LangChain
LangChain 介绍
适用LangChain 0.3
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。它使得应用程序能够:
- 具有上下文感知能力:将语言模型连接到上下文来源(提示指令,少量的示例,需要回应的内容等)
- 具有推理能力:依赖语言模型进行推理(根据提供的上下文如何回答,采取什么行动等)
这个框架由几个部分组成。
- LangChain 库:Python 和 JavaScript 库。包含了各种组件的接口和集成,一个基本的运行时,用于将这些组件组合成链和代理,以及现成的链和代理的实现。
- LangChain 模板:一系列易于部署的参考架构,用于各种任务。
- LangServe:一个用于将 LangChain 链部署为 REST API 的库。
- LangSmith:一个开发者平台,让你可以调试、测试、评估和监控基于任何 LLM 框架构建的链,并且与 LangChain 无缝集成。
LangChain 库
LangChain 包的主要价值主张是:
- 组件:用于处理语言模型的可组合工具和集成。无论你是否使用 LangChain 框架的其余部分,组件都是模块化的,易于使用
- 现成的链:用于完成高级任务的组件的内置组合
现成的链使得开始变得容易。组件使得定制现有链和构建新链变得容易。
LangChain 库本身由几个不同的包组成。
langchain-core:基础抽象和 LangChain 表达式语言。langchain-community:第三方集成。langchain:构成应用程序认知架构的链、代理和检索策略。
开始使用
1 | cd LangChain |
uv pyproject.toml
1 | [project] |
deepseek
1 | import getpass |
OpenAI和ChatOpenAI
如果不使用OpenAI 文本补全模型如gpt-3.5-turbo-instruct,不要调用这个作为兼容openai服务的接口,请使用ChatOpenAI
使用ChatOpenAI调用Openrouter服务
1 | from langchain_openai import ChatOpenAI |
Chaining
我们可以像这样将模型与提示模板连接起来:
1 | from langchain_core.prompts import ChatPromptTemplate |
Tool calling
通过 ChatOpenAI.bind_tools ,我们可以方便地将 Pydantic 类、字典模式、LangChain 工具或函数作为工具传递给模型。在后台,这些内容会被转换为 OpenAI 工具模式,其形式如下:
1 | { |
并在每次模型调用时传递。
1 | from pydantic import BaseModel, Field |
这段 Python 代码使用了 pydantic 库来定义一个数据模型,名为 GetWeather。pydantic 是一个非常流行的数据验证和设置管理库,它利用 Python 的类型提示来强制数据模式。
让我们逐行分解这段代码:
from pydantic import BaseModel, Field:- 这行代码从
pydantic库中导入了两个关键组件:BaseModel: 这是一个基类。所有pydantic模型都必须继承自BaseModel。它提供了数据验证、序列化(例如,转换为 JSON)、反序列化(例如,从 JSON 加载)等核心功能。Field: 这是一个函数(也是一个类),用于为模型字段提供额外的配置和元数据,例如默认值、描述、验证约束等。
- 这行代码从
class GetWeather(BaseModel)::- 这行代码定义了一个新的 Python 类,名为
GetWeather。 - 通过继承
BaseModel,GetWeather类自动获得了pydantic提供的所有数据模型功能。 - 这个模型通常用于表示某种结构化的数据,比如 API 请求的参数、函数的输入、数据库记录等。从类名和文档字符串来看,这个模型很可能是用来表示获取天气信息的请求参数。
- 这行代码定义了一个新的 Python 类,名为
"""Get the current weather in a given location""":- 这是一个文档字符串 (docstring)。它为
GetWeather类提供了人类可读的描述。 pydantic也会使用这个文档字符串。例如,在自动生成 OpenAPI (Swagger) schema 时,这个描述会作为模型的描述。
- 这是一个文档字符串 (docstring)。它为
location: str = Field(..., description="The city and state, e.g. San Francisco, CA"):- 这行代码在
GetWeather模型中定义了一个名为location的字段 (field)。 location: str:location: 这是字段的名称。: str: 这是 Python 的类型提示,表明location字段的值必须是一个字符串 (string)。如果尝试用非字符串类型的值来创建GetWeather实例(并且该值不能被自动转换成字符串),pydantic会抛出验证错误。
= Field(...):- 这里使用了
Field函数为location字段提供额外的配置。 ...(省略号,Ellipsis): 当Field的第一个参数是...时,它表示这个字段是必需的 (required)。这意味着在创建GetWeather类的实例时,必须为location字段提供一个值。如果不提供,pydantic会报错。description="The city and state, e.g. San Francisco, CA":- 这为
location字段提供了一个描述性的字符串。 - 这个描述非常有用:
- 文档性: 帮助其他开发者(或未来的你)理解这个字段的含义和期望的格式。
- 自动生成文档:
pydantic可以利用这个描述来自动生成 API 文档 (例如 OpenAPI schema),其中会包含这个字段的描述。 - 工具提示或帮助文本: 在某些 UI 框架或工具中,这个描述可能会被用作输入字段的提示信息。
- 这为
- 这里使用了
- 这行代码在
总结这段代码的意思:
这段代码定义了一个名为 GetWeather 的数据结构(或模型),它期望有一个名为 location 的字段。这个 location 字段:
- 必须被提供 (因为
Field(...)中的...)。 - 其值必须是一个字符串 (因为类型提示
: str)。 - 用于表示获取天气信息的目标地点,并且其描述建议格式为 “城市, 州” (例如 “San Francisco, CA”)。
什么是 Field?
在 pydantic 的上下文中,Field 是一个非常重要的工具,它允许你对模型的字段进行详细的声明和约束。你可以将其视为对简单类型提示的增强。
使用 Field 可以做到:
- 设置默认值:
my_field: str = Field(default="some_value")或简写为my_field: str = "some_value"(如果不需要其他Field参数)。 - 标记字段为必需:
my_field: str = Field(...)或简写为my_field: str(如果该字段没有默认值,则默认为必需)。 - 添加描述:
my_field: str = Field(description="This is my field.") - 设置别名:
my_field: str = Field(alias="myFieldFromJSON")(例如,当 JSON 中的字段名与 Python 变量名规范不同时)。 - 添加验证约束:
min_length,max_length(用于字符串、列表等)gt(大于),ge(大于等于),lt(小于),le(小于等于) (用于数字)pattern(用于字符串,使用正则表达式)- 等等。
- 控制序列化/反序列化行为: 例如,是否在导出时包含该字段。
- 提供示例值:
my_field: str = Field(default="example", examples=["example1", "example2"])
示例用法:
1 | from pydantic import BaseModel, Field, ValidationError |
我们现在可以利用消息历史再次调用模型:
1 | messages = [ |
我们还可以使用上一次响应的 ID,而不是返回整个序列:
1 | previous_response_id = response.response_metadata["id"] |
ChatOutlines
安装
uv pip install -qU langchain-community outlines
初始化
1 | from langchain_community.chat_models.outlines import ChatOutlines |
调用
1 | from langchain_community.chat_models.outlines import ChatOutlines |
Outlines功能:
报错:
match term:
^
SyntaxError: invalid syntax
python 版本低,不支持match
1 | ModuleNotFoundError: No module named 'numpy.lib.function_base' |
outlines库存在问题
如何从模型返回结构化数据
这是获取结构化输出的最简单且最可靠的方法。 with_structured_output() 适用于提供原生 API 以结构化输出的模型(例如工具/函数调用或 JSON 模式),并在底层利用这些功能。
这种方法以模式作为输入,该模式定义了期望输出属性的名称、类型和描述。该方法返回一个类似模型的可运行对象,但与输出字符串或消息不同,它输出与给定模式相对应的对象。模式可以指定为 TypedDict 类、JSON 模式或 Pydantic 类。如果使用 TypedDict 或 JSON 模式,Runnable 将返回一个字典;如果使用 Pydantic 类,Runnable 将返回一个 Pydantic 对象。
1.Pydantic
1 | model= "openai/gpt-4o-mini" |
2.TypedDict
如果你不想使用 Pydantic,明确不想验证参数,或者需要能够流式传输模型输出,你可以通过 TypedDict 类来定义你的模式。
from typing import Optional
from typing_extensions import Annotated, TypedDict
1 | class Joke(TypedDict): |
1. Pydantic 模型 (
pydantic.BaseModel)核心功能:数据验证、序列化/反序列化、设置管理、自动生成数据 schema (如 JSON Schema)。
定义方式:
继承自
pydantic.BaseModel,使用 Python 类型提示来定义字段。1
2
3
4
5
6
7
8PYTHONfrom pydantic import BaseModel, Field
from typing import Optional
class UserProfile(BaseModel):
username: str
email: str
age: Optional[int] = Field(None, ge=18, description="User's age, must be 18 or older if provided")
is_active: bool = True优点:
- 强大的数据验证: 在运行时自动检查数据类型、约束(如最小值、最大值、正则表达式匹配等)。如果数据不符合定义,会抛出详细的
ValidationError。 - 类型转换: 可以自动进行一些类型转换(例如,将数字字符串转换为整数)。
- 序列化/反序列化: 轻松将模型实例转换为字典 (
.model_dump())、JSON (.model_dump_json()),或从这些格式创建模型实例 (.model_validate(),.model_validate_json())。 - IDE 支持和静态分析: 由于使用类型提示,IDE 和静态分析工具(如 MyPy)可以很好地理解和检查代码。
- 文档生成: 可以从模型定义(包括
Field中的description)自动生成文档或 API schema (如 OpenAPI)。 - 配置管理: 可以从环境变量、
.env文件等加载配置。 - 可扩展性: 支持自定义验证器、计算字段等。
- 强大的数据验证: 在运行时自动检查数据类型、约束(如最小值、最大值、正则表达式匹配等)。如果数据不符合定义,会抛出详细的
缺点:
- 依赖第三方库: 需要安装
pydantic。 - 运行时开销: 数据验证和转换会带来一些运行时开销,尽管 Pydantic 经过优化,性能通常很好。
- 依赖第三方库: 需要安装
LangChain 中的用途:
- 定义工具的输入输出 schema: 这是 Pydantic 在 LangChain 中最常见的用途。当 LLM 需要调用一个工具时,它需要知道工具接受什么参数以及参数的类型和约束。Pydantic 模型是定义这些 schema 的理想选择。
- 定义 Output Parsers 的目标结构:
PydanticOutputParser可以将 LLM 的输出解析为 Pydantic 模型实例。 - 配置模型和链的参数。
- 定义结构化数据载体。
2. TypedDict 类 (
typing.TypedDict)核心功能:为字典提供类型提示,主要用于静态类型检查。
定义方式:
继承自
typing.TypedDict,像类一样定义键和对应的值类型。1
2
3
4
5
6
7PYTHONfrom typing import TypedDict, Optional
class UserProfileDict(TypedDict):
username: str
email: str
age: Optional[int]
is_active: bool # TypedDict 默认所有键都是必需的,除非用 NotRequired 或 Total=False或者使用函数式语法:
1
2
3
4
5PYTHON
UserProfileDictFunc = TypedDict('UserProfileDictFunc', {'username': str, 'email': str, 'age': Optional[int], 'is_active': bool})优点:
- 轻量级: 它是 Python 标准库
typing的一部分(从 Python 3.8 开始),不需要额外安装。 - 静态类型检查: 主要目的是帮助静态类型检查器(如 MyPy, Pyright)在编码阶段发现字典键名错误或值类型不匹配的问题。
- 运行时无开销:
TypedDict在运行时本质上仍然是一个普通的dict。它不进行运行时验证或转换。
- 轻量级: 它是 Python 标准库
缺点:
- 无运行时验证: 如果传入的数据不符合
TypedDict的定义(例如,键名错误、类型错误),程序在运行时不会自动报错,除非你显式地访问了错误的键或对错误类型的值进行了操作。 - 无序列化/反序列化帮助: 它只是一个类型注解,不提供像 Pydantic 那样的序列化/反序列化方法。
- 功能相对简单: 不支持默认值(除非与
total=False和NotRequired结合使用,但仍不直接)、描述、高级验证约束等 Pydantic 提供的功能。
- 无运行时验证: 如果传入的数据不符合
LangChain 中的用途:
- 在一些内部实现或简单场景中,如果只需要静态类型提示而不需要运行时的验证和功能,可能会用到。
- 当与期望普通字典作为输入/输出的旧代码或库交互时。
- 在 LCEL 中,字典通常被隐式地当作
RunnableParallel的输入/输出,TypedDict可以帮助静态检查这些字典的结构。
3. LangChain 工具对象 (
langchain_core.tools.BaseTool或其子类,如Tool)核心功能:定义一个可被 LLM (通常是 Agent) 调用的操作或函数,包含名称、描述、输入参数 schema 和执行逻辑。
定义方式:
- 通常通过实例化
Tool类,并提供name,description,func(执行工具的函数) 和可选的args_schema(通常是一个 Pydantic 模型)。 - 或者通过装饰器
@tool来简化创建。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34PYTHONfrom langchain_core.tools import Tool
from pydantic import BaseModel, Field
from typing import Type
# 1. 定义输入 schema (使用 Pydantic)
class SearchInput(BaseModel):
query: str = Field(description="The search query")
# 2. 定义工具的执行函数
def search_function(query: str) -> str:
# 实际的搜索逻辑
return f"Search results for: {query}"
# 3. 创建 Tool 对象
search_tool = Tool(
name="WebSearch",
description="A tool to search the web for information.",
func=search_function,
args_schema=SearchInput # 指定输入参数的 Pydantic schema
)
# 或者使用 @tool 装饰器 (更简洁)
from langchain.tools import tool
def get_weather(location: str) -> str:
"""Returns the current weather in the specified location."""
# 实际获取天气的逻辑
return f"The weather in {location} is sunny."
# get_weather 现在是一个 Tool 对象
# get_weather.name -> "get_weather"
# get_weather.description -> "Returns the current weather in the specified location."
# get_weather.args_schema 会被自动从函数签名推断 (如果类型提示是 Pydantic 模型,则更好)- 通常通过实例化
优点:
- LLM 可调用: 专门设计为能被 LangChain 中的 Agent 理解和调用。Agent 会根据工具的
name和description来决定何时使用哪个工具,并根据args_schema来构造调用参数。 - 封装了执行逻辑: 将工具的定义(元数据)和实现(函数)封装在一起。
- 与 LangChain 生态集成: 无缝集成到 LangChain 的 Agent、链等组件中。
- LLM 可调用: 专门设计为能被 LangChain 中的 Agent 理解和调用。Agent 会根据工具的
缺点:
- 特定于 LangChain: 主要用于 LangChain 框架内。
- 其
args_schema通常依赖于 Pydantic 模型来获得最佳的类型安全和描述能力。
LangChain 中的用途:
- 核心用途: 定义 Agents 可以使用的能力。这是 LangChain 工具对象的主要目的。
区别总结:
特性 Pydantic 模型 ( BaseModel)TypedDictLangChain 工具 ( Tool)主要目的 数据验证、序列化、结构定义 字典的静态类型提示 定义 LLM 可调用的操作/函数 运行时验证 是 (核心功能) 否 间接通过 args_schema(通常是 Pydantic)序列化 是 (内置方法) 否 否 (关注执行和元数据) 依赖 pydantic(第三方库)typing(标准库)langchain_core等 (LangChain 库)LangChain 角色 工具参数 schema, 输出解析, 配置等 简单字典类型提示 (较少直接用于核心组件) Agent 的可调用能力 元数据 描述, 默认值, 约束等 无 (仅类型) 名称, 描述, 执行函数, 参数 schema 主流是什么?
这三者并不是相互排斥的,它们经常协同工作,尤其是在 LangChain 中。
- Pydantic 模型是绝对的主流,用于定义结构化数据、API 请求/响应体、配置文件以及 LangChain 工具的参数 schema。 它的数据验证和序列化能力使其在现代 Python 应用开发中非常流行,远不止于 LangChain。几乎所有需要可靠数据交换的场景都可以从 Pydantic 中受益。
- LangChain 工具对象是 LangChain 中构建 Agent 的核心。 当你需要让 LLM 能够执行外部操作时,你就会创建或使用工具对象。而这些工具对象的参数 (
args_schema) 强烈推荐使用 Pydantic 模型来定义,以获得最佳的类型安全、描述性和 LLM 的理解能力。 - TypedDict 主要用于静态类型检查的场景,当你只需要确保字典的结构在编码时是正确的,而不需要运行时的验证或 Pydantic 的其他高级功能时。 它更轻量级。在 LangChain 中,你可能在一些内部函数或简单的数据传递中使用它,但对于需要暴露给 LLM 或进行严格验证的接口,Pydantic 更为常用。
在 LangChain 的语境下,最常见的组合是:
- 使用 Pydantic 模型来定义你的工具期望的输入参数 (
args_schema)。 - 然后将这个 Pydantic 模型、工具的执行函数、名称和描述封装成一个 LangChain 工具对象 (
Tool)。 - Agent 会利用工具对象的元数据和 Pydantic schema 来决定如何调用工具。
3.JSON Schema
同样地,我们也可以传递一个 JSON Schema 字典。这种方式无需导入任何包或定义类,使得每个参数的文档说明非常清晰,但代价是稍微有些啰嗦。
1 | from typing import Optional |
4.Streaming 流式传输
当输出类型为字典(即模式指定为 TypedDict 类或 JSON 模式字典)时,我们可以从结构化模型中流式传输输出。
1 | from typing_extensions import Annotated, TypedDict |
1 | {} |
5.Few-shot prompting 少样本提示方法
对于更复杂的模式,添加少量示例到提示中非常有用。这可以通过几种方式来实现。
1 | from langchain_core.prompts import ChatPromptTemplate |
6.(高级) 指定结构化输出方式
如果使用 JSON 模式,仍然需要在模型提示中指定所需的模式。传递给 with_structured_output 的模式仅用于解析模型输出,而不是像工具调用那样直接传递给模型。
要检查正在使用的模型是否支持 JSON 模式,请查阅API 参考对应模型中的相关条目。
例如:Openai->chat_models.base.ChatOpenAI->
1 | json_llm = llm.bind(response_format={"type": "json_object"}) |
json_object 应该有问题,没有及时更新。
指定json_mode输出:
1 | structured_llm = llm.with_structured_output(None, method="json_mode") |
7.直接提示和解析模型输出
并非所有模型都支持 .with_structured_output() ,因为并非所有模型都具备工具调用或 JSON 模式支持。对于这类模型,需要直接指示模型采用特定格式,并利用输出解析器从原始模型输出中提取结构化响应。
PydanticOutputParser
1 | from typing import List |
结果:
1 | System: Answer the user query. Wrap the output in `json` tags |
使用chain调用
1 | chain = prompt | llm | parser |
深入了解指南如何使用输出解析器将 LLM 响应解析为结构化格式 | 🦜️🔗 LangChain — How to use output parsers to parse an LLM response into structured format | 🦜️🔗 LangChain
8.LCEL (LangChain Expression Language)
Output parsers 实现了 Runnable 接口,它是 LangChain 表达式语言(LCEL)的基本构建模块。这意味着它们支持 invoke 、 ainvoke 、 stream 、 astream 、 batch 、 abatch 、 astream_log 调用。
什么是 LangChain 表达式语言 (LCEL)?
LangChain 表达式语言 (LCEL) 是一种声明式的方式来轻松地组合和编排 LangChain 的组件 (如 LLMs, ChatModels, Prompts, OutputParsers, Retrievers, Tools 等) 形成链 (Chains) 或更复杂的可运行序列 (Runnable sequences)。
可以把它想象成用管道符 | (在 Python 中重载了这个操作符) 将不同的处理步骤连接起来,数据会像流水一样从一个组件流向下一个组件。
LCEL 的核心思想和优势:
- 可组合性 (Composability):
- LCEL 的核心就是将各种组件像乐高积木一样拼接起来。你可以简单地将一个组件的输出作为下一个组件的输入。
- 示例:
prompt | llm | output_parser
- 声明式而非命令式:
- 你描述的是“你想要构建什么样的数据处理流程”,而不是“一步步具体如何执行这些操作”。这使得代码更简洁、更易读。
- 统一的接口 (
Runnable协议):- LCEL 中的所有核心组件都实现了
Runnable协议。这个协议定义了一套标准的方法,如:invoke(): 同步调用,输入一个数据,得到一个输出。ainvoke(): 异步调用。stream(): 同步流式调用,逐步返回结果。astream(): 异步流式调用。batch(): 同步批量调用,处理多个输入。abatch(): 异步批量调用。with_config(): 配置运行时的参数,如回调、标签等。
- 由于所有组件共享这个接口,它们可以无缝地组合在一起。
- LCEL 中的所有核心组件都实现了
- 流式处理 (Streaming) 支持:
- LCEL 原生支持流式处理。如果链中的任何组件支持流式输出(例如 LLM),那么整个组合链也支持流式输出。这对于构建实时交互的应用(如聊天机器人)非常重要。
- 异步 (Async) 支持:
- 与流式处理类似,如果组件支持异步操作,整个链也支持异步操作,方便构建高性能、非阻塞的应用。
- 并行执行 (Parallelism):
- LCEL 允许你并行执行链的某些部分,例如同时向多个 LLM 发出请求或并行运行多个检索器。这通过
RunnableParallel(通常用字典语法糖表示) 实现。
- LCEL 允许你并行执行链的某些部分,例如同时向多个 LLM 发出请求或并行运行多个检索器。这通过
- 回退机制 (Fallbacks):
- 可以轻松定义主组件失败时的备用组件或链。
- 可配置性 (Configurability):
- 可以为链的任何部分配置运行时参数,如回调函数、标签、元数据、重试次数等。
- 可观测性 (Observability) 和调试:
- LCEL 与 LangSmith (LangChain 的可观测性平台) 紧密集成,可以轻松追踪和调试链的执行过程,查看每一步的输入输出。
- Schema 获取:
- 可以自动获取链的输入和输出 schema,方便构建 API 或与其他系统集成。
如何流式处理可运行项
流式传输是确保基于 LLMs 的应用程序对终端用户具有快速响应感的关键。
这个接口提供了两种通用的方法来流式传输内容:
同步和异步:这是链的一个默认流实现,用于流式传输链的最终输出。
async
astream_events和 asyncastream_log:这些用于流式传输链中中间步骤和最终输出。1. 同步 API (Sync API) - 例如
stream()- 执行方式:阻塞式 (Blocking)
- 当你的代码调用一个同步方法(如
llm.stream(...)或chain.stream(...))时,该方法的执行会阻塞当前线程,直到操作完成或产生下一个数据块。 - 在
stream()的上下文中,当你迭代返回的生成器时,每次请求下一个数据块 (token chunk),如果这个数据块还没有从 LLM 服务器返回,你的程序会暂停在那里等待,直到数据到达。
- 当你的代码调用一个同步方法(如
- 并发性:有限或通过多线程/多进程实现
- 在单个线程中,同步代码是按顺序执行的。如果你想同时处理多个独立的 LLM 请求,你需要使用多线程 (threading) 或多进程 (multiprocessing) 来实现并发。
- 多线程在 Python 中由于全局解释器锁 (GIL) 的存在,对于 CPU 密集型任务效果不佳,但对于 I/O 密集型任务(如等待网络响应)仍然可以提供并发性,因为它可以在等待时释放 GIL。
2. 异步 API (Async API) - 例如
astream()- 执行方式:非阻塞式 (Non-Blocking)
- 异步方法(如
llm.astream(...)或chain.astream(...))使用async和await关键字。 - 当你
await一个异步操作时,如果该操作需要等待(例如,等待网络数据),它会将控制权交还给事件循环 (event loop)。事件循环可以在等待期间去执行其他任务。当等待的操作完成并准备好数据时,事件循环会恢复该异步函数的执行。 - 这意味着你的程序在等待 I/O 时不会被阻塞,可以继续处理其他事情(如果事件循环中有其他任务)。
- 异步方法(如
- 并发性:通过 asyncio 和事件循环实现高效并发
asyncio是 Python 的标准库,用于编写单线程并发代码。通过事件循环,可以在单个线程内高效地管理成百上千个并发的 I/O 操作。- 这对于需要同时处理多个 LLM 流式请求或与其他异步服务交互的应用程序非常有用。
- 执行方式:阻塞式 (Blocking)
1.使用流式处理
所有对象都包含一个名为 sync 的同步方法和一个名为 async 的异步版本。
这些方法设计用来以块的形式流式传输最终输出,一旦块可用就会立即生成每个块。只有当程序中的所有步骤都懂得如何处理输入流时,流式传输才可行;也就是说,程序需要一次处理一个输入数据块,并相应地生成输出数据块。
这个处理的复杂程度各不相同,既有像发出 LLM 生成的标记这样简单的任务,也有像在 JSON 完全生成前就流式传输 JSON 部分这样更复杂的任务。
大型语言模型和它们的聊天版本是使用 LLM 的应用程序中的主要瓶颈。
同步 API :
1 | chunks = [] |
异步 API:
1 | chunks = [] |
2.Chains
使用 LangChain Expression Language ( LCEL ) 构建一个简单的链,将提示、模型和解析器结合起来,并验证流式传输是否正常。
使用 StrOutputParser 来解析模型输出的内容。这是一个简单的解析器,它从 AIMessageChunk 中提取 content 字段,从而得到模型返回的 token 。
1 | from langchain_core.output_parsers import StrOutputParser |
某些可运行项(例如提示模板和聊天模型)无法处理单个数据块,而是将所有之前的步骤进行汇总。因此,这类可运行项可能会中断流式处理过程。
3.Working with Input Streams
如果你依赖 json.loads 来解析部分 JSON,解析会失败,因为该部分 JSON 不是一个有效的 JSON。解析器需要在输入流上工作,并尝试将不完整的 JSON 自动补全为有效状态。
1 | from langchain_core.output_parsers import JsonOutputParser |
使用之前的示例,并在末尾添加一个提取函数,用于从最终化的 JSON 中提取国家名称。
1 | from langchain_core.output_parsers import ( |
如何使用聊天模型调用工具
工具调用功能使聊天模型能够通过“调用工具”的方式对给定提示进行回应。工具调用是一种通用技术,能够从模型生成结构化输出,即使你无意调用任何工具也可以使用。例如,它可以用于从非结构化文本中提取信息。
Python functions
1 | # The function name, type hints, and docstring are all part of the tool |
@tool decorator
这个 @tool 装饰器是定义自定义工具最简单的方法。默认情况下,装饰器会使用函数名作为工具名,但也可以通过将字符串作为第一个参数来覆盖。此外,装饰器会使用函数的文档字符串作为工具的描述,因此必须提供文档字符串。
1 | from langchain_core.tools import tool |
Pydantic class
1 | from pydantic import BaseModel, Field |
TypedDict class
1 | from typing_extensions import Annotated, TypedDict |
Tool calls
如果工具调用包含在 LLM 响应中,它们会以工具调用对象的列表形式附加到相应的消息或消息块中的 .tool_calls 属性。
1 | query = "What is 3 * 12? Also, what is 11 + 49?" |
ToolCall 是一个包含工具名称、参数值字典以及(可选)标识符的键值对结构。对于没有工具调用的消息,该属性默认为空列表。
1 | [{'name': 'multiply', |
如何将工具的输出结果传递给聊天模型
定义工具
1 | from langchain_core.tools import tool |
现在,让我们让模型调用一个工具。我们将它添加到对话历史记录中,作为消息列表的一部分。
1 | from langchain_core.messages import HumanMessage |
接下来,让我们用模型填充的参数来调用工具函数!
1 | for tool_call in ai_msg.tool_calls: |
最后,我们将使用工具结果调用模型,模型会利用这些信息生成对我们原始问题的最终答案。
1 | llm_with_tools.invoke(messages) |
在本地运行模型
快速开始
1 | from langchain_ollama import OllamaLLM |
其中base_url为wsl主机地址,ollama配置在wsl2上。
按照生成的顺序流式传输
1 | for chunk in llm.stream("The first man on the moon was ..."): |
Prompts
某些 LLMs 能从特定的提示中获得好处。例如,LLaMA 会使用特殊符号。可以使用 ConditionalPromptSelector 来根据模型类型设定提示信息。
1 |
|
1 | # Chain |
如何将多模态数据传输到模型中
LangChain 支持将多模态数据输入聊天模型,遵循特定提供方的格式要求;遵守跨平台标准
1.图片内联传递
1 | { |
1 | import base64 |
2.从 URL 获取图像
一些提供商(如 OpenAI、Anthropic 和 Google Gemini)也支持直接通过 URL 接收图像。
1 | { |
1 | message = { |
我们还可以传入多张图片:
1 | message = { |
3.文件(PDF 格式)
base64 数据的文档
1 | { |
1 | import base64 |
来自网址的文档
1 | { |
4.音频
1 | { |
5.提供商特有的参数
cathe
Anthropic 允许您指定缓存特定内容,以减少 token 的消耗。
1 | llm = init_chat_model("anthropic:claude-3-5-sonnet-latest") |
如何裁剪消息
所有模型都有固定的上下文窗口,即它们能接受的输入令牌数量是有限的。如果你处理非常长的消息,或者链/代理积累了很长的消息历史,就需要管理传递给模型的消息长度。
trim_messages 可以用来将聊天记录缩减至指定的 token 数量或消息数量。确保对话不会超限
1 | # 掌握Langchain中的消息修剪:确保您的对话不会超限 |
如何筛选消息
在更复杂的链和代理中,我们可能会用消息列表来跟踪状态。这个列表可能会从多个不同的模型、说话者、子链等来源积累消息,而我们可能只想在每个链/代理的模型调用中传递这个完整消息列表的子集。
1.基础使用方法
1 | from langchain_core.messages import ( |
1 | [HumanMessage(content='example input', name='example_user', id='2'), |
1 | [SystemMessage(content='you are a good assistant', id='1'), |
1 | [HumanMessage(content='example input', name='example_user', id='2'), |
2.Chaining
1 |
|
通过查看 LangSmith 的跟踪记录,我们可以发现,在消息传递到模型之前,它们会被过滤:
注意, LangSmith中,tracing project 中,Raw input 为原始输入,而不是最终llm接受的原始输入,查看Trace 跟踪输入输出
1 | AIMessage(content=[], response_metadata={'id': 'msg_01Wz7gBHahAwkZ1KCBNtXmwA', 'model': 'claude-3-sonnet-20240229', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'input_tokens': 16, 'output_tokens': 3}}, id='run-b5d8a3fe-004f-4502-a071-a6c025031827-0', usage_metadata={'input_tokens': 16, 'output_tokens': 3, 'total_tokens': 19}) |
如何创建自定义的 LLM 类
通过标准 LLM 接口封装你的 LLM,可以在现有的 LangChain 程序中轻松使用 LLM,而无需进行大量代码修改。
Implementation
| Method 方法 | Description 说明 |
|---|---|
_call |
Takes in a string and some optional stop words, and returns a string. Used by invoke. 接收一个字符串以及可选的停用词,并返回一个字符串。该功能被 invoke 使用。 |
_llm_type |
A property that returns a string, used for logging purposes only. 一个仅用于日志记录的返回字符串的属性。 |
| Method 方法 | Description 说明 |
|---|---|
_identifying_params |
Used to help with identifying the model and printing the LLM; should return a dictionary. This is a @property. 用于辅助识别模型和打印 LLM;应返回一个字典。这是一个属性。 |
_acall |
Provides an async native implementation of _call, used by ainvoke. 提供了 _call 的异步本地实现,并被 ainvoke 采用。 |
_stream |
Method to stream the output token by token. 按照逐词流式输出结果的方法。 |
_astream |
Provides an async native implementation of _stream; in newer LangChain versions, defaults to _stream. 提供了 _stream 的异步原生实现;在较新的 LangChain 版本中,默认使用 _stream 。 |
实现一个简单的自定义 LLM,只返回输入的前 n 个字符。
1 | from typing import Any, Dict, Iterator, List, Mapping, Optional |
1 | llm = CustomLLM(n=5) |
如何构建知识图谱
从文本构建知识图谱的高级步骤包括:
- 从文本中提取结构化信息:模型用于提取文本中的结构化图数据。
- 将提取的结构化图信息存入图数据库,可支持下游 RAG 应用
安装必要的软件包并设置环境变量。
1 | %pip install --upgrade --quiet langchain langchain-neo4j langchain-openai langchain-experimental neo4j |
配置 Neo4j 的认证信息和连接。
1 | import os |
LLM 知识图谱转换器
从文本中提取图数据能够将非结构化信息转换为结构化格式,从而帮助人们更深入地理解复杂关系和模式,并更高效地导航。 LLMGraphTransformer 通过利用 LLM 解析和分类实体及其关系,将文本文档转换为结构化的图文档。所选 LLM 模型对输出结果有显著影响,因为它决定了提取的图数据的准确性和细微差别。
1 | import os |
输入示例文本来查看结果
1 | from langchain_core.documents import Document |
MCP 集成
模型上下文协议(MCP)是一个开放协议,旨在统一应用程序向语言模型提供工具和上下文的方式。LangGraph 代理能够借助 langchain-mcp-adapters 库,使用 MCP 服务器上定义的工具。
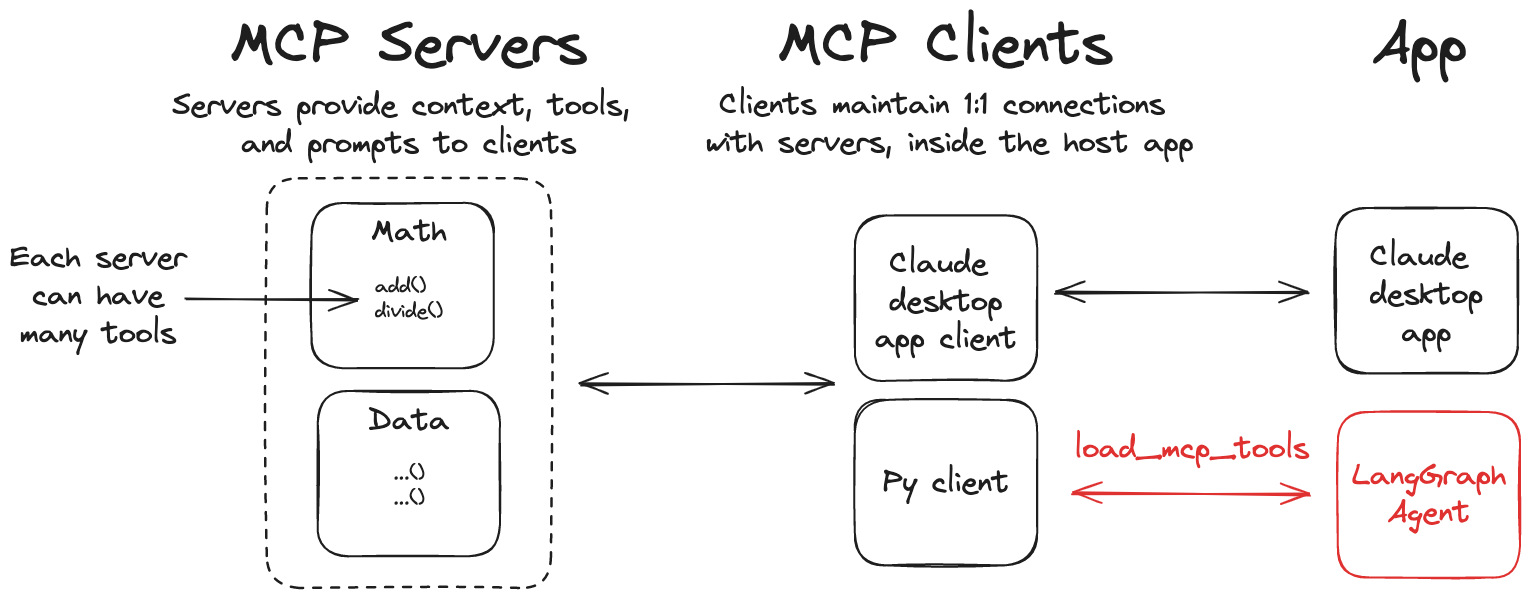
安装 langchain-mcp-adapters 库,以便在 LangGraph 中使用 MCP 工具
1 | pip install langchain-mcp-adapters |
Use MCP tools
1 | from langchain_mcp_adapters.client import MultiServerMCPClient |
自定义 MCP 服务器
1 | pip install mcp |
示例数学服务器(标准输入输出传输)
1 | from mcp.server.fastmcp import FastMCP |
构建一个检索增强生成(RAG)应用程序
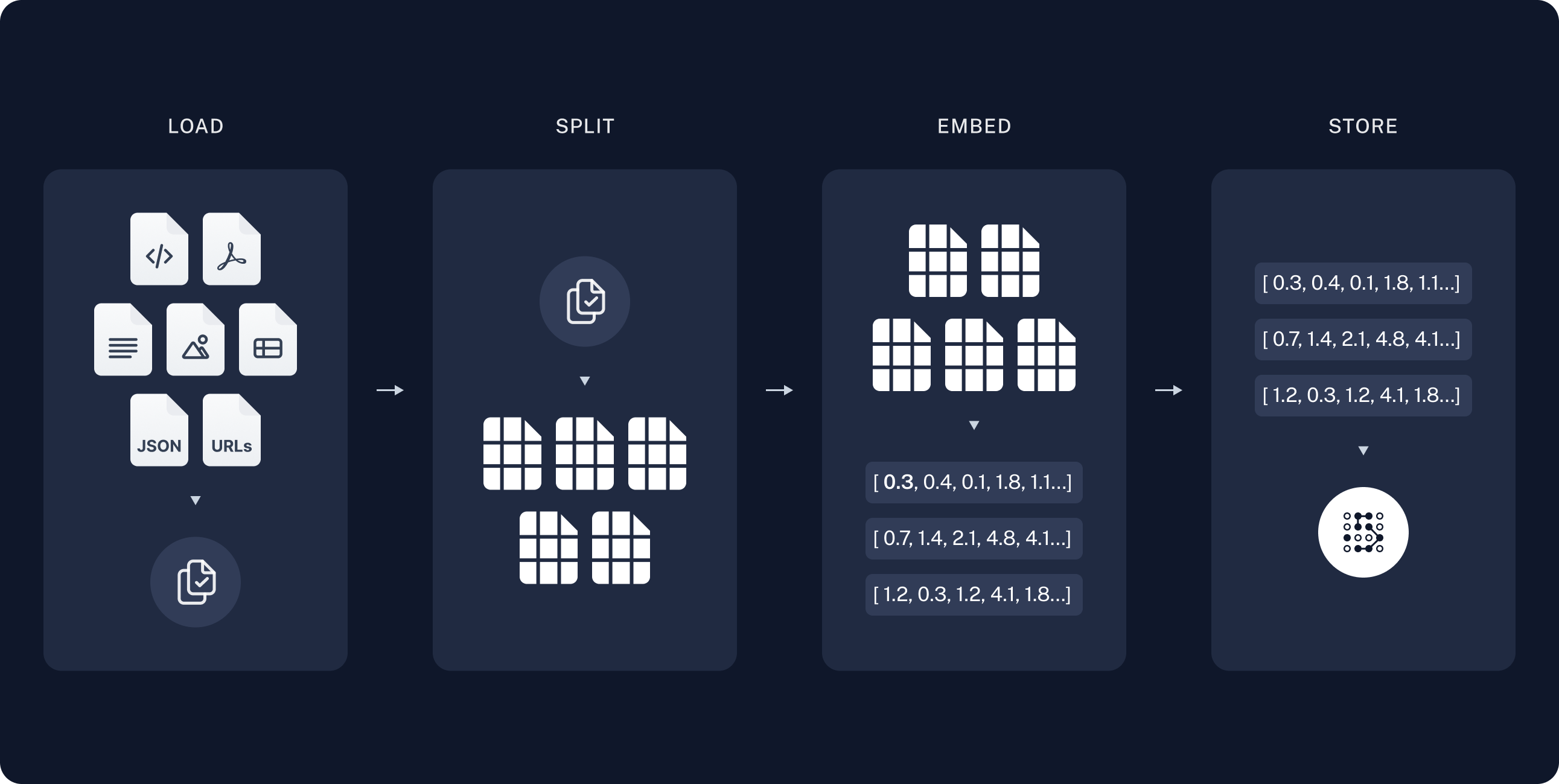
Indexing
加载数据。这是通过文档加载器来完成的。
文本分割器用于将大文本 Documents 切割成更小的片段。这对于索引数据和向模型传递内容非常有用,因为大块文本难以搜索,且无法完全容纳在模型的有限上下文窗口内。
存储和索引我们的数据片段,以便日后可以方便地搜索。这通常通过使用向量存储和嵌入模型来实现。
Retrieval and generation
根据用户输入,使用检索器从存储中检索相关的分割内容。
生成:聊天模型/LLM 通过包含问题和检索数据的提示来生成答案
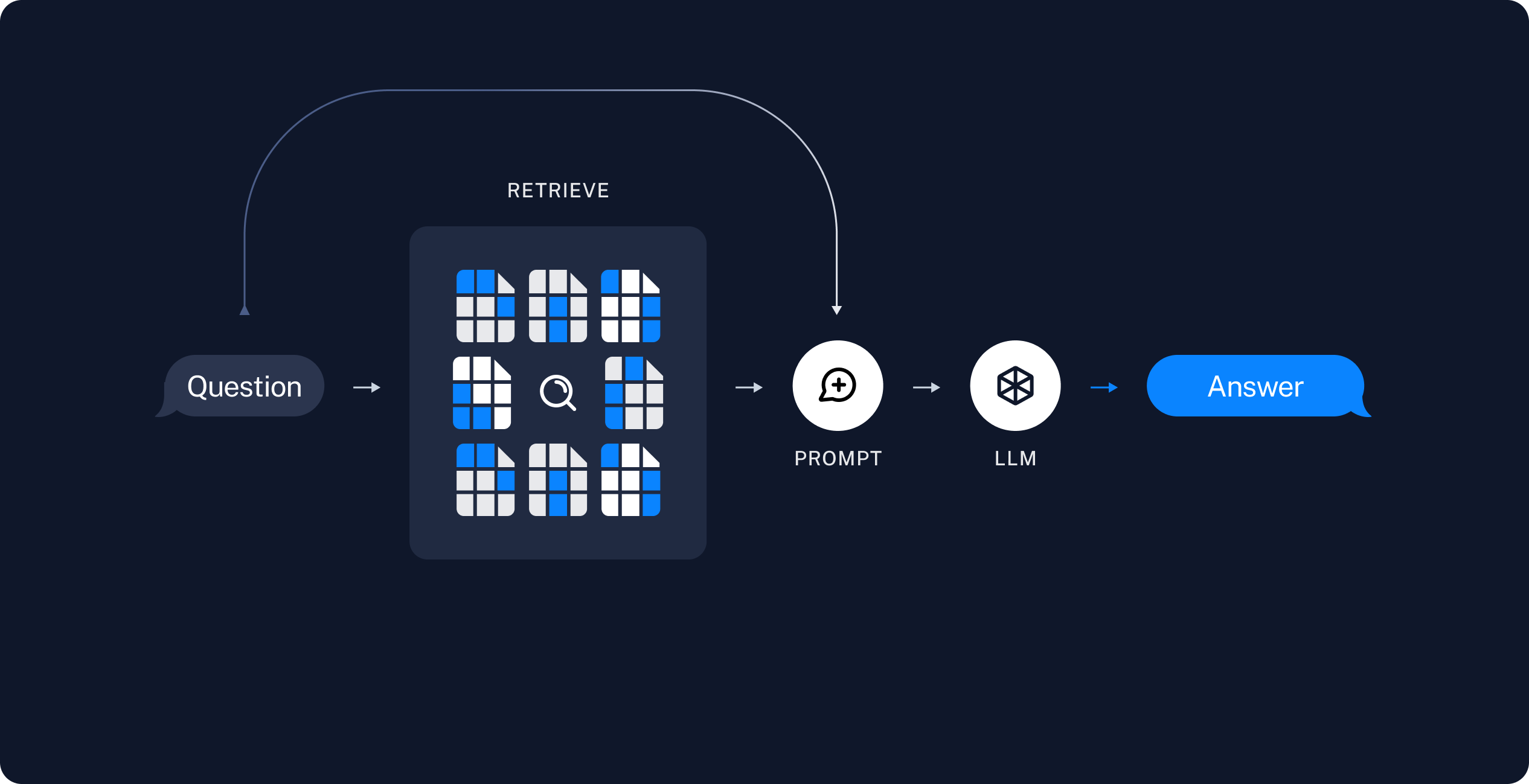
索引数据后,采用 LangGraph 作为编排框架,执行检索和生成操作。
Setup
langchain 依赖项
1 | %pip install --quiet --upgrade langchain-text-splitters langchain-community langgraph |
选择嵌入模型
1 | pip install -qU langchain-ollama |
1 | #ollama |
选择合适的向量存储
1 | pip install -qU langchain-core |
1 | from langchain_core.vectorstores import InMemoryVectorStore |
Preview
构建一个应用程序,用于回答有关该网站内容的问题。我们将使用的特定网站是 Lilian Weng 的《LLM 驱动的自主代理》博客文章,该文章允许我们针对文章内容进行提问。
1 | import bs4 |
Agent architectures
有时希望 LLM 系统能够自行选择控制流程,以解决更复杂的问题!这就是一个代理的定义:一个使用 LLM 来决定应用程序控制流程的系统。LLM 控制应用程序的方式有很多:
- 一个 LLM 可以在两条可能的路径之间进行切换
- 一个 LLM 能够决定在众多工具中选择调用哪一个
- 一个 LLM 可以判断生成的答案是否足够,或者是否需要进一步处理
存在多种不同的代理架构,这些架构为 LLM 提供了不同程度的控制能力。
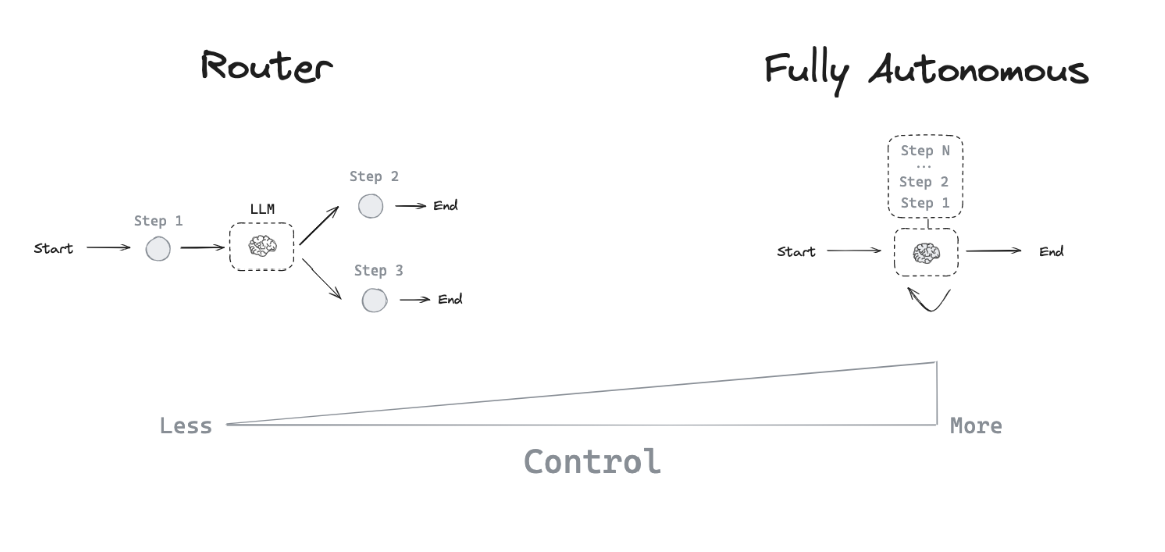
Router
路由器能够让 LLM 从一系列指定选项中挑选一个步骤。这是一种代理架构,其控制能力相对有限,因为 LLM 通常只专注于做出单一决策,并从有限的预定义选项中生成特定输出。路由器通常会运用几种不同的方法来实现这一功能。
Tool-calling agent
路由器虽然能让 LLM 做出单一决策,但更复杂的代理架构通过两种关键方式扩展了 LLM 的控制范围。
- LLM 能够进行多步决策,依次做出一系列选择,而不仅仅是一个决策。
- LLM 可以选择并使用多种工具来完成任务。
ReAct 是一种流行的通用智能体架构,它整合了多种扩展,并融合了三大核心概念。
- 工具调用:允许 LLM 按需选择和使用各种工具。
- 记忆功能:让代理能够记住并利用之前步骤的信息。
- 规划:赋予 LLM 制定和执行多步计划以达成目标的能力
这种架构支持更复杂、更灵活的代理行为,不再局限于简单路由,而是能够进行多步骤的动态问题解决。与原始论文相比,如今的代理借助 LLMs 的工具调用功能,在消息列表上运作
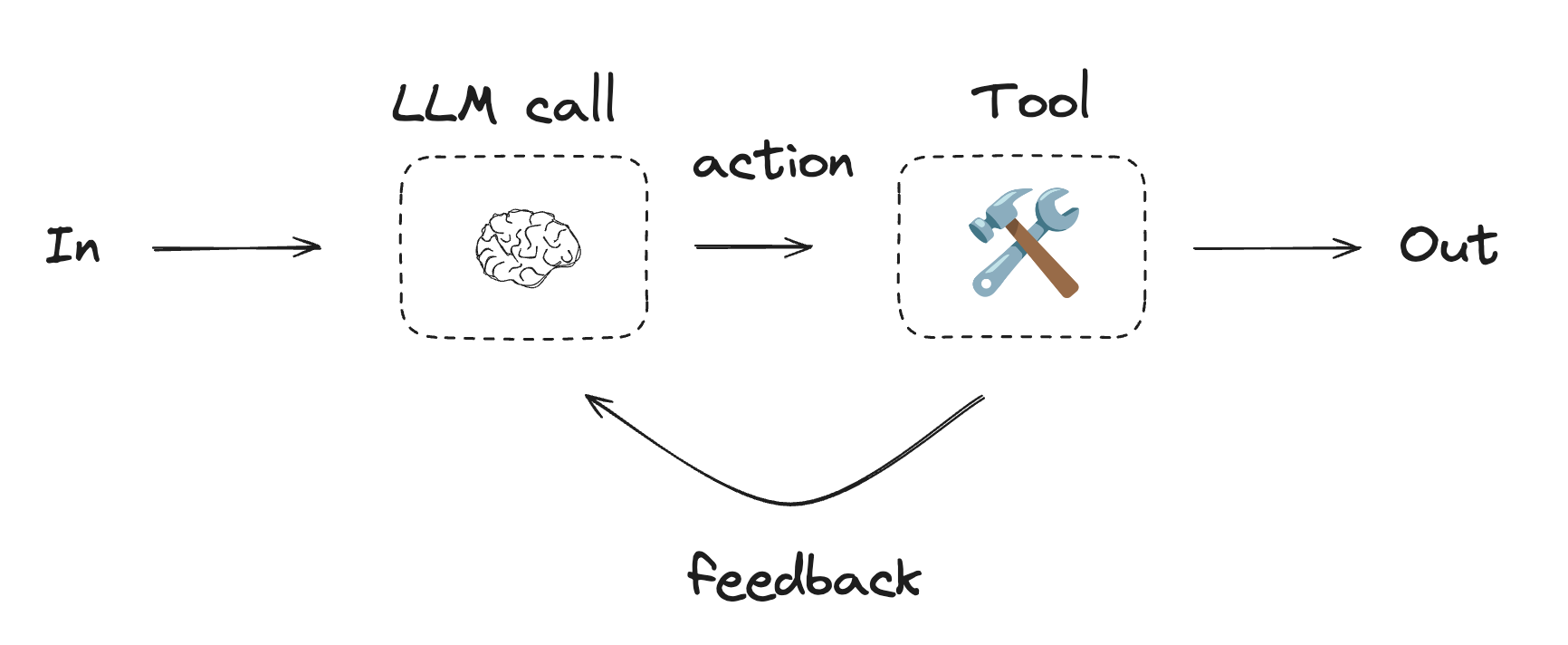
1.Tool calling
工具在代理需要与外部系统交互时非常有用。外部系统(如 API)通常要求特定的输入模式或数据负载,而不是自然语言。例如,当我们把一个 API 绑定成工具时,模型就能了解所需的输入模式。模型会根据用户的自然语言输入来决定是否调用该工具,并返回符合该工具输入模式的数据。
2.Memory
记忆对智能体来说至关重要,它能让智能体在解决复杂问题的多个步骤中记住并利用信息。这种记忆功能在不同的层面上运作:
3.Planning
在工具调用代理中,LLM 会反复在一个 while-循环中被调用。每一步,代理都会决定要调用哪些工具以及这些工具的输入。执行完这些工具后,其输出会被作为观察结果反馈给 LLM。当代理判断已获得足够信息以解决用户请求,且继续调用更多工具不再必要时,while-循环便会终止。
到这个网站查看支持列表,查看模型是否支持llm.bind_tools,https://python.langchain.com/docs/integrations/chat/
示例:
1 | from langchain_core.tools import tool |
1 | from langgraph.graph import MessagesState |
好的,这段代码构建了一个使用 LangGraph 和 Ollama (通过 llama3.2 模型) 的代理(Agent),这个代理能够根据用户的指令调用预定义的工具(加法、乘法、除法)来完成任务。
下面是代码的逐步解释:
环境设置 (LangSmith Tracing):
os.environ["LANGSMITH_TRACING"] = "true": 开启 LangSmith 追踪功能。LangSmith 是一个用于调试、监控和评估 LLM 应用的平台。os.environ["LANGSMITH_ENDPOINT"]: 设置 LangSmith API 的端点。os.environ["LANGSMITH_PROJECT"]: 将运行记录关联到 LangSmith 上的特定项目。os.environ["LANGSMITH_API_KEY"]: 提供 LangSmith 的 API 密钥,用于认证。- 作用: 这些设置允许你将代理的运行过程(包括 LLM 调用、工具使用等)记录到 LangSmith,方便后续分析和调试。
LLM 初始化:
from langchain_ollama import ChatOllama, OllamaLLM: 导入与 Ollama 交互的类。llm = ChatOllama(...): 创建一个ChatOllama实例。model="llama3.2": 指定使用的 Ollama 模型。temperature=0: 设置温度为0,使得模型输出更具确定性,减少随机性。base_url ="http://172.26.20.47:11434": 指定 Ollama 服务的地址和端口。
llm2 = OllamaLLM(...): 创建了另一个OllamaLLM实例,但这个实例在后续的代理逻辑中并未使用。- 作用:
llm对象是代理的核心,负责理解用户输入、决定是否调用工具以及生成最终答复。
工具定义:
from langchain_core.tools import tool: 导入tool装饰器。@tool: 这个装饰器将一个普通的 Python 函数转换为 LangChain 工具。LangChain 工具包含函数本身、函数的描述(来自 docstring)以及参数描述。multiply(a: int, b: int) -> int: 定义乘法工具。docstring 描述了它的功能和参数,这对于 LLM 理解如何使用该工具至关重要。add(a: int, b: int) -> int: 定义加法工具。divide(a: int, b: int) -> float: 定义除法工具。- 作用: 这些工具为 LLM 提供了执行具体计算任务的能力。LLM 本身不擅长精确计算,通过工具调用可以将计算任务外包给这些函数。
将工具绑定到 LLM:
tools = [add, multiply, divide]: 创建一个包含所有定义好的工具的列表。tools_by_name = {tool.name: tool for tool in tools}: 创建一个字典,方便通过工具名称查找工具对象。当 LLM 决定调用某个工具时,它会通过名称指定。llm_with_tools = llm.bind_tools(tools): 这是关键一步。它将tools列表中的工具“绑定”到llm。这意味着llm现在知道了这些工具的存在、它们的功能以及如何调用它们(需要哪些参数)。当llm_with_tools被调用时,如果它认为需要使用工具,它的输出会包含一个特殊的“工具调用”指令。- 作用: 使 LLM 能够在其决策过程中考虑并请求执行这些外部工具。
状态定义 (State):
from langgraph.graph import MessagesState: 导入MessagesState,这是一个预定义的 LangGraph 状态类型,专门用于管理消息列表。MessagesState(通常是一个TypedDict) 内部会有一个键,比如messages,其值是一个消息列表(HumanMessage,AIMessage,ToolMessage等)。- 作用:
MessagesState定义了在图(Graph)中流动的数据结构。图中的每个节点都会接收当前状态,并可以修改状态,然后将更新后的状态传递给下一个节点。
节点定义 (Nodes):
- 节点是图中的基本执行单元。每个节点都是一个 Python 函数,接收当前状态作为输入,并返回一个字典来更新状态。
llm_call(state: MessagesState):- 这个节点负责调用 LLM。
- 它接收当前的
state(包含到目前为止的所有消息)。 - 它构造一个新的输入给
llm_with_tools,这个输入通常包含一条系统消息(SystemMessage,用于设定 LLM 的角色和任务)和state["messages"]中的现有消息。 llm_with_tools.invoke(...)的结果是一个AIMessage。这个AIMessage可能包含:- 直接的文本回复。
- 一个或多个工具调用请求(
tool_calls属性)。
- 该函数返回一个字典
{"messages": [new_ai_message]},用于将 LLM 的新消息追加到状态的messages列表中。
tool_node(state: dict):- 这个节点负责执行工具。
- 它检查
state["messages"]中的最后一条消息(通常是llm_call节点产生的AIMessage)。 - 如果这条消息包含
tool_calls,它会遍历这些调用请求:- 根据
tool_call["name"]从tools_by_name字典中找到对应的工具函数。 - 使用
tool_call["args"]调用该工具函数。 - 将工具的执行结果包装成
ToolMessage。
- 根据
- 它返回一个字典
{"messages": [tool_message_1, tool_message_2, ...]},将所有工具执行结果追加到状态的messages列表中。 print("messages",result): 打印工具执行的结果,方便调试。
条件边逻辑 (Conditional Edge):
should_continue(state: MessagesState) -> Literal["environment", END]:- 这是一个条件函数,用于决定图的下一个走向。
- 它检查
state["messages"]中的最后一条消息。 print("last_message",last_message): 打印最后一条消息,方便调试。- 如果最后一条消息包含
tool_calls(即 LLM 请求调用工具),则返回字符串"Action"(在图中映射到environment节点)。 - 否则 (LLM 没有请求工具,而是直接给出了回复),返回
END(LangGraph 中的特殊常量,表示图执行结束)。
- 作用: 实现控制流。根据 LLM 的输出,决定是去执行工具还是结束流程。
构建工作流 (Workflow/Graph):
agent_builder = StateGraph(MessagesState): 初始化一个状态图,并指定它操作的状态类型是MessagesState。agent_builder.add_node("llm_call", llm_call): 将llm_call函数添加为名为 “llm_call” 的节点。agent_builder.add_node("environment", tool_node): 将tool_node函数添加为名为 “environment” 的节点 (通常用于表示工具执行的环境)。agent_builder.add_edge(START, "llm_call"): 设置图的入口点。START是 LangGraph 的特殊常量,表示图从 “llm_call” 节点开始执行。agent_builder.add_conditional_edges(...): 添加条件边。source="llm_call": 这条边从 “llm_call” 节点出发。path=should_continue: “llm_call” 节点执行完毕后,会调用should_continue函数来决定下一跳。path_map={"Action": "environment", END: END}:- 如果
should_continue返回 “Action”,则流程跳转到 “environment” 节点。 - 如果
should_continue返回END,则流程结束。
- 如果
agent_builder.add_edge("environment", "llm_call"): 添加一条从 “environment” 节点到 “llm_call” 节点的边。这意味着工具执行完毕后,流程会回到 “llm_call” 节点,让 LLM 处理工具的执行结果。- 作用: 定义了代理内部的执行逻辑和流程。
编译代理:
agent = agent_builder.compile(): 将定义好的图结构编译成一个可执行的代理对象。- 作用: 生成最终的、可以被调用的代理程序。
显示代理图 (可选,用于可视化):
display(Image(agent.get_graph(xray=True).draw_mermaid_png())):agent.get_graph(xray=True): 获取图的可视化表示(Mermaid 格式)。xray=True可以提供更详细的节点信息。.draw_mermaid_png(): 将 Mermaid 文本渲染成 PNG 图片。display(Image(...)): 在 Jupyter Notebook 或类似环境中显示图片。
- 作用: 帮助开发者理解代理的结构和流程。
调用代理并处理输出:
messages = [HumanMessage(content="Add 3 and 4.")]: 创建初始的用户输入,包装成HumanMessage。result_state = agent.invoke({"messages": messages}): 调用编译好的代理。- 输入是一个字典,键与
MessagesState中定义的键对应(这里是 “messages”)。 - 代理会按照定义的图逻辑执行。对于 “Add 3 and 4.” 这个输入:
START->llm_call:llm_with_tools接收到 “Add 3 and 4.”。它识别出需要调用add工具,并输出一个包含tool_calls的AIMessage,请求调用add工具,参数为a=3, b=4。llm_call->should_continue:should_continue检测到tool_calls,返回 “Action”。should_continue->environment:tool_node执行add(3, 4),得到结果7。它将结果包装成ToolMessage(content=7, ...)。environment->llm_call:llm_with_tools再次被调用,这次的输入消息列表包含了原始的用户输入、第一次的 AI 工具调用请求以及工具执行结果ToolMessage(content=7, ...)。LLM 现在看到了工具的结果,于是生成最终的答复,例如 “3加4等于7。”。这个新的AIMessage不会包含tool_calls。llm_call->should_continue:should_continue检测到最后一条AIMessage没有tool_calls,返回END。should_continue->END: 图执行结束。
agent.invoke()返回的是最终的状态result_state,其中result_state["messages"]包含了整个对话过程的所有消息。
- 输入是一个字典,键与
for m in result_state["messages"]: m.pretty_print(): 遍历最终状态中的所有消息,并用pretty_print()方法美化输出,清晰地展示整个交互流程。