Milvus
快速入门 Milvus Lite
向量是神经网络模型的输出数据格式,可以有效地对信息进行编码,在知识库、语义搜索、检索增强生成(RAG)等人工智能应用中发挥着举足轻重的作用。
安装 Milvus
开始之前,请确保本地环境中有 Python 3.8+ 可用。安装pymilvus ,其中包含 python 客户端库和 Milvus Lite:
1 | $ pip install -U pymilvus |
设置向量数据库
要创建本地的 Milvus 向量数据库,只需实例化一个MilvusClient ,指定一个存储所有数据的文件名,如 “milvus_demo.db”。
1 | from pymilvus import MilvusClient |
创建 Collections
在 Milvus 中,我们需要一个 Collections 来存储向量及其相关元数据。**你可以把它想象成传统 SQL 数据库中的表格。**创建 Collections 时,可以定义 Schema 和索引参数来配置向量规格,如维度、索引类型和远距离度量。此外,还有一些复杂的概念来优化索引以提高向量搜索性能。现在,我们只关注基础知识,并尽可能使用默认设置。至少,你只需要设置 Collections 的名称和向量场的维度。
1 | if client.has_collection(collection_name="demo_collection"): |
在上述设置中
- 主键和向量字段使用默认名称(”id “和 “vector”)。
- 度量类型(向量距离定义)设置为默认值(COSINE)。
- 主键字段接受整数,且不自动递增(即不使用自动 ID 功能)。 或者,您也可以按照此说明正式定义 Collections 的 Schema。
准备数据
在本指南中,我们使用向量对文本进行语义搜索。我们需要通过下载 embedding 模型为文本生成向量。使用pymilvus[model] 库中的实用功能可以轻松完成这项工作。
用向量表示文本
首先,安装模型库。该软件包包含 PyTorch 等基本 ML 工具。如果您的本地环境从未安装过 PyTorch,下载软件包可能需要一些时间。
1 | $ pip install "pymilvus[model]" |
用默认模型生成向量 Embeddings。Milvus 希望数据以字典列表的形式插入,每个字典代表一条数据记录,称为实体。
1 | from pymilvus import model |
插入数据
让我们把数据插入 Collections:
1 | res = client.insert(collection_name="demo_collection", data=data) |
语义搜索
现在我们可以通过将搜索查询文本表示为向量来进行语义搜索,并在 Milvus 上进行向量相似性搜索。
向量搜索
Milvus 可同时接受一个或多个向量搜索请求。query_vectors 变量的值是一个向量列表,其中每个向量都是一个浮点数数组。
1 | query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?"]) |
输出结果是一个结果列表,每个结果映射到一个向量搜索查询。每个查询都包含一个结果列表,其中每个结果都包含实体主键、到查询向量的距离以及指定output_fields 的实体详细信息。
带元数据过滤的向量搜索
你还可以在考虑元数据值(在 Milvus 中称为 “标量 “字段,因为标量指的是非向量数据)的同时进行向量搜索。这可以通过指定特定条件的过滤表达式来实现。让我们在下面的示例中看看如何使用subject 字段进行搜索和筛选。
1 | # Insert more docs in another subject. |
默认情况下,标量字段不编制索引。如果需要在大型数据集中执行元数据过滤搜索,可以考虑使用固定 Schema,同时打开索引以提高搜索性能。
在 Milvus 的上下文中,Schema 定义了:
字段(Fields):你的数据包含哪些属性。例如,在上面提供的例子中,
id、vector、text和subject都是字段。数据类型(Data Types)
:每个字段存储什么类型的数据。例如:
id通常是整数(int64)。vector是向量(float_vector)。text是字符串(varchar)。subject也是字符串(varchar)。
主键(Primary Key):用于唯一标识每一条记录的字段(通常是
id)。是否是向量字段(Is Vector Field):标记哪个字段是用于向量搜索的。
是否开启索引(Enable Indexing):对于标量字段(非向量字段),你可以选择是否为它们创建索引。创建索引可以显著提高过滤查询(例如
subject == 'biology')的性能,尤其是在数据量很大时。
除了向量搜索,还可以执行其他类型的搜索:
查询
query()是一种操作符,用于检索与某个条件(如过滤表达式或与某些 id 匹配)相匹配的所有实体。
例如,检索标量字段具有特定值的所有实体:
1 | res = client.query( |
通过主键直接检索实体
1 | res = client.query( |
删除实体
如果想清除数据,可以删除指定主键的实体,或删除与特定过滤表达式匹配的所有实体。
1 | # Delete entities by primary key |
加载现有数据
由于 Milvus Lite 的所有数据都存储在本地文件中,因此即使在程序终止后,你也可以通过创建一个带有现有文件的MilvusClient ,将所有数据加载到内存中。例如,这将恢复 “milvus_demo.db “文件中的 Collections,并继续向其中写入数据。
1 | from pymilvus import MilvusClient |
删除 Collections
如果想删除 Collections 中的所有数据,可以通过以下方法删除 Collections
1 | # Drop collection |
搜索数据模型设计
信息检索系统(又称搜索引擎)是各种人工智能应用(如检索增强生成(RAG)、可视化搜索和产品推荐)的关键。这些系统的核心是精心设计的数据模型,用于组织、索引和检索信息。
Milvus 允许您通过 Collect schema 指定搜索数据模型,组织非结构化数据、它们的密集或稀疏向量表示以及结构化元数据。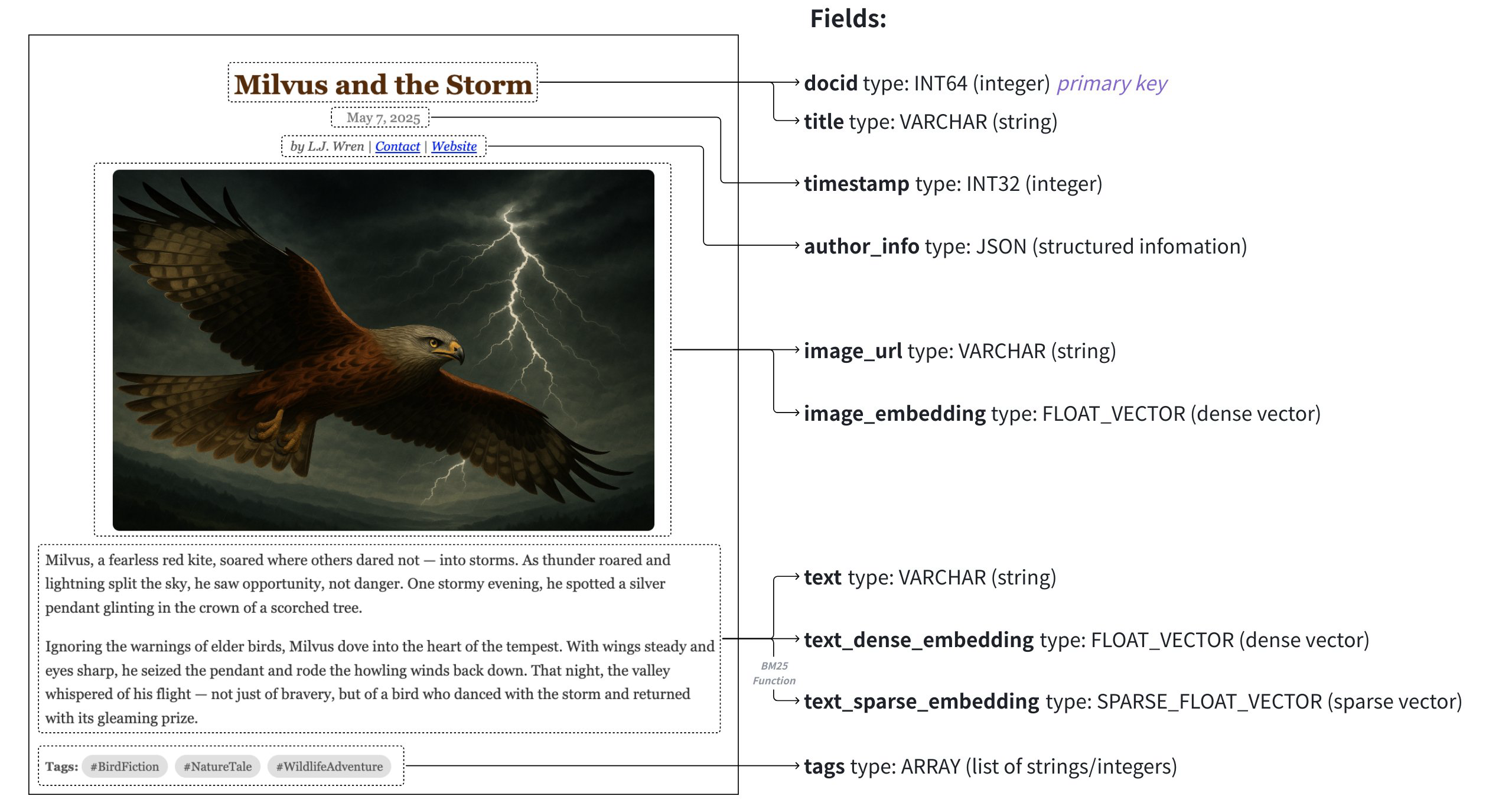
数据模型
搜索系统的数据模型设计包括分析业务需求,并将信息抽象为模式表达的数据模型。定义明确的 Schema 对于使数据模型与业务目标保持一致、确保数据一致性和服务质量非常重要。
分析业务需求
要有效满足业务需求,首先要分析用户将执行的查询类型,并确定最合适的搜索方法。
- **用户查询:**确定用户预期执行的查询类型。这有助于确保您的 Schema 支持真实世界的用例并优化搜索性能。这些查询可能包括
- 检索与自然语言查询相匹配的文档
- 查找与参考图片相似或匹配文本描述的图片
- 根据名称、类别或品牌等属性搜索产品
- 根据结构化元数据(如出版日期、标签、评级)过滤项目
- 在混合查询中结合多种标准(例如,在视觉搜索中,同时考虑图像及其说明的语义相似性)
- **搜索方法:**根据用户将执行的查询类型选择适当的搜索技术。不同的方法服务于不同的目的,通常可以结合使用以获得更强大的结果:
- 语义搜索:使用密集向量相似性来查找具有相似含义的项目,非常适合文本或图像等非结构化数据。
- 全文搜索:用关键字匹配补充语义搜索。 全文搜索可利用词法分析,避免将长词分解成零散的标记,在检索过程中抓住特殊术语。
- 元数据过滤:在向量搜索的基础上,应用日期范围、类别或标签等约束条件。
将业务需求转化为搜索数据模型
下一步是将业务需求转化为具体的数据模型,方法是确定信息的核心组件及其搜索方法:
- 定义需要存储的数据,如原始内容(文本、图像、音频)、相关元数据(标题、标签、作者)和上下文属性(时间戳、用户行为等)。
- 为每个元素确定适当的数据类型和格式。例如
- 文本描述 → 字符串
- 图像或文档 Embeddings → 密集或稀疏向量
- 类别、标签或标志 → 字符串、数组和 bool
- 价格或评级等数字属性 → 整数或浮点数
- 结构化信息,如作者详细信息 -> json
明确定义这些元素可确保数据的一致性、搜索结果的准确性以及与下游应用逻辑集成的便捷性。
Schema 设计
在 Milvus 中,数据模型通过 Collections Schema 表达。在 Collections 模式中设计正确的字段是实现有效检索的关键。每个字段都定义了存储在 Collections 中的特定数据类型,并在搜索过程中扮演着不同的角色。在高层次上,Milvus 支持两种主要类型的字段:向量字段和标量字段。
现在,您可以将数据模型映射到字段 Schema 中,包括向量和任何辅助标量字段。确保每个字段都与数据模型中的属性相关联,尤其要注意向量类型(密集型或标量型)及其维度。
向量字段
向量字段存储文本、图像和音频等非结构化数据类型的嵌入。这些嵌入可能是密集型、稀疏型或二进制型,具体取决于数据类型和使用的检索方法。通常,密集向量用于语义搜索,而稀疏向量则更适合全文或词性匹配。当存储和计算资源有限时,二进制向量很有用。一个 Collections 可能包含多个向量场,以实现多模式或混合检索策略。有关该主题的详细指南,请参阅多向量混合检索。
密集型、稀疏型和二进制向量的例子及其使用场景。
1. 密集型向量 (Dense Vectors)
定义:
密集型向量是大多数元素都非零的向量。它们通常由深度学习模型(如神经网络)生成,用于捕捉数据的语义信息。向量中的每个维度都代表了原始数据在某个抽象特征空间中的一个连续值。
例子:
假设我们有一个句子 “The cat sat on the mat.” 经过预训练的语言模型(如 BERT, Word2Vec, Sentence-BERT)编码后,可能会生成一个固定长度的浮点数向量,例如:[0.123, -0.456, 0.789, 0.010, ..., 0.999] (假设是一个 768 维的向量)
这个向量的每个值都是一个浮点数,且通常大部分值都不是零。
使用场景:
- 语义搜索 (Semantic Search): 这是最常见的应用。当你想根据内容的“含义”而不是精确的关键词来查找信息时,密集向量非常有用。
- 文本: 搜索与查询语义相似的文档,即使它们没有共享相同的关键词。
- 图像: 搜索与查询图像在视觉上相似的图像(例如,用一张猫的图片搜索其他猫的图片)。
- 音频: 搜索与查询音频在声音特征上相似的音频片段。
- 推荐系统: 根据用户过去喜欢的内容的嵌入向量,推荐语义相似的新内容。
- 聚类与分类: 将语义相似的数据点在向量空间中聚集在一起,或进行分类。
- 多模态搜索: 将不同模态(如文本、图像)的数据映射到同一个向量空间,实现跨模态搜索。
2. 稀疏型向量 (Sparse Vectors)
定义:
稀疏型向量是大多数元素都为零的向量。它们通常用于表示离散的特征,例如词袋模型 (Bag-of-Words) 或 TF-IDF 特征。稀疏向量通常以 (索引, 值) 对的形式存储,只存储非零元素,以节省空间。
例子:
仍然是句子 “The cat sat on the mat.”
词袋模型 (Bag-of-Words, BoW):
假设我们的词汇表是{"the": 0, "cat": 1, "sat": 2, "on": 3, "mat": 4}。
句子 “The cat sat on the mat.” 的 BoW 向量可能是:[2, 1, 1, 1, 1, 0, 0, 0, ...](假设词汇表很大,大部分词都没有出现)
这里,the出现了 2 次,其他词出现 1 次。大部分位置都是 0。TF-IDF (Term Frequency-Inverse Document Frequency):
TF-IDF 比 BoW 更复杂,它会给词语赋予权重,表示其在文档中的重要性。
句子 “The cat sat on the mat.” 的 TF-IDF 向量可能看起来像:[0.1, 0.8, 0.7, 0.9, 0.6, 0.0, 0.0, ...]
这里虽然是非零值,但如果词汇表非常大,绝大多数词在特定文档中是不会出现的,所以大部分维度仍然是零。
使用场景:
- 全文搜索 (Full-Text Search): 当你想要基于精确的关键词匹配或词频来搜索文档时,稀疏向量非常有效。
- 倒排索引 (Inverted Index): 稀疏向量可以很好地与倒排索引结合,快速查找包含特定关键词的文档。
- BM25 排名: 传统的搜索引擎排名算法,如 BM25,就是基于稀疏向量(通常是词频)进行计算的。
- 词性匹配 (Lexical Matching): 查找包含特定单词或短语的文档。
- 混合检索 (Hybrid Search): 将稀疏向量与密集向量结合,以同时利用关键词匹配的精确性和语义匹配的召回率。例如,RAG (Retrieval Augmented Generation) 系统中,通常会同时使用稀疏和密集检索来获取更相关的上下文。
3. 二进制向量 (Binary Vectors)
定义:
二进制向量是一种特殊的稀疏向量,其元素只有两个可能的值:0 或 1。它们通常用于表示二元特征(例如,某个属性是否存在)或通过哈希函数将高维数据压缩为二进制码。
例子:
特征存在性:
假设我们有一些商品的特征:{"防水": 0, "智能": 1, "轻薄": 2, "防震": 3}。
一个商品如果只有 “防水” 和 “轻薄” 特性,它的二进制向量可能是:[1, 0, 1, 0]局部敏感哈希 (Locality Sensitive Hashing, LSH):
通过 LSH 算法,可以将一个高维的浮点向量映射成一个短的二进制向量。例如,一个 768 维的密集向量经过 LSH 转换后,可能变成一个 64 位的二进制向量:[0, 1, 1, 0, 1, 0, 0, 1, ..., 1]
使用场景:
- 高效相似度搜索: 当存储和计算资源有限时,二进制向量非常有用。它们可以使用位运算(如汉明距离)进行快速的相似度计算。
- 图像检索: 在大规模图像数据集中进行快速近似相似度搜索。
- 指纹识别: 生物识别系统中,指纹特征可以编码为二进制向量进行匹配。
- 特征表示: 表示事物的二元属性。
- 近似近邻搜索 (Approximate Nearest Neighbor, ANN): 作为 ANN 算法的一种预过滤或加速手段,尤其是在内存受限的环境中。
- 数据去重: 快速识别重复或近乎重复的数据项。
总结表格:
| 向量类型 | 特点 | 典型生成方式/表示 | 优点 | 缺点 | 典型应用场景 |
|---|---|---|---|---|---|
| 密集型 | 大多数元素非零,浮点数 | 深度学习模型嵌入 | 捕捉语义信息,高召回率 | 存储和计算成本高 | 语义搜索、推荐系统、聚类、多模态搜索 |
| 稀疏型 | 大多数元素为零,通常为整数或浮点数 | 词袋、TF-IDF | 节省存储,适合精确关键词匹配,计算快 | 难以捕捉语义,召回率可能受限于关键词 | 全文搜索、词性匹配、混合检索 (RAG) |
| 二进制 | 元素只有 0 或 1 | 特征存在、LSH | 极度节省存储,计算速度极快(位运算) | 损失部分信息,精度可能低于密集向量 | 资源受限环境下的快速近似搜索、指纹识别、数据去重 |
Milvus 支持向量数据类型:FLOAT_VECTOR 表示密集向量,SPARSE_FLOAT_VECTOR 表示稀疏向量,BINARY_VECTOR 表示二进制向量
标量字段
标量字段存储原始的结构化值,通常称为元数据,如数字、字符串或日期。这些值可以与向量搜索结果一起返回,对于筛选和排序至关重要。它们允许你根据特定属性缩小搜索结果的范围,比如将文档限制在特定类别或定义的时间范围内。
Milvus 支持标量类型,如BOOL,INT8/16/32/64,FLOAT,DOUBLE,VARCHAR,JSON 和ARRAY ,用于存储和过滤非向量数据。这些类型提高了搜索操作的精度和定制化程度。
在模式设计中利用高级功能
在设计 Schema 时,仅仅使用支持的数据类型将数据映射到字段是不够的。必须全面了解字段之间的关系以及可用的配置策略。在设计阶段牢记关键功能,可确保 Schema 不仅能满足当前的数据处理要求,还具有可扩展性和适应性,以满足未来的需求。通过精心整合这些功能,您可以构建一个强大的数据架构,最大限度地发挥 Milvus 的功能,并支持您更广泛的数据策略和目标。以下是创建 Collections Schema 的主要功能概述:
主键
主键字段是 Schema 的基本组成部分,因为它能唯一标识 Collections 中的每个实体。必须定义主键。它必须是整数或字符串类型的标量字段,并标记为is_primary=True 。可选择为主键启用auto_id ,主键会自动分配整数,随着更多数据被采集到 Collections 中,整数也会随之增长。
有关详细信息,请参阅主字段和自动 ID。
分区
为了加快搜索速度,可以选择打开分区。通过为分区指定一个特定的标量字段,并在搜索过程中根据该字段指定过滤条件,可以有效地将搜索范围限制在相关的分区中。这种方法通过缩小搜索域,大大提高了检索操作的效率。
更多详情,请参阅使用 Partition Key。
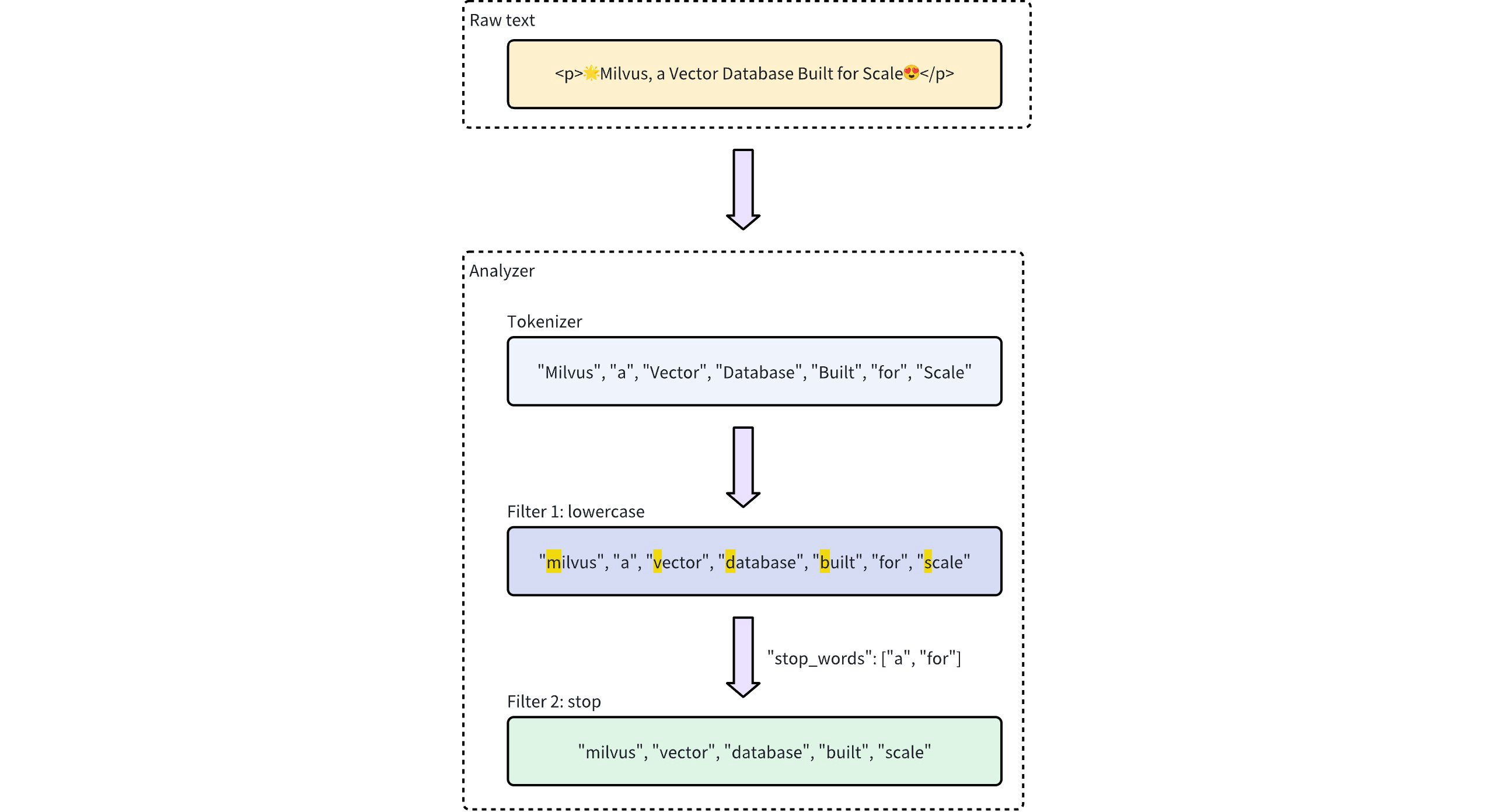
分析器
分析器是处理和转换文本数据的重要工具。它的主要功能是将原始文本转换为标记,并对其进行结构化处理,以便编制索引和进行检索。具体做法是对字符串进行标记化处理,去掉停顿词,并将单个词的词干转化为标记。
更多详情,请参阅分析器概述。
功能
Milvus 允许你定义内置函数作为 Schema 的一部分,以自动推导出某些字段。例如,您可以添加内置 BM25 函数,从VARCHAR 字段生成稀疏向量,以支持全文搜索。这些函数派生字段可简化预处理,并确保 Collections 保持自足和查询就绪。
更多详情,请参阅全文检索。
真实世界示例
在本节中,我们将概述上图所示多媒体文档搜索应用程序的 Schema 设计和代码示例。该 Schema 设计用于管理包含文章的数据集,数据映射到以下字段:
| 字段 | 数据源 | 搜索方法使用 | 主键 | 分区键 | 分析器 | 函数输入/输出 |
|---|---|---|---|---|---|---|
article_id (INT64) |
启用后自动生成auto_id |
使用 “获取 “进行查询 | Y | N | N | N |
标题 (VARCHAR) |
文章标题 | 文本匹配 | N | N | Y | N |
时间戳 (INT32) |
发布日期 | 按分区密钥过滤 | N | Y | N | N |
文本 (VARCHAR) |
文章原始文本 | 多向量混合搜索 | N | N | Y | 输入 |
文本密集向量 (FLOAT_VECTOR) |
由文本 Embeddings 模型生成的密集向量 | 基本向量搜索 | N | N | N | N |
文本稀疏向量 (SPARSE_FLOAT_VECTOR) |
由内置 BM25 函数自动生成的稀疏向量 | 全文搜索 | N | N | N | 输出 |
有关Schema 的更多信息以及添加各类字段的详细指导,请参阅Schema Explained。
初始化模式
首先,我们需要创建一个空模式。这一步为定义数据模型建立了基础结构。
1 | from pymilvus import MilvusClient |
添加字段
创建 Schema 后,下一步就是指定构成数据的字段。每个字段都与各自的数据类型和属性相关联。
1 | from pymilvus import DataType |
在本例中,为字段指定了以下属性:
- 主键:
article_id用作主键,可自动为输入实体分配主键。 - Partition Key:
timestamp被指定为分区键,允许通过分区进行过滤。这可能是 - 文本分析器:文本分析器应用于 2 个字符串字段
title和text,分别支持文本匹配和全文搜索。
添加功能
为增强数据查询功能,可在 Schema 中加入函数。例如,可以创建一个函数来处理与特定字段相关的数据。
1 | from pymilvus import Function, FunctionType |
本例在 Schema 中添加了一个内置 BM25 函数,利用text 字段作为输入,并将生成的稀疏向量存储在text_sparse_vector 字段中。