常大或非常小,计算对数和比值时可能出现数值溢出或下溢。 - 影响: 训练过程中出现 NaN (Not a Number) 或 Inf (Infinity),导致训练崩溃。
- 与 DPO 的关联: 这是直接计算概率比带来的潜在风险。虽然现代深度学习框架有一定鲁棒性,但在处理极低概率时仍需注意。
- 问题: DPO 损失函数涉及概率比
长文本生成和评估的挑战 (Challenges with Long Text Generation and Evaluation):
- 问题: LLM 生成的回答
y通常是长序列。计算π(y|x)和π_ref(y|x)需要对整个序列的条件概率进行乘积,这可能导致概率值非常小(尤其是对于长序列),增加数值计算的难度。同时,评估长文本的质量和偏好本身也是一个挑战。 - 影响: 概率计算可能不稳定;难以准确评估对齐效果。
- 与 DPO 的关联: DPO 的损失函数是基于整个序列概率的。虽然实际实现中通常在 token 级别计算梯度,但序列概率的计算仍然是基础。
- 问题: LLM 生成的回答
探索不足 (Insufficient Exploration):
- 问题: DPO 是一个基于最大化似然的优化过程,它直接优化现有数据中的偏好。它不像 RL 那样天然包含探索机制(例如,通过策略的随机性或 ε-greedy)。如果训练数据没有覆盖到所有重要的行为空间,模型可能不会学习到在未探索区域的良好行为。
- 影响: 模型可能在训练数据覆盖的范围内表现良好,但在需要探索新颖或非常规回答时表现受限。
- 与 DPO 的关联: DPO 本身不包含探索机制。它依赖于训练数据来展示期望的行为。
评估对齐效果的困难 (Difficulty in Evaluating Alignment):
- 问题: 衡量 LLM 是否真正“对齐”是一个开放性问题。自动评估指标(如 ROUGE, BLEU)无法捕捉人类偏好的细微差别。人类评估是黄金标准,但成本高昂且耗时。
- 影响: 即使训练损失下降,也很难确定模型在实际使用中是否真正变得更好、更安全、更有用。
- 与 DPO 的关联: 这是所有 LLM 对齐方法面临的共同挑战,并非 DPO 特有,但在实践中是判断 DPO 训练是否成功的关键。
总的来说,虽然 DPO 简化了 RLHF 的流程并提高了稳定性,但它并非没有挑战。高质量的偏好数据、仔细的超参数调优(尤其是 β)、以及对模型潜在遗忘和数值问题的关注,都是成功应用 DPO 的关键。
问题3:位置编码介绍及ROPE(相对位置编码)的优势
Transformer 需要位置编码以捕捉序列中的位置信息,因为其缺乏循环结构。位置编码分为:
绝对位置编码 (APE): 为每个位置赋予固定的唯一标识。
相对位置编码 (ROPE): 动态捕捉序列中的相对位置信息,提供更好的外推能力。在处理长度变化的序列时,ROPE 相比 APE 表现更优,
因其不依赖于绝对位置,能更好地处理序列中元素之间的相对关系。在 LLM 和处理序列数据的模型(特别是 Transformer 模型)中,“外推能力”通常指的是模型处理比训练时见过的序列更长的序列的能力。
为什么这是一个问题?
标准的 Transformer 模型在训练时通常会设定一个最大序列长度(例如 512、1024、2048 或 4096 个 token)。模型在训练过程中只看到和处理长度不超过这个最大值的序列。
许多早期的 Transformer 模型使用绝对位置编码 (Absolute Position Encoding, APE)。APE 为序列中的每一个绝对位置分配一个唯一的向量(或者通过一个函数生成)。例如,位置 0 对应向量
p_0,位置 1 对应p_1,位置 1023 对应p_1023。模型通过学习将这些位置向量与输入 token 的嵌入向量结合,从而理解 token 在序列中的位置信息。问题在于,如果模型在训练时最大长度是 1024,它就从未见过位置 1024、1025 或更靠后的位置对应的位置向量(例如
p_1024,p_1025等)。当你在推理时给它一个长度为 2000 的序列,模型在处理位置 1024 及之后的 token 时,会遇到它完全陌生的位置编码。它不知道这些位置编码代表什么,也不知道它们与其他位置编码之间的关系。这就像你只学过从 1 号到 100 号的门牌号,突然让你去找 200 号,你完全没有概念它在哪里,离 100 号有多远。结果就是,使用 APE 的模型在处理长度超过训练时最大长度的序列时,性能会显著下降,可能出现:
- 上下文丢失: 无法有效利用长距离的上下文信息。
- 生成不连贯: 生成的文本质量下降,逻辑混乱。
- 行为异常: 模型可能产生奇怪或重复的输出。
这就是缺乏外推能力的表现。模型无法将它在训练时学到的关于位置和序列结构的信息,“外推”到更长的序列上。
相对位置编码 (RPE) 如何提供更好的外推能力?
相对位置编码不关注 token 的绝对位置,而是关注 token 之间相对距离。当模型计算两个 token 之间的注意力分数时,它会考虑这两个 token 之间的相对距离(例如,相隔 5 个位置,或者前一个 token,后一个 token)。
RPE 的实现方式有很多种(例如 Transformer-XL 中的相对位置编码、DeBERTa 中的 disentangled attention 等),但核心思想是类似的:模型学习的是不同相对距离对应的权重或表示,而不是不同绝对位置对应的表示。
例如,模型可能学习到:
- 相邻两个 token (相对距离 1) 之间的关系。
- 相隔 10 个 token (相对距离 10) 之间的关系。
- 相隔 100 个 token (相对距离 100) 之间的关系。
通常,RPE 会对相对距离进行分桶 (bucketing) 或设定一个最大相对距离。例如,所有大于 512 的相对距离可能被视为同一个“非常远”的距离。
RPE 为什么能改善外推能力?
因为即使在一个非常长的序列中,许多 token 对之间的相对距离仍然可能落在模型在训练时见过的相对距离范围内。
举例:模型训练时最大长度 1024。
- 使用 APE:模型只见过绝对位置 0 到 1023。处理长度 2000 的序列时,位置 1024 到 1999 是全新的。
- 使用 RPE (最大相对距离 1023):模型见过相对距离 -1023 到 1023。处理长度 2000 的序列时,虽然绝对位置变了,但很多 token 对之间的相对距离(例如,相隔 500 个位置)仍然是模型在训练时见过的。即使是相隔 1500 个位置,如果设定了最大相对距离为 1023,这个距离可能被分到“大于 1023”的桶里,而这个桶模型在训练时(例如,处理长度 1024 序列中第一个和最后一个 token)也可能见过。
因此,RPE 使得模型学习到的位置信息更具泛化性。它学习的是“距离为 X 的两个 token 之间如何交互”,而不是“位置 A 的 token 和位置 B 的 token 如何交互”。这种基于相对距离的学习更容易“外推”到更长的序列,因为长序列中出现的相对距离模式与短序列中的模式有更多重叠。
问题4:Transformer 的结构整体介绍一下
Transformer 是一种基于自注意力机制的深度学习模型,广泛应用于自然语言处理任务中。其核心结构包括:
- Encoder和Decoder: Encoder 负责对输入序列进行编码,生成一组高维特征表示;Decoder 则根据这些表示和目标序列进行解码,生成最终输出。
- 多头自注意力机制 (Multi-Head Self-Attention): 通过多个注意力头并行处理序列数据,捕捉不同位置之间的依赖关系。
- 前馈神经网络 (Feed-Forward Network, FFN): 在注意力层后面,通过两层全连接网络对每个位置进行独立的非线性变换。
- 残差连接和LayerNorm: 通过残差连接和LayerNorm,避免梯度消失问题,同时加快模型的收敛速度。
问题5:BatchNorm与LayerNorm的区别及Transformer的选择
- BatchNorm: 主要用于卷积神经网络,通过标准化每个维度来减少内部协变量偏移。
- LayerNorm: 主要用于序列模型,如RNN和Transformer,对整个层进行标准化,独立于mini-batch。
问题6:PostNorm与PreNorm的优缺点
- PostNorm: 在注意力层和前馈网络后进行归一化,有助于后期训练效果,但前期训练可能不稳定。
- PreNorm: 在注意力层和前馈网络前进行归一化,增强模型初期稳定性,但可能影响深层网络的表现能力。
问题7:PostNorm与PreNorm都需要warm up吗?
Warm-up: 用于缓解训练初期梯度过大或过小的问题,帮助模型平稳过渡到正常训练。
- Warm-up (学习率热身)
- 是什么? Warm-up 是一种学习率调度策略 (Learning Rate Schedule)。它不是模型架构的一部分,而是训练过程中的一个技巧。
- 怎么做? 在训练刚开始的几个训练步 (steps) 或 epoch 中,学习率从一个非常小的值逐渐线性增加到预设的初始学习率。在 Warm-up 阶段结束后,学习率通常会继续按照其他调度策略(如衰减)进行调整。
- 为什么用?
- 稳定性: 在训练刚开始时,模型的参数是随机初始化的,梯度可能非常大且不稳定。使用一个较大的初始学习率可能导致模型参数剧烈震荡,甚至发散,无法收敛。Warm-up 阶段使用小的学习率,可以给模型一个“热身”的机会,让参数在初始阶段进行更温和的调整,进入一个相对稳定的区域,然后再使用较大的学习率进行更快的收敛。
- 优化器特性: 特别是对于 Adam 等自适应学习率优化器,它们在计算更新时会用到梯度的平方和。在训练初期,梯度信息不稳定,平方和可能很小,导致计算出的有效学习率过大,加剧不稳定。Warm-up 可以缓解这个问题。
- 类比: 就像运动员在剧烈运动前需要热身一样,让身体逐渐适应,避免受伤。模型的训练也需要一个“热身”阶段来避免训练初期的“震荡”或“受伤”。
- Warm-up (学习率热身)
PreNorm: 通常不需要warm-up,因为归一化使得初期梯度更新稳定。
PostNorm: 通常需要warm-up,因为初期训练时梯度可能不稳定,warm-up能有效缓解这个问题。
8.平安产险科技中心算法一面面试题9道
问题1:大模型有哪些可选参数?
在训练和调优大模型时,有几个关键参数可以选择和调整:
- 学习率(Learning Rate):影响模型收敛速度和稳定性。
- 批量大小(Batch Size):影响训练稳定性和内存占用,较大的批量大小通常可以加快训练速度,但也需要更多的内存。
- 模型层数(Number of Layers):决定模型的深度,层数越多,模型的表达能力越强,但训练难度也增加。
- 隐藏层维度(Hidden Size):影响模型的参数量和计算复杂度。
- 头数(Number of Attention Heads):影响自注意力机制的表现,更多的头数可以使模型更好地捕捉多种不同的关系。
- 正则化参数(如Dropout率):防止过拟合的重要因素。
- 温度(Temperature):在生成阶段影响输出的多样性和随机性。
问题2:Transformer的mask是如何操作的?
Transformer模型使用mask主要有两个目的:
- 防止信息泄露:在训练自回归模型(如GPT系列)时,模型在生成每个单词时只能看到它前面的单词。为了实现这一点,使用了“前向mask”。
这种mask通常是一个上三角矩阵,其中位置(i, j)的值为1(表示masked),如果i < j,否则为0。这样,在计算自注意力时,模型只关注当前单词及其之前的单词。 - 填充mask:在处理不同长度的输入序列时,通常会对较短的序列进行填充(padding),以使它们具有相同的长度。
为了防止模型在计算时关注填充部分,使用填充mask。填充mask通常会为填充的部分设置为1(masked),而非填充的部分为0。这样,模型在计算自注意力时就会忽略填充的部分。
问题3:Self attention的公式是什么,为什么要除以sqrt
Self Attention的公式为:
$$[ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V ]$$
其中, $( d_k )$ 是键向量的维度。除以 $( \sqrt{d_k} )$ 是为了防止在高维空间中,点积的值过大,从而导致softmax函数的梯度消失,确保梯度更平稳,提升训练效果。
问题4:Temperature的大小如何影响分布?
温度参数在模型生成阶段起着调节作用:
- 低温度(如0.5):会使概率分布更加集中,生成的输出更加确定,通常会导致重复和常见的输出,因为模型倾向于选择高概率的词。
- 高温度(如1.5):会使概率分布变得更平坦,增加生成输出的随机性,使得模型更可能选择低概率的词,从而增加多样性和创新性,
但也可能导致输出的质量下降,生成不相关或无意义的内容。
总的来说,温度的选择依赖于具体应用的需求:如果需要更具创新性和多样性的输出,可以选择较高的温度;如果需要更稳定和可靠的输出,可以选择较低的温度。
问题5:Attention的复杂度是多少?
Attention机制的时间复杂度为 $O(n^2 * d)$(n为输入序列长度,d为特征维度:token维度),因为对于每个输入元素都需要计算与所有其他元素的相似度。
问题6:什么情况下,MAP的损失函数可以用NMSE来计算?
好的,我们来详细解释 MAP、NMSE 以及在什么情况下 MAP 的损失函数可以用 NMSE(或更准确地说,是 MSE,均方误差)来计算。
1. MAP (Maximum A Posteriori, 最大后验估计)
- 是什么? MAP 是一种在贝叶斯统计框架下估计模型参数的方法。它的目标是找到使后验概率 (Posterior Probability) 最大的参数值。
- 后验概率: $P(\theta | D)$,表示在给定观测数据 $D$ 的情况下,参数 $\theta$ 的概率。
- 目标: $\hat{\theta}{MAP} = \arg \max{\theta} P(\theta | D)$
- 根据贝叶斯定理: $P(\theta | D) = \frac{P(D | \theta) P(\theta)}{P(D)}$
- $P(D | \theta)$ 是似然 (Likelihood):在给定参数 $\theta$ 的情况下,观测到数据 $D$ 的概率。
- $P(\theta)$ 是先验概率 (Prior Probability):在观测到数据之前,我们对参数 $\theta$ 的信念或已知信息。
- $P(D)$ 是数据的边缘概率,对于给定的数据是常数,不依赖于 $\theta$。
- 最大化后验概率等价于最大化 $P(D | \theta) P(\theta)$ (因为分母 $P(D)$ 是常数)。
- 为了计算方便,通常最大化其对数 (对数是单调函数,不改变最大值的位置):
$$ \hat{\theta}{MAP} = \arg \max{\theta} \log [P(D | \theta) P(\theta)] = \arg \max_{\theta} [\log P(D | \theta) + \log P(\theta)] $$ - 等价于最小化负对数后验概率:
$$ \hat{\theta}{MAP} = \arg \min{\theta} [-\log P(D | \theta) - \log P(\theta)] $$ - MAP 损失函数的形式: $L_{MAP}(\theta) = -\log P(D | \theta) - \log P(\theta)$
- 第一项 $-\log P(D | \theta)$ 是负对数似然 (Negative Log-Likelihood, NLL)。它衡量了模型在多大程度上解释了观测数据。
- 第二项 $-\log P(\theta)$ 是负对数先验。它根据我们对参数的先验信念对参数进行惩罚,可以看作是一种正则化项。
2. NMSE (Normalized Mean Squared Error, 归一化均方误差)
- 是什么? NMSE 是一种常用的评估指标 (Evaluation Metric),用于衡量预测值 ($\hat{y}$) 与真实值 ($y$) 之间的平均差异,并进行了归一化。它通常用于回归或估计任务。
- MSE (Mean Squared Error, 均方误差): NMSE 是基于 MSE 的。MSE 的定义是预测值与真实值差值的平方的平均值:
$$ \text{MSE} = \frac{1}{N} \sum_{i=1}^N (\hat{y}_i - y_i)^2 $$
其中 $N$ 是数据点的数量,$\hat{y}_i$ 是第 $i$ 个数据点的预测值,$y_i$ 是第 $i$ 个数据点的真实值。 - NMSE 的归一化: NMSE 在 MSE 的基础上除以一个归一化因子,常见的归一化因子包括真实值的方差、真实值的平均平方值等。例如:
$$ \text{NMSE} = \frac{\text{MSE}}{\text{Var}(y)} = \frac{\frac{1}{N} \sum_{i=1}^N (\hat{y}i - y_i)^2}{\frac{1}{N} \sum{i=1}^N (y_i - \bar{y})^2} $$
或者
$$ \text{NMSE} = \frac{\mathbb{E}[(\hat{y} - y)^2]}{\mathbb{E}[y^2]} $$ - NMSE 通常用作评估模型性能的指标,而不是直接用于模型训练的损失函数。 然而,MSE 本身是一个非常常见的损失函数,尤其是在回归问题中。用户的问题很可能是指在什么情况下,MAP 的损失函数等价于最小化 MSE。
3. 什么情况下 MAP 的损失函数可以用 MSE 来计算?
MAP 的损失函数是 $L_{MAP}(\theta) = -\log P(D | \theta) - \log P(\theta)$。要让它等价于最小化 MSE,需要满足两个条件:
条件 1:似然函数必须是高斯分布 (Gaussian Likelihood)
- 假设我们正在进行一个回归任务,模型预测输出 $\hat{y} = f_\theta(x)$,真实输出是 $y$。我们假设真实输出 $y$ 是由模型的预测值 $f_\theta(x)$ 加上一些随机噪声 $\epsilon$ 产生的:$y = f_\theta(x) + \epsilon$。
- 如果这个噪声 $\epsilon$ 服从均值为 0、方差为 $\sigma^2$ 的高斯分布,即 $\epsilon \sim \mathcal{N}(0, \sigma^2)$,那么在给定输入 $x$ 和参数 $\theta$ 的情况下,输出 $y$ 也服从一个高斯分布,其均值为 $f_\theta(x)$,方差为 $\sigma^2$:$y | x, \theta \sim \mathcal{N}(f_\theta(x), \sigma^2)$。
- 高斯分布的概率密度函数 (PDF) 是:$p(y | \mu, \sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y - \mu)^2}{2\sigma^2}\right)$。
- 对于数据集 $D = {(x_i, y_i)}{i=1}^N$,假设数据点之间是独立的,则似然函数是各个数据点概率的乘积:
$$ P(D | \theta) = \prod{i=1}^N P(y_i | x_i, \theta) = \prod_{i=1}^N \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - f_\theta(x_i))^2}{2\sigma^2}\right) $$ - 计算负对数似然:
$$ -\log P(D | \theta) = -\log \left( \prod_{i=1}^N \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{(y_i - f_\theta(x_i))^2}{2\sigma^2}\right) \right) $$
$$ = -\sum_{i=1}^N \left[ \log\left(\frac{1}{\sqrt{2\pi\sigma^2}}\right) - \frac{(y_i - f_\theta(x_i))^2}{2\sigma^2} \right] $$
$$ = -N \log\left(\frac{1}{\sqrt{2\pi\sigma^2}}\right) + \frac{1}{2\sigma^2} \sum_{i=1}^N (y_i - f_\theta(x_i))^2 $$ - 在这个表达式中,第一项 $-N \log(1/\sqrt{2\pi\sigma^2})$ 是一个常数,不依赖于参数 $\theta$。第二项 $\frac{1}{2\sigma^2} \sum_{i=1}^N (y_i - f_\theta(x_i))^2$ 与残差平方和 (Sum of Squared Errors, SSE) 成正比。最小化 SSE 等价于最小化 MSE (因为 MSE = SSE / N)。
- 结论: 当假设观测数据中的噪声服从高斯分布时,最小化负对数似然等价于最小化均方误差 (MSE),忽略常数项和比例因子 $1/(2\sigma^2)$。
条件 2:先验分布必须是均匀分布 (Uniform Prior)
- MAP 损失函数是 $L_{MAP}(\theta) = -\log P(D | \theta) - \log P(\theta)$。
- 如果对参数 $\theta$ 使用均匀先验,即在一个合理的范围内 $P(\theta)$ 是一个常数(例如,所有参数值在这个范围内具有相同的可能性),那么 $-\log P(\theta)$ 也是一个常数。
- 在这种情况下,MAP 损失函数变为:$L_{MAP}(\theta) = -\log P(D | \theta) - \text{Constant}$。
- 最小化这个损失函数就等价于最小化 $-\log P(D | \theta)$。
综合两个条件:
只有当似然函数是高斯分布(对应于数据中的高斯噪声)并且先验分布是均匀分布时,MAP 的优化目标(最小化负对数后验)才等价于最小化均方误差 (MSE)。
在这种特定情况下,MAP 估计的结果与最大似然估计 (MLE) 的结果是相同的,因为均匀先验不提供任何关于参数的额外信息,MAP 退化为 MLE。而对于高斯似然,MLE 的损失函数就是负对数似然,我们已经证明它等价于 MSE。
如果先验不是均匀分布呢?
如果先验分布不是均匀分布(例如,常用的高斯先验或拉普拉斯先验),那么 $-\log P(\theta)$ 项就不是常数,它会作为一个正则化项出现在 MAP 的损失函数中。
- 高斯先验 $P(\theta) \propto \exp(-\frac{|\theta|^2}{2\sigma_\theta^2})$: $-\log P(\theta) \propto |\theta|^2 = \sum \theta_j^2$。MAP 损失函数将变为 MSE + L2 正则化。
- 拉普拉斯先验 $P(\theta) \propto \exp(-\lambda |\theta|_1)$: $-\log P(\theta) \propto |\theta|_1 = \sum |\theta_j|$。MAP 损失函数将变为 MSE + L1 正则化。
总结:
- MAP 是一种贝叶斯估计方法,目标是最大化后验概率,其损失函数是负对数似然加上负对数先验。
- NMSE 是一种评估指标,基于 MSE,用于衡量预测误差。MSE 本身常被用作损失函数。
- MAP 的损失函数可以等价于最小化 MSE 仅当:
- 假设观测数据中的噪声服从高斯分布 (Gaussian Likelihood)。
- 对模型参数使用均匀先验 (Uniform Prior)。
在其他情况下(例如,非高斯似然或非均匀先验),MAP 的损失函数将是负对数似然加上一个非恒定的正则化项,通常不是简单的 MSE。
问题7:vector扩容方法是什么?
std::vector 在其容量不足以容纳新元素时,会进行扩容。扩容通常是倍增策略,即当元素数量达到当前容量时,新的容量会设置为原来容量的两倍。
这样做可以保持摊销的时间复杂度为 $O(1)$ 。扩容时,vector会分配新的内存,将旧元素复制到新内存中,然后释放旧内存。
问题8:智能指针、虚函数?
智能指针:是一种自动管理内存的指针类型,常见于C++,如
std::unique_ptr和std::shared_ptr。它们可以防止内存泄漏,通过引用计数和作用域控制自动释放内存。虚函数:在基类中声明为
virtual的成员函数,用于实现多态性。通过虚函数,派生类可以重写基类的方法,从而在运行时决定调用哪个版本。